深度学习:长短期记忆模型LSTM
2017-10-27 10:14
525 查看
http://blog.csdn.net/pipisorry/article/details/78361778
lstm可以减少梯度消失:[RNN vs LSTM: Vanishing Gradients]
RNN与LSTM的区别:LSTM的分步解析
(1)RNN
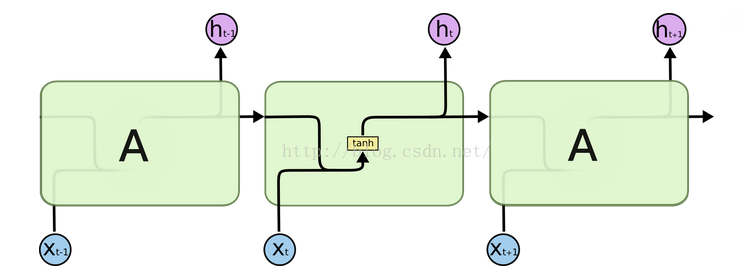
(2)LSTM
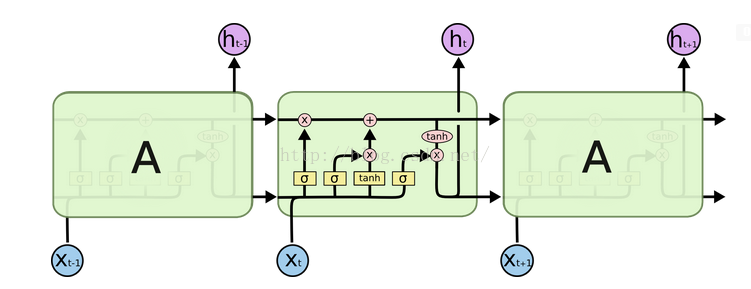
PS:
(1)部分图形含义如下:
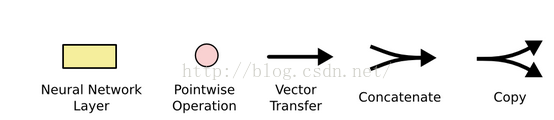
(2)RNN与LSTM最大的区别在于LSTM中最顶层多了一条名为“cell state”的信息传送带,其实也就是信息记忆的地方;
3.LSTM的核心思想:
(1)理解LSTM的核心是“cell state”,暂且名为细胞状态,也就是上述图中最顶的传送线,如下:
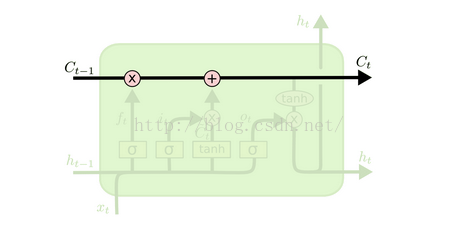
(2)cell state也可以理解为传送带,个人理解其实就是整个模型中的记忆空间,随着时间而变化的,当然,传送带本身是无法控制哪些信息是否被记忆,起控制作用的是下面将讲述的控制门(gate);
(3)控制门的结构如下:主要由一个sigmoid函数跟点乘操作组成;sigmoid函数的值为0-1之间,点乘操作决定多少信息可以传送过去,当为0时,不传送,当为1时,全部传送;
