python正则表达式基础以及案例
2017-10-27 00:14
253 查看
<一>正则表达式基础
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
在python中要使用正则需要导入re包
1.写个简单
python 爬虫的时候,为什么正则匹配的字符串前面加个 r??
答:加r之后不会对加r的字符串进行转义
例如:
print("a\"b\"c")
print(r"a\"b\"c")结果:
a"b"c
a\"b\"c
2.正则表达式规则
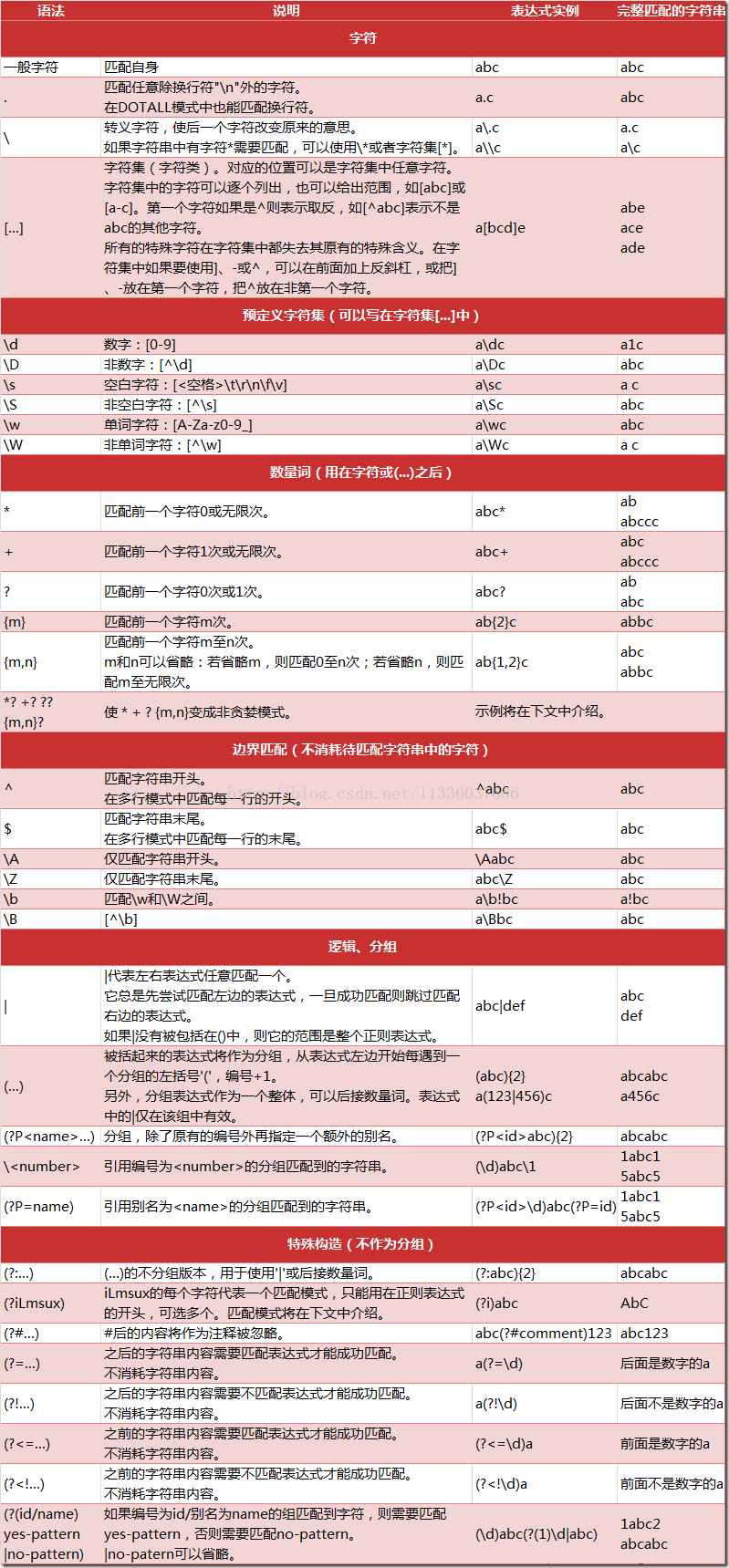
通过
最后使用
4.正则表达式修饰符
- 可选标志
5.常用函数
1.compile函数
a. 作用:compile函数用于编译正则表达式,生成一个pattern对象
例如:
#re.S全局匹配
#使用正则表达式匹配需要获取的数据
pattern = re.compile('<div\sclass="f18 mb20">(.*?)</div>',re.S)
b. pattern对象的一些常用方法有:
match 方法:从起始位置开始查找,一次匹配
search 方法:从任何位置开始查找,一次匹配
findall 方法:全部匹配,返回列表
finditer 方法:全部匹配,返回迭代器
split 方法:分割字符串,返回列表
sub 方法:替换
2.match函数
a.基础语法:re.match(pattern, string, flags = 0)
b.参数描述:
pattern: 这是要匹配的正则表达式。
string: [b]这是字符串,它将被搜索用于匹配字符串开头的模式[/b]
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
c.匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
3.search函数
a. 基础语法:re.search(pattern, string, flags=0)
b. 参数描述:
pattern: 匹配的正则表达式
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
c. 匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
d. re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
4.findall函数
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
a.基础语法:findall(string, pos, endpos)
string:待匹配的字符串
pos:起始位置
endpos:结束位置
b.返回规则
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
5.sub函数
Python
的 re 模块提供了re.sub用于替换字符串中的匹配项。
a.基础语法:re.sub(pattern,
repl, string, count=0, flags=0)
b.参数描述:
pattern:正则中的模式字符串。
repl:替换的字符串,也可为一个函数。
string: 要被查找替换的原始字符串。
