python3爬虫攻略(3):利用Fidder抓包!
2017-10-27 16:19
197 查看
上一篇我们使用了POST,其中涉及到表单数据的提交,那么表单数据的格式从哪里来呢?
当然是使用Fiddle抓包咯!
Fiddler安装包和switchyomega插件(如果失效的话只能自己去找咯!)
链接:http://pan.baidu.com/s/1eSCNWky 密码:dtc4
Fiddler用来抓取浏览器的http请求,而switchyomega则用来管理代理设置。
首先安装Fiddler,这里不做多的介绍。
然后讲一讲Fiddler设置
启动Fiddler,打开菜单栏中的 Tools >
Telerik Fiddler Options,打开“Fiddler Options”对话框。
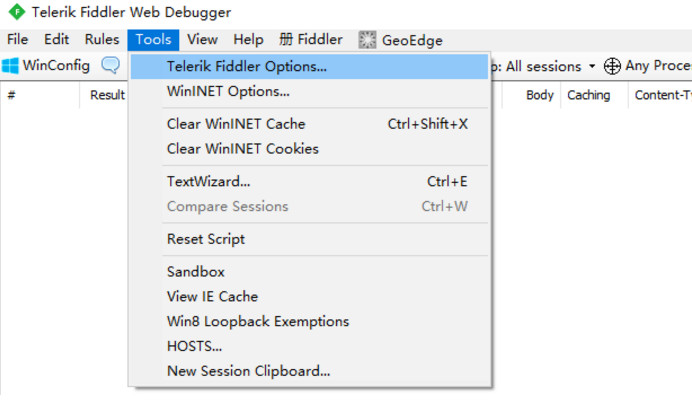
打开工具栏->Tools->Fiddler Options->HTTPS,
选中Capture HTTPS CONNECTs (捕捉HTTPS连接),
选中Decrypt HTTPS traffic(解密HTTPS通信)
另外我们要用Fiddler获取本机所有进程的HTTPS请求,所以中间的下拉菜单中选中...from all processes (从所有进程)
选中下方Ignore server certificate errors(忽略服务器证书错误)
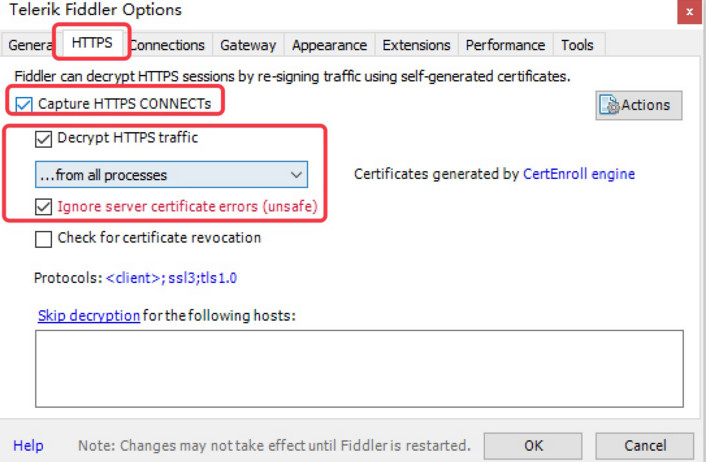
为
Fiddler 配置Windows信任这个根证书解决安全警告:Trust Root Certificate(受信任的根证书)
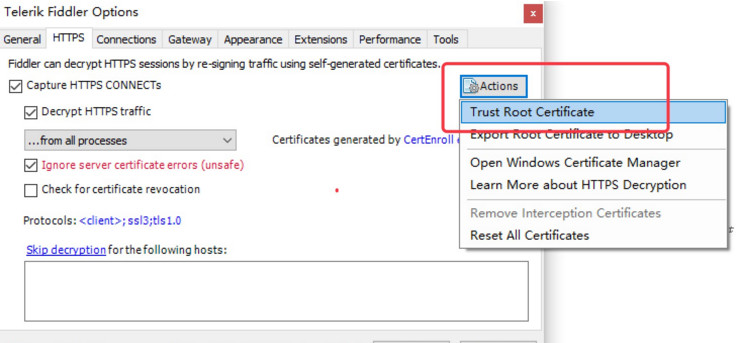
Fiddler 主菜单 Tools -> Fiddler Options…-> Connections
选中Allow remote computers to connect(允许远程连接)
Act as system proxy on startup(作为系统启动代理)
重启Fiddler,即可生效!