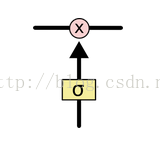
(4)LSTM中有3个控制门:输入门,输出门,记忆门;
4.LSTM工作原理:
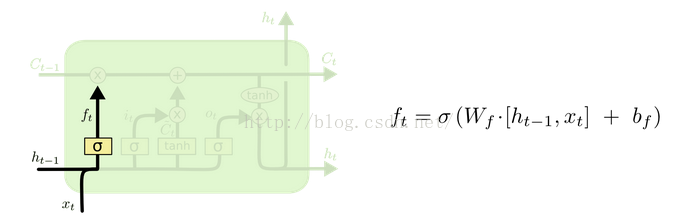
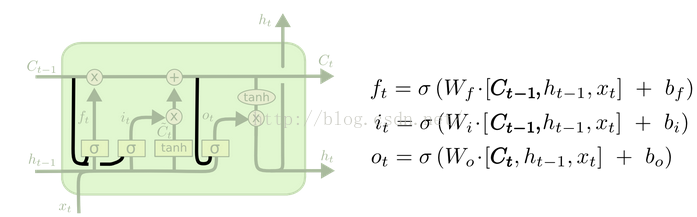
(1)forget gate:选择忘记过去某些信息:
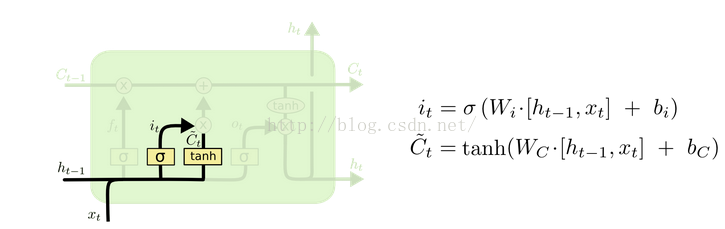
(2)input gate:记忆现在的某些信息:
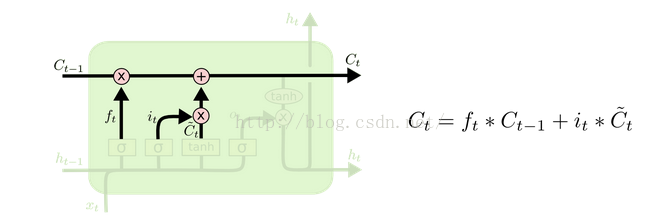
(3)将过去与现在的记忆进行合并:
(4)output gate:输出
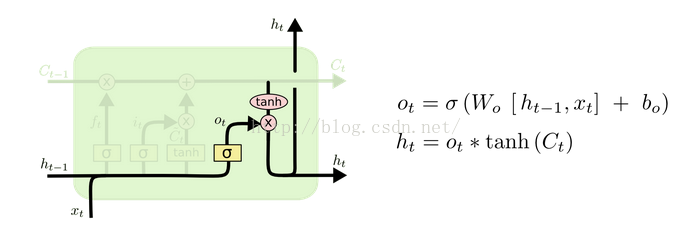
PS:以上是标准的LSTM的结构,实际应用中常常根据需要进行稍微改善;
5.LSTM的改善
(1)peephole connections:为每个门的输入增加一个cell state的信号
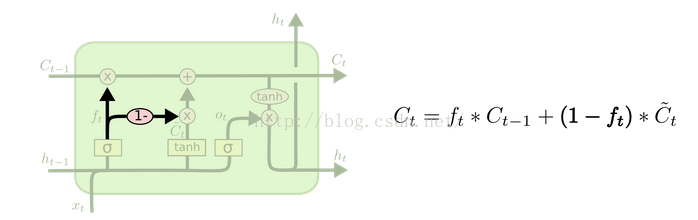
(2)coupled forget and input gates:合并忘记门与输入门
[Understanding LSTM Networks]
某小皮
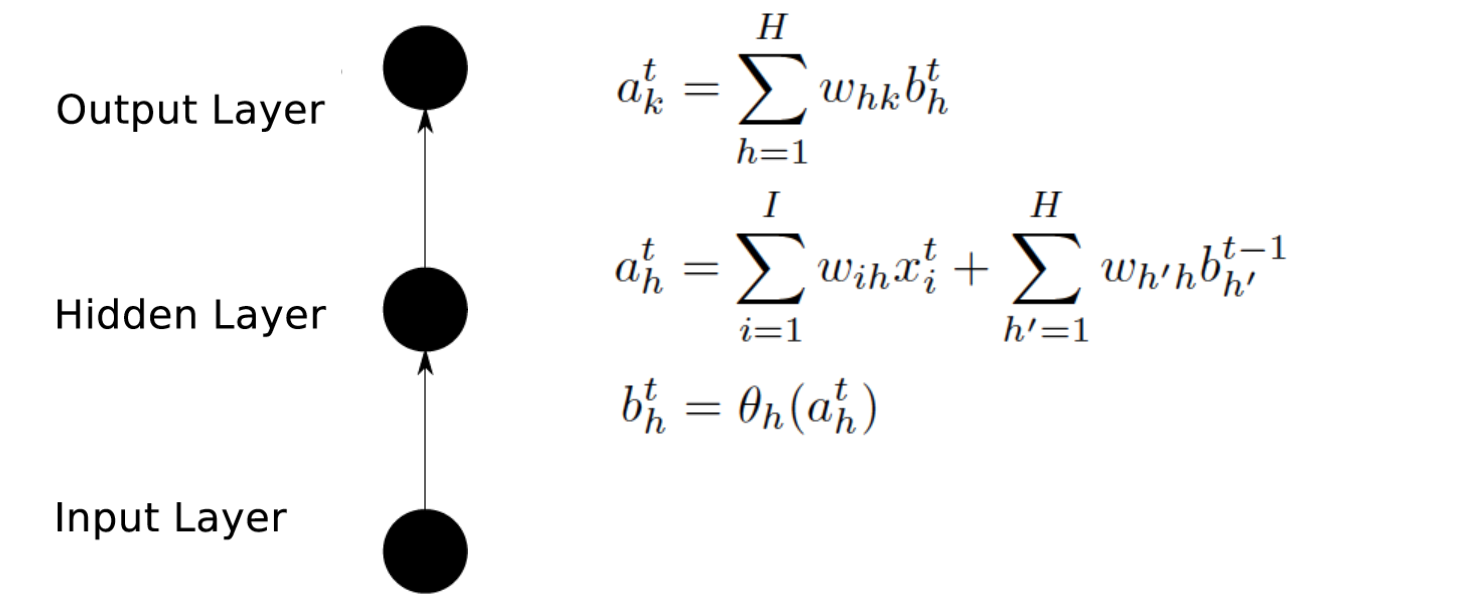

