基于Python的分布式高可用扩展引擎Ray 0.2.0发布
2017-10-21 11:37
549 查看
翻译自https://ray-project.github.io/2017/09/30/ray-0.2-release.html
Ray是为python机器学习、深度学习而开发的高可用、高性能的分布式框架,目前已经发布到0.2.0版本(注:2017-11-1已经发布了0.2.2),下面是版本发布说明
我们很高兴发布Ray 0.2版本发布,本次发布包括以下信息:
* Plasma 对象存储性能的重大提升
* 增加基于Jpuyter 的web UI页面
* 开始可扩展增强学习库的开发
* 行为容错处理
在0.2版本中,我们提高了写对象的吞吐量至15Gb/s(从单一客户端写),实现这种性能要求需要巨大的页面(减少TLB缓存未命中),可以看这里的指导意见。
对象被写入速度是是一个关键指标,比如,他是A3C和许多其他算法的瓶颈。
你可以通过下面的方法来测试性能瓶颈
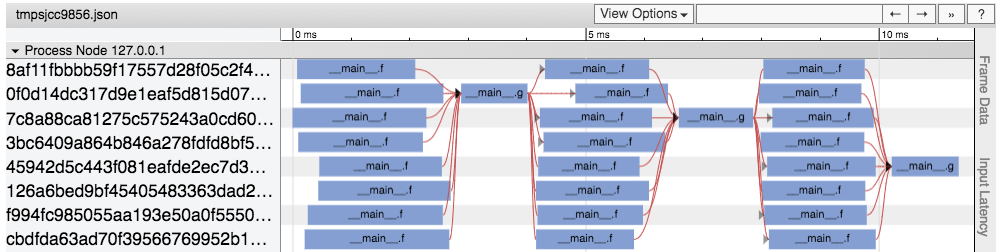
这种类型的可视化可以很方便查看问题、任务,以及任务的平衡情况。
上面的可视化效果中的任务可以在通过下面的脚本生成出来
* 近端优化(PPO)
* 深度学习(QDN)
* 异步优化(A3C)
* 进化策略(ES)
其中DQN、A3C、ES都是基于OpenAI baselines,可以通过下面的方法来使用
这个使用PPO算法来训练一个策略来控制CartPole环境中的客户端。
在亚马逊云上的一组15个m4.16xlarge实例和一个p2.16xlarge实例上利用运行这个(在Humanoid-v1环境训练行走机器人)应用,我们在35分钟内获得超过6000的奖励。推出的产品在512个物理内核上并行化,策略优化在6个GPU上并行化。此实验的相关超参数在 这里。
这个RL库还在开发中,我们正在寻找包括更多的算法实现。
Ray是为python机器学习、深度学习而开发的高可用、高性能的分布式框架,目前已经发布到0.2.0版本(注:2017-11-1已经发布了0.2.2),下面是版本发布说明
我们很高兴发布Ray 0.2版本发布,本次发布包括以下信息:
* Plasma 对象存储性能的重大提升
* 增加基于Jpuyter 的web UI页面
* 开始可扩展增强学习库的开发
* 行为容错处理
Plasma
自从上次发布后,Plasma对象已经从Ray项目的基础代码移出,Plasma已经成为Apache Arrow项目的一部分,所以他可以在其他大型高可用型内存计算项目单独使用。此外,我们的基于Arrow的序列化库已经移动到pyarrow了。在0.2版本中,我们提高了写对象的吞吐量至15Gb/s(从单一客户端写),实现这种性能要求需要巨大的页面(减少TLB缓存未命中),可以看这里的指导意见。
对象被写入速度是是一个关键指标,比如,他是A3C和许多其他算法的瓶颈。
你可以通过下面的方法来测试性能瓶颈
import numpy as np import ray ray.init() x = np.ones(10 ** 9, dtype=np.uint8) # Measure the time required to write 1GB to the Plasma store. %time x_id = ray.put(x)
Web UI
我们基于Jupyter-notebook建立了web UI框架,方便立即和调试应用的性能。查看如何使用这个框架,这个UI包括一个基于chrome tracing的任务时间线,我们可以看到任务在哪执行,任务执行了多久,还有任务之间的依赖情况,下面是任务的可视化样例。这种类型的可视化可以很方便查看问题、任务,以及任务的平衡情况。
上面的可视化效果中的任务可以在通过下面的脚本生成出来
import ray import time ray.init() @ray.remote def f(x): time.sleep(0.001) return 1 @ray.remote def g(*ys): return 1 time.sleep(1) x = 1 for _ in range(3): ys = [f.remote(x) for _ in range(8)] x = g.remote(*ys)
RLlib
我们开始开发基于Ray的可扩展增强学习库,到目前为止,它包括如下算法:* 近端优化(PPO)
* 深度学习(QDN)
* 异步优化(A3C)
* 进化策略(ES)
其中DQN、A3C、ES都是基于OpenAI baselines,可以通过下面的方法来使用
# On a single machine. python ray/python/ray/rllib/train.py --alg=PPO \ --env=CartPole-v0 # On a cluster. python ray/python/ray/rllib/train.py --alg=PPO \ --env=CartPole-v0 \ --redis-address=<head-node-ip>:6379
这个使用PPO算法来训练一个策略来控制CartPole环境中的客户端。
在亚马逊云上的一组15个m4.16xlarge实例和一个p2.16xlarge实例上利用运行这个(在Humanoid-v1环境训练行走机器人)应用,我们在35分钟内获得超过6000的奖励。推出的产品在512个物理内核上并行化,策略优化在6个GPU上并行化。此实验的相关超参数在 这里。
这个RL库还在开发中,我们正在寻找包括更多的算法实现。
行为容错
我们已经为actor启用了容错功能,如下所示。如果机器发生故障,则在其他机器上重新创建在该机器上运行的行为,并且重播先前在这些演员上执行的任务,以重新创建故障机器的状态。我们正在努力通过使检查点恢复行为状态来提高恢复速度。请参阅Ray中容错的概述。
相关文章推荐
- 基于Python的分布式高可用扩展引擎Ray 0.3.0发布
- python发布及调用基于SOAP的webservice
- Kafka是一种分布式的,基于发布/订阅的消息系统
- 分布式图处理引擎Graph Engine 1.0 预览版正式发布
- 基于 MySQL的高可用可扩展架构探讨
- 构建高可用、可扩展、分布式 Linux 操作系统课程目录
- 将Python代码发布到PyPi,使他人可用pip安装
- 基于Python及Wx的离线Blog发布工具Zoundry Raven
- 分布式系统本质:高吞吐、高可用、可扩展
- 基于Python使用scrapy-redis框架实现分布式爬虫 注
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
- 高可用、可扩展mysql数据库分布式集群架构
- [ lucene扩展 ] 基于lucene实现自己的推荐引擎(转)
- 【语言处理与Python】9.2处理特征结构\9.3扩展基于特征的文法
- 分布式切图瓦片格式扩展及服务发布
- 基于MySQL的高可用可扩展架构探讨
- 【HIMI转载推荐之三】基于Cocos2dx引擎UI扩展引擎包[cocos2d-x-3c]
- [转]发布基于T4模板引擎的代码生成器[Kalman Studio]
- Macaca+HTMLTestRunner测试报告模式修改,基于python unittest 测试框架扩展
- 扩展:基于Python操作ElasticSearch