count:模式匹配后替换的最大次数,默认
0 表示替换所有的匹配。
<二>案例(利用爬虫爬取内涵段子里面的信息)
# _*_ coding:utf-8 _*_
#爬取内涵段子内的段子内容
import re
import urllib2
#创建一个爬虫类
class Spider(object):
#初始化爬虫数据
def __init__(self):
#初始化页面1
self.page = 1
def loginPage(self):
"""
下载页面
"""
print "正在加载页面..."
print "加载第" + str(self.page) + "页"
url = "http://www.isocialkey.com/article/list_5_" + str(self.page) + ".html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
html = response.read()
print "加载页面成功..."
#decode解码 encode编码
return html.decode("gbk").encode("utf-8")
def delPage(self,html):
"""
处理页面
"""
print "正在处理页面..."
#re.S全局匹配
#使用正则表达式匹配需要获取的数据
pattern = re.compile('<div\sclass="f18 mb20">(.*?)</div>',re.S)
#用findall获取所有匹配到的数据列表
pageList = pattern.findall(html)
print "页面处理成功,正在保存..."
#遍历列表,并进行格式处理,然后将其保存
for i in pageList:
#格式处理
if i.find("<p>") > -1 or i.find("</p>") > -1:
continue
i = i.replace("<p>","").replace("</p>","").replace("<br />","").replace("…","...").replace("”","\"").replace("“","\"").replace(""","\"")
#保存
self.writePage(i.strip()+"\n\n==>>>>>\n")
print "保存完毕..."
def writePage(self,item):
#保存操作
with open("page/chinese.txt","a") as f:
f.write(item)
def conSpider(self):
#爬虫控制器,执行循环一共爬取506页的数据
for i in range(506):
#调用加载页面方法
html = self.loginPage()
#调用处理页面方法
self.delPage(html)
#每爬取完一页的数据后页数加1
self.page += 1
#实例化爬虫类
spider = Spider()
#执行爬虫控制器
spider.conSpider()
结果:
较为完整的介绍正则表达式用法:菜鸟教程
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
在python中要使用正则需要导入re包
1.写个简单
python 爬虫的时候,为什么正则匹配的字符串前面加个 r??