LSTM模型的思想是将RNN中的每个隐藏单元换成了具有记忆功能的cell,即把rnn的网络中的hidden layer小圆圈换成LSTM的block,就是所谓的LSTM了。
[深度学习:循环神经网络RNN ]
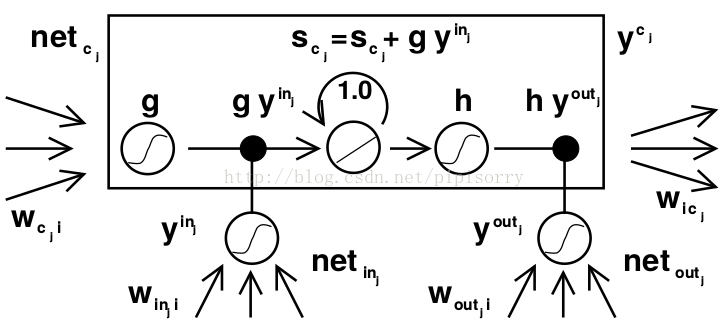
[Hochreiter, S., & Schmidhuber, J. Long short-term memory. Neural computation1997]

[LSTM memory cell as initially described in Hochreiter [Hochreiter and Schmidhuber, 1997]
现在常说的 LSTM 有 Forget Gate,是由 Gers 在"Learning to Forget: Continual Prediction with LSTM, 2000"中提出的改进版本。
后来,在"LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages, 2001"中 Gers 又加入了 Peephole Connection 的概念。

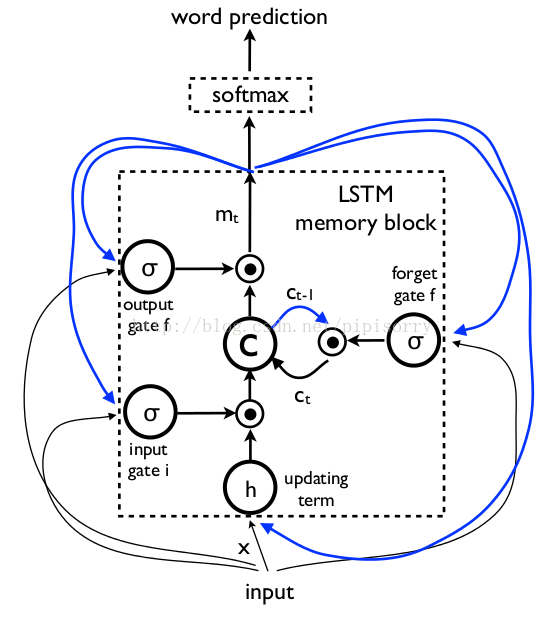

图1:LSTM memory cell with forget gate as described by Felix Gers et al.
