Linux应用编程基础--(1)标准IO
2017-10-11 20:34
218 查看
一、文件与文件类型
1、文件定义
定义:文件(File)是一个具有符号名字的一组相关联元素的有序序列。文件可以包含的内容十分广泛,操作系统和用户都可以将具有一定独立功能的一个程序模块、一组数据或一组文字命名为一个文件。
文件名:这个数据有序序列集合(文件)的名称。
2、文件的分类
文件由许多种,运行的方式也各有不同。在Windows中,我们是通过文件的后缀名来对文件分类的。例如.txt、.doc、.exe等。而在Linux系统中则不是,它不以文件后缀来区分文件的类型。
在Linux中,我们可以使用ls -l指令来查看文件的类型。在Linux系统中,文件主要有7种类型。
- 普通文件 指ASCII文本文件、二进制文件以及硬链接文件
d 目录文件 包含若干文件或子目录
l 符号链接 只保留所指向文件的地址而非文件本身
p 管道文件 用于进程间通信
c 字符设备 原始的I/O设备文件,每次操作仅操作1个字符(例如键盘)
b 块设备 按块I/O设备文件(例如硬盘)
s 套接字 套接字是方便进程间通信的特殊文件,与管道不同的是套接字能通过网络连接使不同的计算机的进程进行通信
3、Linux的文件目录结构
Linux系统中文件采取树形结构,即一个根目录(/),包含下级目录或文件的信息;子目录又包含更下级的目录或文件的信息。依次类推层层延伸,最终构成一棵树。
//见附图
Linux系统的每个目录都有其特定的功能,这里只简单介绍一些主要目录及其功能
目录 功能说明
/etc 存放系统配置文件
/bin 存放常用指令
/sbin (root用户的)存放指令目录
/home 用户主目录,所有用户p的文件默认建立在此目录下(用户工作目录)
/boot 包含内核启动文件
/dev 存放设备文件(与底层驱动交互)
/usr 存放应用程序
/mnt 挂载目录
/root root用户主目录
/proc process的所写,存放描述系统进程的详细信息
/lib 存放常见库文件
/lost+found 可以找到一些误删除或丢失的文件并恢复它们
二、系统调用与用户编程接口(API)
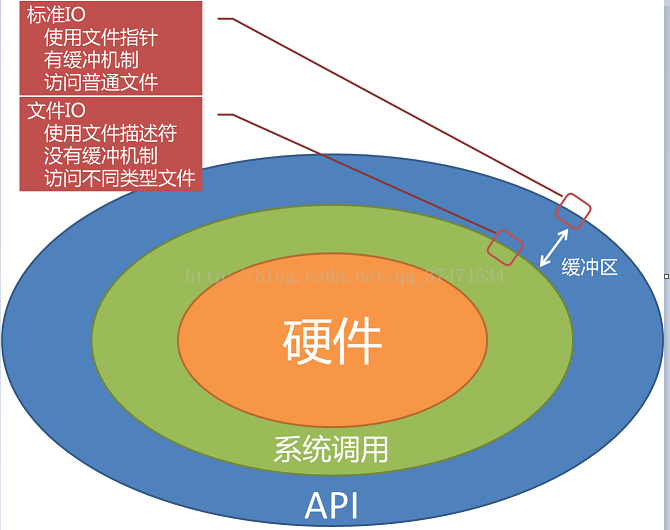
系统调用(System Call)是由操作系统实现提供的 有系统调用所构成的程序接口的集合。是应用程序与操作系统间的接口与纽带。
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境来使应用程序具有良好的兼容性。为了达到这个目的,内核提供一系列具备预定功能的函数,通过系统调用的接口呈现给用户。当用户访问系统调用,系统调用把应用程序的请求传递给内核,调用相应的内核函数完成所需处理,将处理结果返回给应用程序。
应用程序编程接口(API,Application Programming Interface)是一些预定义的函数,目的是提供应用程序与开发人员基于软件/硬件得以访问一组例程的能力,而又无需访问源码或理解内部工作原理机制。
在实际开发应用程序的过程中,我们并不直接使用系统调用接口,而是使用用户编程接口(API)。为什么呢?