安装SwitchyOmega
,让fiddler能够捕捉chrome的会话
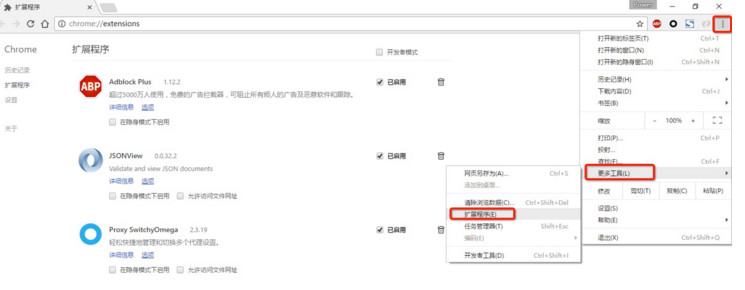
设置代理服务器为127.0.0.1:8888
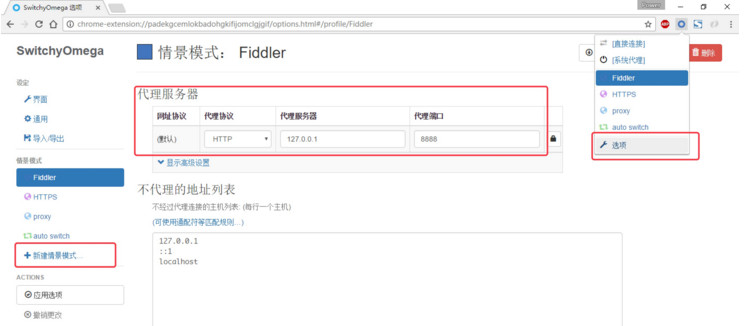
当我们在百度翻译中使用翻译时:
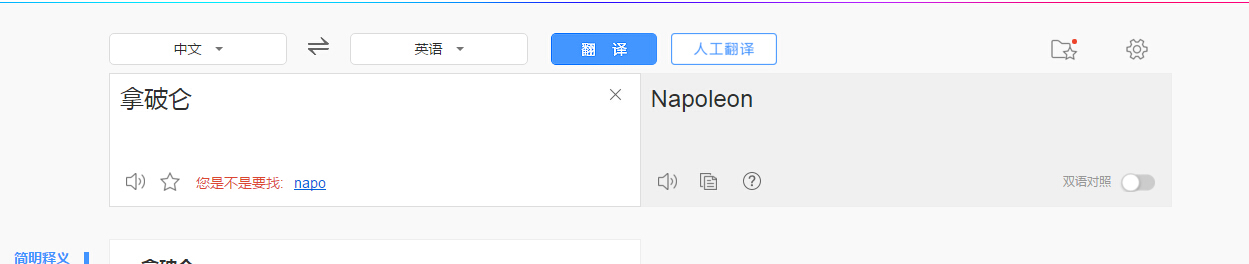
fiddler捕获的数据如下
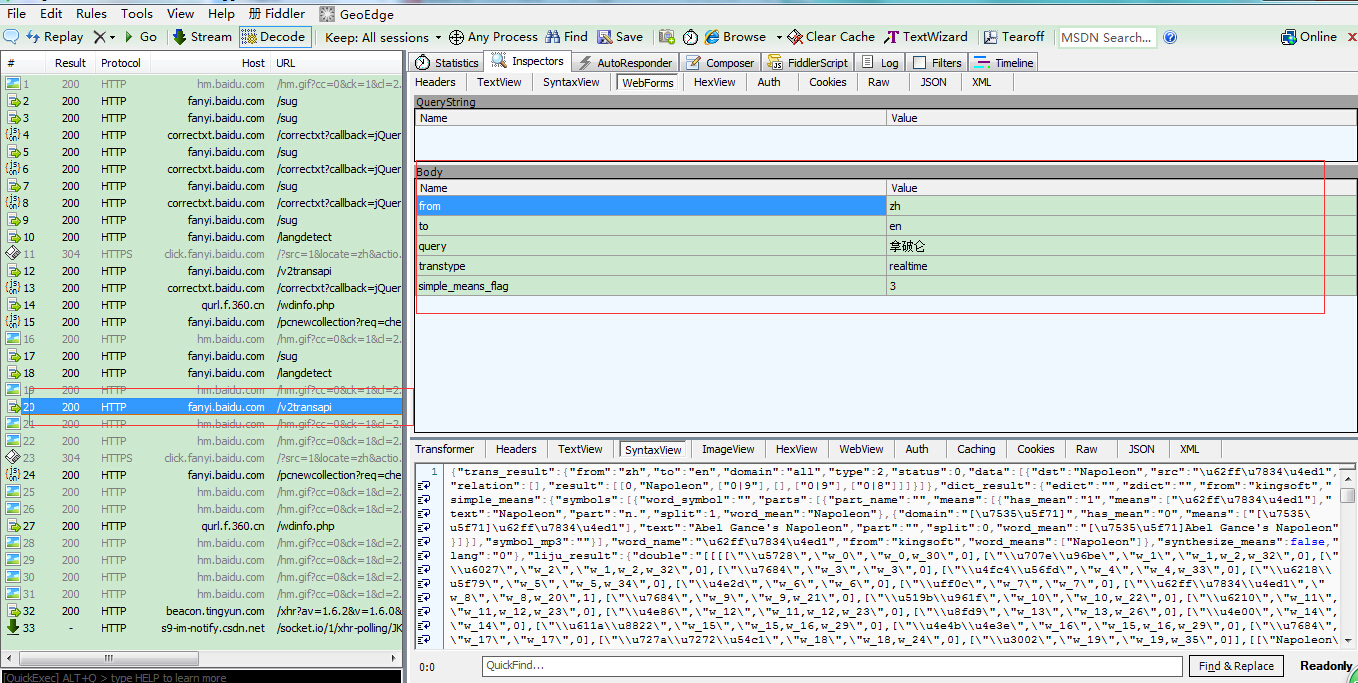
(注意那个表单是不是和我们前一次代码里写的一模一样!)