图2:[Vinyals, et al. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. TPAMI2017]图中蓝色表示上一个时间步
图3:A. Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Textbook, Studies in Computational Intelligence, Springer, 2012.(图中的虚线为 Peephole Connection)
不同时间步展开

同一个 hidden layer 不同的 LSTMmemory block 之间的递归关系示意图。 这个图同一层的递归调用关系,实际上是不同timestep 之间的连接。展开为 RNN 的 unfold的示意图比较好理解。
每个cell的组成如下:(1)输入节点(gc):与RNN中的一样,接受上一个时刻点的隐藏节点的输出以及当前的输入作为输入,然后通过一个tanh的激活函数;lz:相当于原始RNN中的隐层。
(2)输入门(ic):起控制输入信息的作用,门的输入为上一个时刻点的隐藏节点的输出以及当前的输入,激活函数为sigmoid(原因为sigmoid的输出为0-1之间,将输入门的输出与输入节点的输出相乘可以起控制信息量的作用);control if it should read its input (input gate i).
(3)内部状态节点(sc):输入为被输入门过滤后的当前输入以及前一时间点的内部状态节点输出,如图中公式;Cell,就是我们的小本子(有个叫做state的参数东西来记事儿的)把事记上,所以LSTM引入一个核心元素就是Cell。
(4)忘记门(fc):起控制内部状态信息的作用,门的输入为上一个时刻点的隐藏节点的输出以及当前的输入,激活函数为sigmoid(原因为sigmoid的输出为0-1之间,将内部状态节点的输出与忘记门的输出相乘可以起控制信息量的作用);control whether to forget the current cell value (forget gate f).原始的LSTM在这个位置就是一个值1。
(5)输出门(oc):起控制输出信息的作用,门的输入为上一个时刻点的隐藏节点的输出以及当前的输入,激活函数为sigmoid(原因为sigmoid的输出为0-1之间,将输出门的输出与内部状态节点的输出相乘可以起控制信息量的作用);control whether to output the new cell value (output gate o).
