Spark上通过BulkLoad快速将海量数据导入到Hbase
2017-10-15 15:43
281 查看
转:https://www.iteblog.com/archives/1891.html
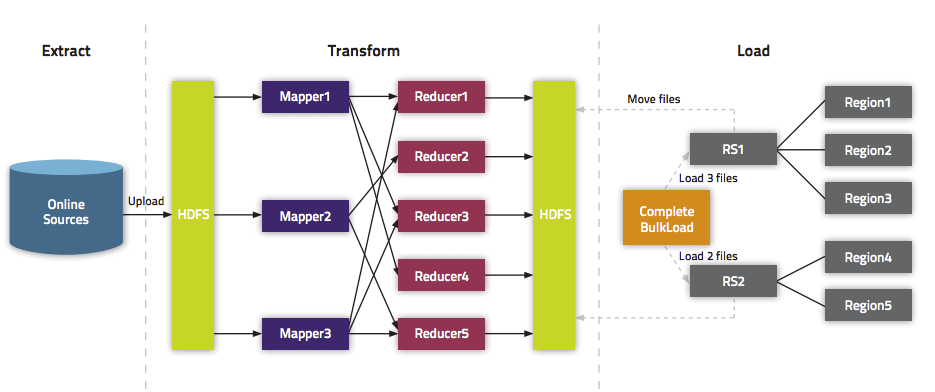
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk
Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》。
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
文章目录
1 使用org.apache.hadoop.hbase.client.Put来写数据
2 批量导数据到Hbase
2.1 批量将Hfiles导入Hbase
2.2 直接Bulk Load数据到Hbase
3 其他
使用
批量导数据到Hbase又可以分为两种:(1)、生成Hfiles,然后批量导数据;
(2)、直接将数据批量导入到Hbase中。
现在我们来介绍如何批量将数据写入到Hbase中,主要分为两步:
(1)、先生成Hfiles;
(2)、使用
实现的代码如下:
运行完上面的代码之后,我们可以看到Hbase中的iteblog表已经生成了10条数据,如下:
这种方法不需要事先在HDFS上生成Hfiles,而是直接将数据批量导入到Hbase中。与上面的例子相比只有微小的差别,具体如下:
将
修改成:
完整的实现如下:
在上面的例子中我们使用了
修改成
剩下的和和之前完全一致。
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk
Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》。
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
文章目录
1 使用org.apache.hadoop.hbase.client.Put来写数据
2 批量导数据到Hbase
2.1 批量将Hfiles导入Hbase
2.2 直接Bulk Load数据到Hbase
3 其他
使用org.apache.hadoop.hbase.client.Put来写数据
使用 org.apache.hadoop.hbase.client.Put将数据一条一条写入Hbase中,但是和Bulk加载相比效率低下,仅仅作为对比。
批量导数据到Hbase
批量导数据到Hbase又可以分为两种:(1)、生成Hfiles,然后批量导数据;(2)、直接将数据批量导入到Hbase中。
批量将Hfiles导入Hbase
现在我们来介绍如何批量将数据写入到Hbase中,主要分为两步:(1)、先生成Hfiles;
(2)、使用
org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles将事先生成Hfiles导入到Hbase中。
实现的代码如下:
直接Bulk Load数据到Hbase
这种方法不需要事先在HDFS上生成Hfiles,而是直接将数据批量导入到Hbase中。与上面的例子相比只有微小的差别,具体如下:将
其他
在上面的例子中我们使用了 saveAsNewAPIHadoopFileAPI来将数据写到HBase中;事实上,我们还可以通过使用
saveAsNewAPIHadoopDatasetAPI来实现同样的目标,我们仅仅需要将下面代码

相关文章推荐
- 在Spark上通过BulkLoad快速将海量数据导入Hbase
- Spark通过bulkLoad对HBase快速导入
- 通过BulkLoad的方式快速导入海量数据到Hbase
- Hbase通过BulkLoad的方式快速导入海量数据
- hbase通过BulkLoad的方式快速导入海量数据
- 通过BulkLoad的方式快速导入海量数据
- 通过Bulk Load导入HBase海量数据
- Hbase通过BulkLoad快速导入数据
- 【甘道夫】通过bulk load将HDFS上的数据导入HBase
- HBase数据快速导入之ImportTsv&Bulkload
- HBase快速导入数据--BulkLoad
- HBase之Bulk Load实现快速导入数据
- HBase数据快速导入之ImportTsv&Bulkload
- HBase数据快速导入之ImportTsv&Bulkload
- How to use Scala on Spark to load data into Hbase/MapRDB -- normal load or bulk load.
- Bulk Load-HBase数据导入最佳实践
- HBase导入大数据三大方式之(二)——importtsv +completebulkload 方式
- HBase高速导入数据--BulkLoad
- HBase导入大数据三大方式之(三)——mapreduce+completebulkload 方式
- Bulk Load-HBase数据导入最佳实践