发送表单的请求地址
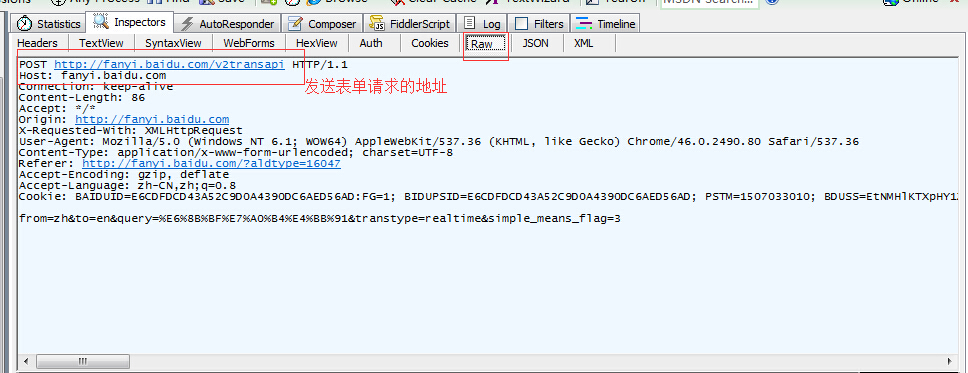
然后我们就可以利用这个表单和请求地址给百度翻译发送更多的请求,甚至可以实现一个自己的简单的翻译小程序!
未完待续…………………………
当然是使用Fiddle抓包咯!
Fiddler安装包和switchyomega插件(如果失效的话只能自己去找咯!)
链接:http://pan.baidu.com/s/1eSCNWky 密码:dtc4
Fiddler用来抓取浏览器的http请求,而switchyomega则用来管理代理设置。
首先安装Fiddler,这里不做多的介绍。
然后讲一讲Fiddler设置
启动Fiddler,打开菜单栏中的 Tools >
Telerik Fiddler Options,打开“Fiddler Options”对话框。
打开工具栏->Tools->Fiddler Options->HTTPS,
选中Capture HTTPS CONNECTs (捕捉HTTPS连接),
选中Decrypt HTTPS traffic(解密HTTPS通信)
另外我们要用Fiddler获取本机所有进程的HTTPS请求,所以中间的下拉菜单中选中...from all processes (从所有进程)
选中下方Ignore server certificate errors(忽略服务器证书错误)
为
Fiddler 配置Windows信任这个根证书解决安全警告:Trust Root Certificate(受信任的根证书)
Fiddler 主菜单 Tools -> Fiddler Options…-> Connections
选中Allow remote computers to connect(允许远程连接)
Act as system proxy on startup(作为系统启动代理)
重启Fiddler,即可生效!
安装SwitchyOmega
,让fiddler能够捕捉chrome的会话
设置代理服务器为127.0.0.1:8888
当我们在百度翻译中使用翻译时:
fiddler捕获的数据如下
(注意那个表单是不是和我们前一次代码里写的一模一样!)
发送表单的请求地址
然后我们就可以利用这个表单和请求地址给百度翻译发送更多的请求,甚至可以实现一个自己的简单的翻译小程序!
未完待续…………………………

相关文章推荐
- python3爬虫攻略(7):爬虫案例
- [Python/爬虫]利用xpath爬取豆瓣电影top250
- 利用python实现新浪微博爬虫 .
- python爬虫实战:利用scrapy,短短50行代码下载整站短视频
- Python3 爬虫快速入门攻略
- python利用新浪API实现数据的抓取\python微博数据爬虫
- python利用新浪API实现数据的抓取\python微博数据爬虫
- python爬虫入门(四)利用多线程爬虫
- python 爬虫利用webdriver 跳过登陆 进行小规模抓取信息
- 利用Python编写网络爬虫下载文章
- Python-利用beautifulsoup写个豆瓣热门图书爬虫
- 12Python爬虫---Fiddler抓包工具使用
- python爬虫由浅入深15---利用Redis+Flask来维护代理池和Cookie池
- 利用scrapy框架python爬虫初探
- 如何利用python爬虫技术将百度贴吧上面的帖子名称爬取下来
- Python爬虫(四)——模拟登录imooc实战(利用cookie)
- Python爬虫学习,记一次抓包获取js,从js函数中取数据的过程
- Python爬虫辅助利器PyQuery模块的安装使用攻略
- python3爬虫攻略(4):简单的翻译程序
- python爬虫之利用requests爬取墨迹天气