Note: 3个控制门都是都是元素对应相乘,控制信息量。
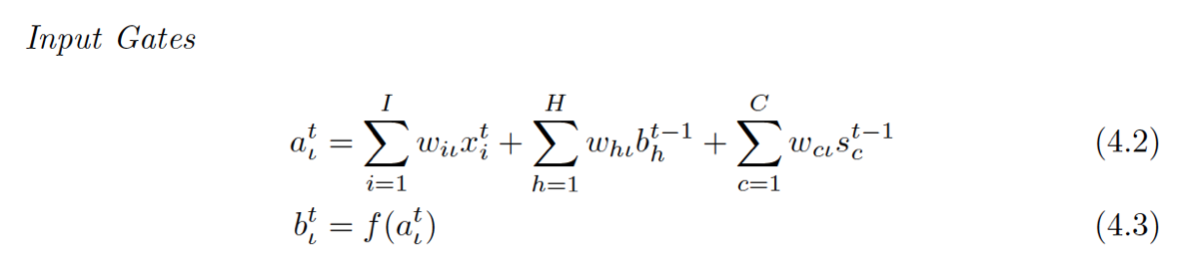
带H的是一个泛指,因为LSTM的一个重要特点是其灵活性,cell之间可以互联,hidden units之间可以互联,至于连不连都看你(所以你可能在不同地方看到的LSTM公式结构都不一样)所以这个H就是泛指这些连进来的东西,可以看成是从外面连进了的三条边的一部分。
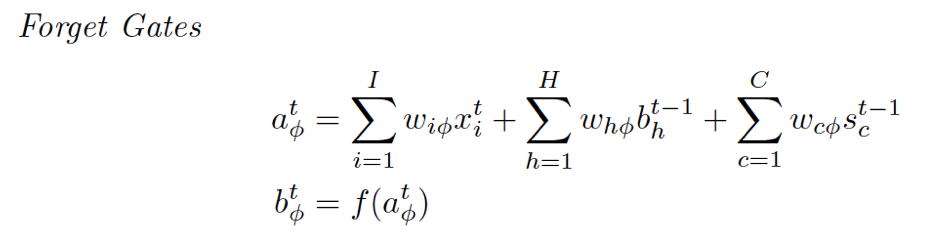
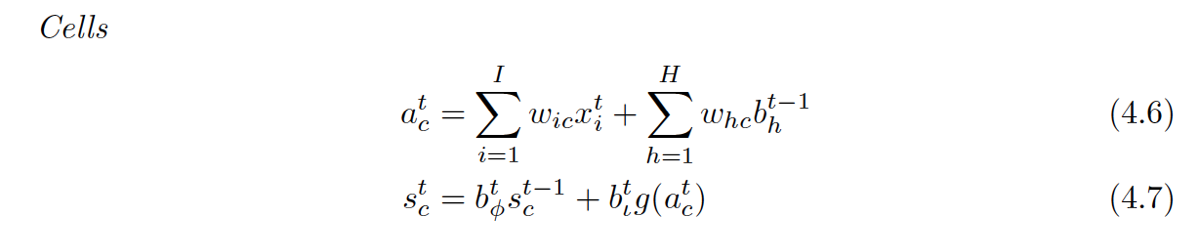
连到了Cell(这里的cell不是指中间那个Cell,而是最下面那个小圆圈,中间的Cell表示的其实是那个状态值S[c][t]):输入层的输入,泛指的输入。(这体现在4.6式中) 再看看中间的那个Cell状态值都有谁连过去了:这次好像不大一样,连过去的都是经过一个小黑点汇合的,从公式也能体现出来,分别是:ForgetGate*上一时间的状态 + InputGate*Cell激活后的值。
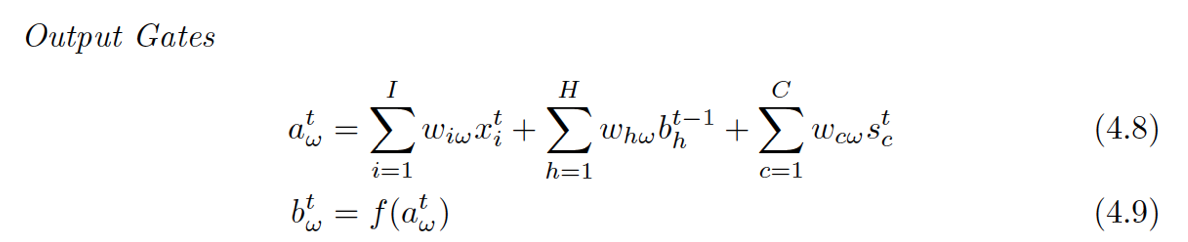
可以理解为在计算OG的时候,S[c][t]已经被计算出来了,所以就不用使用上一时间的状态值了。
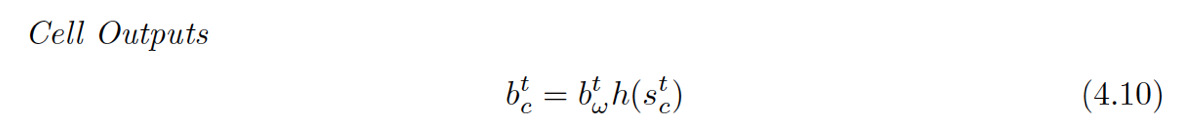
小黑点,用到了激活后的状态值和Output Gate的结果。
[RNN以及LSTM的介绍和公式梳理 ]
左图-矩阵表示
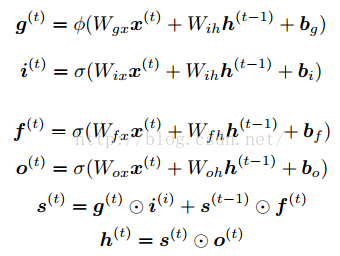
PS:公式1 中的Wih应改为Wgh;圆圈⊙表示矩阵元素对应相乘;一般σ is the sigmoid operator, φ is the tanh operator. 最后一步有时写成h = φ(s) ⊙ o,即在s外面加一层tanh。
Note: 实际计算中,g i f o计算的8个矩阵合并成一个提高计算效率。In practice, all eight weight matrices are concatenated into one large matrix for computational efficiency.
在"Framewise phoneme classification with bidirectional LSTM and other neural network architectures, 2005"中,作者提出了 Full Gradient BPTT 来训练 LSTM,也就是标准的 BPTT。这也是如今具有自动求导功能的开源框架们使用的方法。
某小皮

模仿 RNN,我们对 LSTM 计算

,有

公式里其余的项不重要,这里就用省略号代替了。可以看出当

时,就算其余项很小,梯度仍然可以很好地传导到上一个时刻,此时即使层数较深也不会发生 Gradient Vanish 的问题;当

时,即上一时刻的信号不影响到当前时刻,则此项也会为0;

在这里控制着梯度传导到上一时刻的衰减程度,与它 Forget Gate 的功能一致。
from: http://blog.csdn.net/pipisorry/article/details/78361778