答:加r之后不会对加r的字符串进行转义
例如:
print("a\"b\"c")
print(r"a\"b\"c")结果:
a"b"c
a\"b\"c
2.正则表达式规则
3. re 模块的一般使用步骤如下:
使用compile()函数将正则表达式的字符串形式编译为一个
Pattern对象
通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。
最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
4.正则表达式修饰符
- 可选标志
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
1.compile函数
a. 作用:compile函数用于编译正则表达式,生成一个pattern对象
例如:
#re.S全局匹配
#使用正则表达式匹配需要获取的数据
pattern = re.compile('<div\sclass="f18 mb20">(.*?)</div>',re.S)
b. pattern对象的一些常用方法有:
match 方法:从起始位置开始查找,一次匹配
search 方法:从任何位置开始查找,一次匹配
findall 方法:全部匹配,返回列表
finditer 方法:全部匹配,返回迭代器
split 方法:分割字符串,返回列表
sub 方法:替换
2.match函数
a.基础语法:re.match(pattern, string, flags = 0)
b.参数描述:
pattern: 这是要匹配的正则表达式。
string: [b]这是字符串,它将被搜索用于匹配字符串开头的模式[/b]
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
c.匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
3.search函数
a. 基础语法:re.search(pattern, string, flags=0)
b. 参数描述:
pattern: 匹配的正则表达式
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
c. 匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
d. re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
4.findall函数
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
a.基础语法:findall(string, pos, endpos)
string:待匹配的字符串
pos:起始位置
endpos:结束位置
b.返回规则
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
5.sub函数
Python
的 re 模块提供了re.sub用于替换字符串中的匹配项。
a.基础语法:re.sub(pattern,
repl, string, count=0, flags=0)
b.参数描述:
pattern:正则中的模式字符串。
repl:替换的字符串,也可为一个函数。
string: 要被查找替换的原始字符串。
count:模式匹配后替换的最大次数,默认
0 表示替换所有的匹配。
<二>案例(利用爬虫爬取内涵段子里面的信息)
# _*_ coding:utf-8 _*_
#爬取内涵段子内的段子内容
import re
import urllib2
#创建一个爬虫类
class Spider(object):
#初始化爬虫数据
def __init__(self):
#初始化页面1
self.page = 1
def loginPage(self):
"""
下载页面
"""
print "正在加载页面..."
print "加载第" + str(self.page) + "页"
url = "http://www.isocialkey.com/article/list_5_" + str(self.page) + ".html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
html = response.read()
print "加载页面成功..."
#decode解码 encode编码
return html.decode("gbk").encode("utf-8")
def delPage(self,html):
"""
处理页面
"""
print "正在处理页面..."
#re.S全局匹配
#使用正则表达式匹配需要获取的数据
pattern = re.compile('<div\sclass="f18 mb20">(.*?)</div>',re.S)
#用findall获取所有匹配到的数据列表
pageList = pattern.findall(html)
print "页面处理成功,正在保存..."
#遍历列表,并进行格式处理,然后将其保存
for i in pageList:
#格式处理
if i.find("<p>") > -1 or i.find("</p>") > -1:
continue
i = i.replace("<p>","").replace("</p>","").replace("<br />","").replace("…","...").replace("”","\"").replace("“","\"").replace(""","\"")
#保存
self.writePage(i.strip()+"\n\n==>>>>>\n")
print "保存完毕..."
def writePage(self,item):
#保存操作
with open("page/chinese.txt","a") as f:
f.write(item)
def conSpider(self):
#爬虫控制器,执行循环一共爬取506页的数据
for i in range(506):
#调用加载页面方法
html = self.loginPage()
#调用处理页面方法
self.delPage(html)
#每爬取完一页的数据后页数加1
self.page += 1
#实例化爬虫类
spider = Spider()
#执行爬虫控制器
spider.conSpider()
结果:
较为完整的介绍正则表达式用法:菜鸟教程
式

相关文章推荐
- Python基础--正则表达式基本语法以及re模块
- Python基础教程之正则表达式基本语法以及re模块
- Python 正则表达式---概念基础,匹配过程,表达式元字符和语法以及实例
- Python基础--正则表达式基本语法以及re模块
- Python基础教程之正则表达式基本语法以及re模块
- Python编程基础之十四正则表达式
- 【Python基础学习篇十】Python正则表达式(2015-01-01)
- python爬虫基础知识(二)--正则表达式
- Python正则表达式之基础篇
- Python基础之正则表达式
- python基础之 re(正则表达式)模块学习
- python基础===正则表达式,常用函数re.split和re.sub
- python基础知识——正则表达式,
- Python爬虫基础-5(正则表达式)
- Python基础_正则表达式学习一
- Python正则表达式教程之一:基础篇
- 正则表达式 ——python 基础
- [转]validation验证控件案例以及正则表达式中几个特殊符号的说明!
- Python基础(十)——正则表达式
- Java基础知识强化75:正则表达式之分割功能(字符串中的数字排序案例)