一张思维导图,让正则表达式不再难懂
2017-10-16 07:15
232 查看
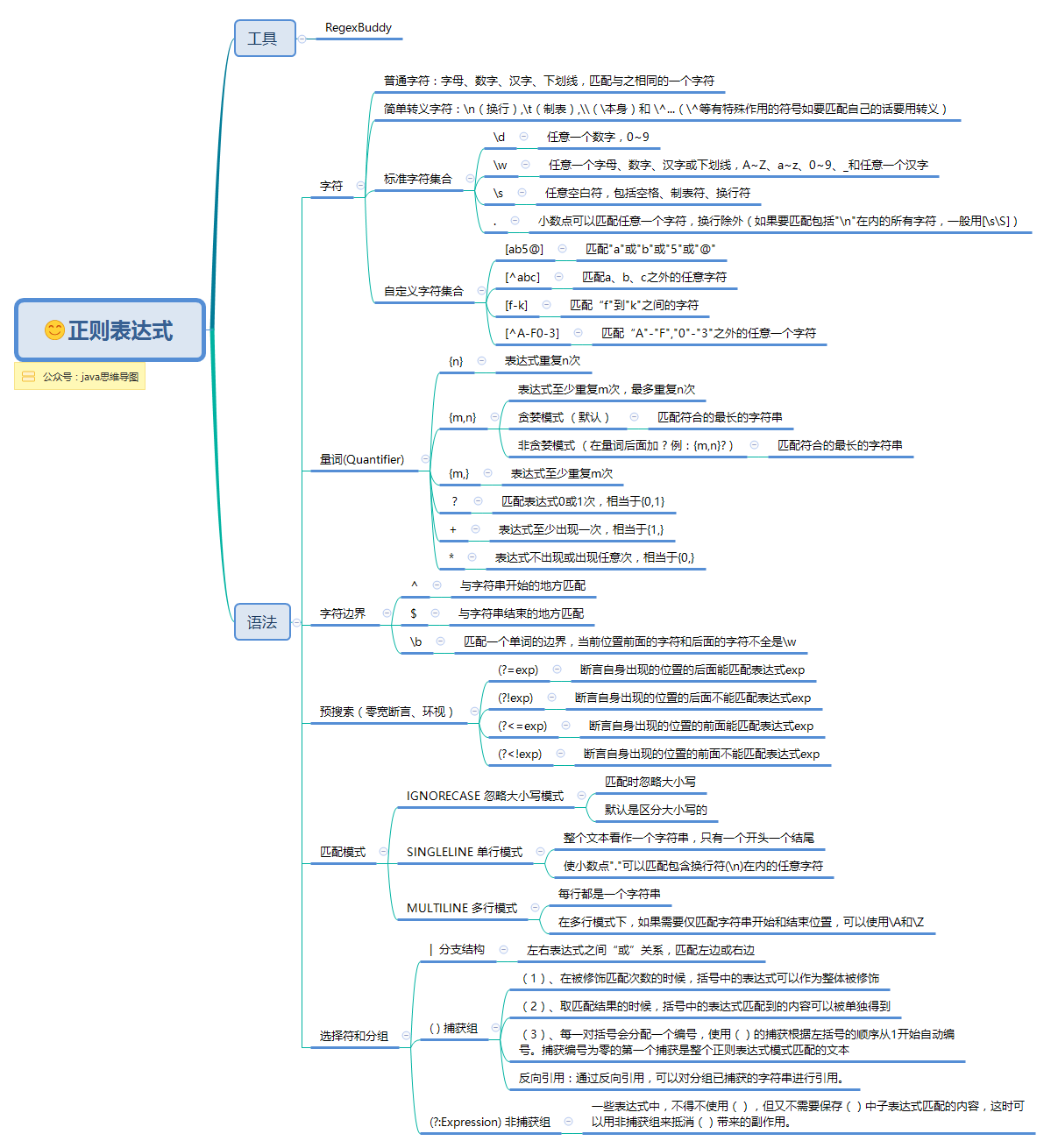
- 语法结构
- 字符 普通字符:字母、数字、汉字、下划线,匹配与之相同的一个字符
- 简单转义字符:\n(换行),\t(制表),\\(\本身)和 \^...(\^等有特殊作用的符号如要匹配自己的话要用转义)
- 标准字符集合
注意区分大小写,大写是相反的意思,匹配相反是不匹配 \d
任意一个数字,0~9 - \w
任意一个字母、数字、汉字或下划线,A~Z、a~z、0~9、_和任意一个汉字 - \s
任意空白符,包括空格、制表符、换行符 - .
小数点可以匹配任意一个字符,换行除外(如果要匹配包括"\n"在内的所有字符,一般用[\s\S])
[ ]方括号匹配方式,能够匹配方括号中的任意一个字符,^表示取反
-
[ab5@]
匹配"a"或"b"或"5"或"@"
匹配a、b、c之外的任意字符
匹配“f"到"k"之间的字符
匹配“A"-"F","0"-"3"之外的任意一个字符
修饰前面的一个表达式,如果要修饰多个表达式,就用( )把表达式包起来
-
{n}
表达式重复n次
表达式至少重复m次,最多重复n次 贪婪模式 (默认)
匹配符合的最长的字符串
匹配符合的最短的字符串
表达式至少重复m次
匹配表达式0或1次,相当于{0,1}
表达式至少出现一次,相当于{1,}
表达式不出现或出现任意次,相当于{0,}
零宽:匹配的不是字符而是位置,符合某种条件的位置
-
^
与字符串开始的地方匹配
与字符串结束的地方匹配
匹配一个单词的边界,当前位置前面的字符和后面的字符不全是\w
零宽:匹配的不是字符而是位置,符合某种条件的位置
-
(?=exp)
断言自身出现的位置的后面能匹配表达式exp
断言自身出现的位置的后面不能匹配表达式exp
断言自身出现的位置的前面能匹配表达式exp
断言自身出现的位置的前面不能匹配表达式exp
对文本的处理方式
-
IGNORECASE 忽略大小写模式
匹配时忽略大小写
-
整个文本看作一个字符串,只有一个开头一个结尾
-
每行都是一个字符串
分支结构、捕获组合非捕获组
-
| 分支结构
左右表达式之间“或”关系,匹配左边或右边
一些表达式中,不得不使用(),但又不需要保存()中子表达式匹配的内容,这时可以用非捕获组来抵消()带来的副作用。

相关文章推荐
- 一张思维导图,让正则表达式不再难懂
- 一张思维导图,让正则表达式不再难懂
- 一张思维导图,让正则表达式不再难懂
- 一张思维导图,让正则表达式不再难懂
- 一张思维导图,让正则表达式不再难懂
- 一张思维导图,让正则表达式不再难懂
- 正则表达式思维导图,不再难懂
- 正则表达式不再难懂
- 一张思维导图,让 HTTP 超文本协议不再难懂
- python 4-1-2 正则表达式一张图清晰归纳和实现细节
- Spring思维导图,让Spring不再难懂(cache篇)
- Spring思维导图,让Spring不再难懂(ioc篇)
- Spring 思维导图,让 spring 不再难懂
- java基础思维导图,让java不再难懂
- Spring思维导图,让Spring不再难懂(ioc篇)
- Spring思维导图,让Spring不再难懂
- Spring思维导图,让spring不再难懂(一)
- mybatis思维导图,让mybatis不再难懂(二)
- Spring思维导图,让Spring不再难懂(cache篇)
- java基础思维导图,让java不再难懂