ref: [Zachary C. Lipton:A Critical Review of Recurrent Neural Networks for Sequence Learning]*
[A. Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Textbook, Studies in Computational Intelligence, Springer, 2012.]
[当我们在谈论 Deep Learning:RNN 其常见架构]
lstm可以减少梯度消失:[RNN vs LSTM: Vanishing Gradients]
LSTM模型
长短期记忆模型(long-short term memory)是一种特殊的RNN模型,是为了解决RNN模型梯度弥散的问题而提出的;在传统的RNN中,训练算法使用的是BPTT,当时间比较长时,需要回传的残差会指数下降,导致网络权重更新缓慢,无法体现出RNN的长期记忆的效果,因此需要一个存储单元来存储记忆,因此LSTM模型被提出。RNN与LSTM的区别:LSTM的分步解析
(1)RNN(2)LSTM
PS:
(1)部分图形含义如下:
(2)RNN与LSTM最大的区别在于LSTM中最顶层多了一条名为“cell state”的信息传送带,其实也就是信息记忆的地方;
3.LSTM的核心思想:
(1)理解LSTM的核心是“cell state”,暂且名为细胞状态,也就是上述图中最顶的传送线,如下:
(2)cell state也可以理解为传送带,个人理解其实就是整个模型中的记忆空间,随着时间而变化的,当然,传送带本身是无法控制哪些信息是否被记忆,起控制作用的是下面将讲述的控制门(gate);
(3)控制门的结构如下:主要由一个sigmoid函数跟点乘操作组成;sigmoid函数的值为0-1之间,点乘操作决定多少信息可以传送过去,当为0时,不传送,当为1时,全部传送;
(4)LSTM中有3个控制门:输入门,输出门,记忆门;
4.LSTM工作原理:
(1)forget gate:选择忘记过去某些信息:
(2)input gate:记忆现在的某些信息:
(3)将过去与现在的记忆进行合并:
(4)output gate:输出
PS:以上是标准的LSTM的结构,实际应用中常常根据需要进行稍微改善;
5.LSTM的改善
(1)peephole connections:为每个门的输入增加一个cell state的信号
(2)coupled forget and input gates:合并忘记门与输入门
[Understanding LSTM Networks]
某小皮
LSTM模型推导
RNN网络
LSTM模型的思想是将RNN中的每个隐藏单元换成了具有记忆功能的cell,即把rnn的网络中的hidden layer小圆圈换成LSTM的block,就是所谓的LSTM了。
[深度学习:循环神经网络RNN ]
原始LSTM:不带忘记门的lstm block
[Hochreiter, S., & Schmidhuber, J. Long short-term memory. Neural computation1997]
[LSTM memory cell as initially described in Hochreiter [Hochreiter and Schmidhuber, 1997]
现在常说的 LSTM 有 Forget Gate,是由 Gers 在"Learning to Forget: Continual Prediction with LSTM, 2000"中提出的改进版本。
后来,在"LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages, 2001"中 Gers 又加入了 Peephole Connection 的概念。
LSTM的block(隐层单元)表示
看到有多种不同等价的图表示:图1:LSTM memory cell with forget gate as described by Felix Gers et al.
图2:[Vinyals, et al. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. TPAMI2017]图中蓝色表示上一个时间步
图3:A. Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Textbook, Studies in Computational Intelligence, Springer, 2012.(图中的虚线为 Peephole Connection)
不同时间步展开
同一个 hidden layer 不同的 LSTMmemory block 之间的递归关系示意图。 这个图同一层的递归调用关系,实际上是不同timestep 之间的连接。展开为 RNN 的 unfold的示意图比较好理解。
每个cell的组成如下:(1)输入节点(gc):与RNN中的一样,接受上一个时刻点的隐藏节点的输出以及当前的输入作为输入,然后通过一个tanh的激活函数;lz:相当于原始RNN中的隐层。
(2)输入门(ic):起控制输入信息的作用,门的输入为上一个时刻点的隐藏节点的输出以及当前的输入,激活函数为sigmoid(原因为sigmoid的输出为0-1之间,将输入门的输出与输入节点的输出相乘可以起控制信息量的作用);control if it should read its input (input gate i).
(3)内部状态节点(sc):输入为被输入门过滤后的当前输入以及前一时间点的内部状态节点输出,如图中公式;Cell,就是我们的小本子(有个叫做state的参数东西来记事儿的)把事记上,所以LSTM引入一个核心元素就是Cell。
(4)忘记门(fc):起控制内部状态信息的作用,门的输入为上一个时刻点的隐藏节点的输出以及当前的输入,激活函数为sigmoid(原因为sigmoid的输出为0-1之间,将内部状态节点的输出与忘记门的输出相乘可以起控制信息量的作用);control whether to forget the current cell value (forget gate f).原始的LSTM在这个位置就是一个值1。
(5)输出门(oc):起控制输出信息的作用,门的输入为上一个时刻点的隐藏节点的输出以及当前的输入,激活函数为sigmoid(原因为sigmoid的输出为0-1之间,将输出门的输出与内部状态节点的输出相乘可以起控制信息量的作用);control whether to output the new cell value (output gate o).
Note: 3个控制门都是都是元素对应相乘,控制信息量。
LSTM层的计算
右图-公式表示带H的是一个泛指,因为LSTM的一个重要特点是其灵活性,cell之间可以互联,hidden units之间可以互联,至于连不连都看你(所以你可能在不同地方看到的LSTM公式结构都不一样)所以这个H就是泛指这些连进来的东西,可以看成是从外面连进了的三条边的一部分。
连到了Cell(这里的cell不是指中间那个Cell,而是最下面那个小圆圈,中间的Cell表示的其实是那个状态值S[c][t]):输入层的输入,泛指的输入。(这体现在4.6式中) 再看看中间的那个Cell状态值都有谁连过去了:这次好像不大一样,连过去的都是经过一个小黑点汇合的,从公式也能体现出来,分别是:ForgetGate*上一时间的状态 + InputGate*Cell激活后的值。
可以理解为在计算OG的时候,S[c][t]已经被计算出来了,所以就不用使用上一时间的状态值了。
小黑点,用到了激活后的状态值和Output Gate的结果。
[RNN以及LSTM的介绍和公式梳理 ]
左图-矩阵表示
PS:公式1 中的Wih应改为Wgh;圆圈⊙表示矩阵元素对应相乘;一般σ is the sigmoid operator, φ is the tanh operator. 最后一步有时写成h = φ(s) ⊙ o,即在s外面加一层tanh。
Note: 实际计算中,g i f o计算的8个矩阵合并成一个提高计算效率。In practice, all eight weight matrices are concatenated into one large matrix for computational efficiency.
LSTM的后向传导:学习
最初 LSTM 被提出时,其训练的方式为“Truncated BPTT”。大致的意思为,只有 Cell 的状态会 BP 多次,而其他部分的梯度会被截断,不 BP 到上一个时刻的 Memory Block。当然,这种方法现在也不使用了。在"Framewise phoneme classification with bidirectional LSTM and other neural network architectures, 2005"中,作者提出了 Full Gradient BPTT 来训练 LSTM,也就是标准的 BPTT。这也是如今具有自动求导功能的开源框架们使用的方法。
某小皮
LSTM模型的评价
为什么 LSTM 能有效避免 Gradient Vanish?
对于 LSTM,有如下公式模仿 RNN,我们对 LSTM 计算
,有
公式里其余的项不重要,这里就用省略号代替了。可以看出当
时,就算其余项很小,梯度仍然可以很好地传导到上一个时刻,此时即使层数较深也不会发生 Gradient Vanish 的问题;当
时,即上一时刻的信号不影响到当前时刻,则此项也会为0;
在这里控制着梯度传导到上一时刻的衰减程度,与它 Forget Gate 的功能一致。
from: http://blog.csdn.net/pipisorry/article/details/78361778
ref: [Zachary C. Lipton:A Critical Review of Recurrent Neural Networks for Sequence Learning]*
[A. Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Textbook, Studies in Computational Intelligence, Springer, 2012.]
[当我们在谈论 Deep Learning:RNN 其常见架构]

相关文章推荐
- 深度学习:长短期记忆模型LSTM的变体和拓展
- 深度学习笔记(八)LSTM长短期记忆网络
- 应用于深度学习和自然语言处理的注意机制和记忆模型
- 应用于深度学习和自然语言处理的注意机制和记忆模型
- RNN LSTM与GRU深度学习模型学习笔记
- 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
- 如何判断LSTM模型中的过拟合和欠拟合 By 机器之心2017年10月02日 11:09 判断长短期记忆模型在序列预测问题上是否表现良好可能是一件困难的事。也许你会得到一个不错的模型技术得分,但了解
- 理解长短期记忆(Long Short Term Memory, LSTM)模型(colah 原文翻译)
- 深度学习与自然语言处理(7)_斯坦福cs224d 语言模型,RNN,LSTM与GRU
- 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
- 深度学习——循环神经网络/递归神经网络(RNN)及其改进的长短时记忆网络(LSTM)
- 使用深度学习检测DGA(域名生成算法)——LSTM的输入数据本质上还是词袋模型
- 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
- TensorFlow实现经典深度学习网络(6):TensorFlow实现基于LSTM的语言模型
- 深度学习笔记八:长短时记忆网络LSTM(基本理论)
- 深度学习和自然语言处理的注意机制和记忆模型
- 【深度学习】RNN(循环神经网络)之LSTM(长短时记忆)
- 深度学习之六,基于RNN(GRU,LSTM)的语言模型分析与theano代码实现
- 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
- LSTM模型预测效果惊人的好,深度学习做股票预测靠谱吗?