⒈系统调用功能非常简单,有时无法满足程序的需求。
⒉不同操作系统的系统调用接口不兼容,若使用系统调用接口则程序移植工作量非常大。
用户编程接口使用各种库(在C语言中最主要的是C库)中的函数。为了提高编程效率,C库中实现了很多函数。这些函数实现了许多常用功能供程序开发者调用。这样一来,程序开发者无需自己编写这些代码,直接可以调用函数就能实现功能,提高了编码效率和代码复用率。
使用用户编程接口还有一个好处:一定程度上解决了程序的可移植性(虽然C语言的可移植性仍没有Java好)。几乎所有的操作系统上都实现了C库,因此使用C语言编写的程序只需在不同的系统下重新编译即可运行。
通常情况下,用户编程接口API在实现时需要依赖系统调用接口。例如创建进程API函数fork()需要调用内核空间的sys_fork()系统调用。但是还有一些API无需调用任何系统调用。
在Linux中用户编程接口遵循在Unix系统中最流行的应用编程编程标准POSIX标准。
/***************POSIX简介*************************/
POSIX表示可移植操作系统接口(Portable Operating System Interface ,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称,其正式称呼为IEEE 1003,而国际标准名称为ISO/IEC 9945。
POSIX标准意在期望获得源代码级别的软件可移植性。换句话说,为一个POSIX兼容的操作系统编写的程序,应该可以在任何其它的POSIX操作系统(即使是来自另一个厂商)上编译执行。
/***************POSIX简介end**********************/
标准I/O与文件I/O的区别:
⒈文件I/O又称为低级磁盘I/O,遵循POSIX标准。任何兼容POSIX标准的操作系统都支持文件I/O。标准I/O又称为高级磁盘I/O,遵循ANSI C相关标准。只要开发环境有标准C库,标准I/O就可以使用。
在Linux系统中使用GLIBC标准,它是标准C库的超集,既支持ANSI C中定义的函数又支持POSIX中定义的函数。因此Linux下既可以使用标准I/O,也可以使用文件I/O。
⒉通过文件I/O读写文件时,每次操作都会执行相关系统调用。这样的好处是直接读写实际文件,坏处是频繁的系统调用会增加系统开销。标准I/O在文件I/O的基础上封装了缓冲机制,每次先操作缓冲区,必要时再访问文件,从而减少了系统调用的次数。
⒊文件I/O使用文件描述符打开操作一个文件,可以访问不同类型的文件(例如普通文件、设备文件和管道文件等)。而标准I/O使用FILE指针来表示一个打开的文件,通常只能访问普通文件。
三、Linux标准I/O
1、标准I/O定义
标准I/O指的是ANSI C中定义的用于I/O操作的一系列函数。只要操作系统安装了C库,就可以调用标准I/O。换句话说,若程序使用标准I/O函数,那么源代码无需进行任何修改就可以在其他操作系统上编译,具有更好的可移植性。
除此之外,由于标准I/O封装了缓冲区,使得在读写文件的时候减少了系统调用的次数,提高了效率。在执行系统调用的时候,Linux必须从用户态切换到内核态,在内核中处理相应的请求,然后再返回用户态。如果频繁地执行系统调用则会增加这种开销。标准I/O为了减少这种开销,采取缓冲机制,为用户空间创建缓冲区,读写时优先操作缓冲区,在必须访问文件时(例如缓冲区满、强制刷新、文件读写结束等情况)再通过系统调用将缓冲区的数据读写实际文件中,从而避免了系统调用的次数。
2、流的定义
标准I/O的核心对象是流。当用标准I/O打开一个文件时,就会创建一个FILE结构体描述该文件。我们把这个FILE结构体称为“流”。标准I/O函数都是基于流进行各种操作的。
/**********************流的分类***********************/
流的分类分为文本流和二进制流两种:
文本流:文本流是由字符文件组成的序列, 每一行包含0个或多个字符并以'\n'结尾。在流处理过程中所有数据以字符形式出现,'\n'被当做回车符CR和换行符LF两个字符处理,即'\n'ASCII码存储形式是0x0D和0x0A。当输出时,0x0D和0x0A转换成'\n'
二进制流:二进制流是未经处理的字节组成的序列,在流处理过程中把数据当做二进制序列,若流中有字符则把字符当做ASCII码的二进制数表示。'\n'不进行变换。
例如:2016在文本流中和二进制流中的数据类型不同:
文本流:2016---->'2''0''1''6'---->50 48 49 54
二进制流:2016-->数字2016--->0000011111010001
在Linux/Unix系统中,文本流与二进制流没有差异,但是在Windows中稍有差异,所以标准C库定义了两种流。
/**********************流的分类end********************/
在使用标准I/O操作文件的时候,每个被程序使用的文件都会在内存中开辟一块区域,用来存放与文件相关的属性信息,这些信息存放在一个FILE类型的结构体中,FILE类型的结构体是由系统定义的一个结构体:
typedef struct
{
short level;//缓冲区满/空的状态
unsigned flags;//文件状态标志
char fd;//文件描述符
unsigned char hold;//如缓冲区无内容则不读取字符
short bsize;//缓冲区的大小
unsigned char *buffer;//数据缓冲区的位置
unsigned char *curp;//指针当前的指向
unsigned istemp;//临时文件指示器
short token;//用于有效性检查
}FILE;
在标准I/O中,常用FILE类型的结构体指针FILE*来操作文件。
/***************对“流”与“文件”的关系的讨论************/
在初学C语言文件I/O相关知识点时,经常会陷入“什么是流?”“什么是文件?”“流和文件有什么关系(区别)?”等问题。在这里对“流”与“文件”进行简单的讨论,基础好的同学可跳过该部分。
《C Primer Plus》上说,C程序处理一个流而不是直接处理文件。但是后面的解释十分抽象:『流(stream)是一个理想化的数据流,实际输入或输出映射到这个数据流』。
本质上来说,文件本身就是数据的有序序列,因此我们操作文件时是按顺序依次操作该文件的数据。我们可以想象一个传送带,传送带上的产品就是待操作数据。当我们对文件内的数据进行操作时,已操作的数据从当前位置离开,待操作的数据不断流向当前位置,这样文件内的数据就产生了流动的感觉,这个“传送带”就是C语言内“流”的原型。
我们打开一个流,就意味着将该流与该文件进行了连接(即让文件内的“产品”放上“传送带”),关闭流将断开流与该文件的连接。此时我们对流进行操作就是对文件进行操作。通常在不产生歧义的情况下,“文件”与“流”可以不予区分。
在程序开始执行的时候,操作系统会默认开启stdin、stdout、stderr三个文件,这三个文件作为输入、输出、输出错误的流,这样我们使用诸如scanf()、printf()等就无需手动加载流,方便使用。
当我们使用fopen()打开一个文件的时候,该文件会返回一个FILE*类型的指针,例如:
FILE *fp = fopen("hello.txt","w")
此时文件hello.txt与流指针fp就关联了起来,对fp的操作就相当于对文件hello.txt进行操作。
/***************对“流”与“文件”的关系的讨论end*********/
在标准I/O中预定义了三块缓冲区:stdin、stdout、stderr,分别代表标准输入流、标准输出流、标准输出错误流。见下:
流的名称 程序中使用
标准输入 stdin
标准输出 stdout
标准错误输出 stderr
标准I/O中的流的缓冲类型有三种:
⒈全缓冲:这种情况下,当缓冲区被填满后才进行实际的I/O操作。对于存放在磁盘上的普通文件用标准I/O打开时默认是全缓冲的。当缓冲区满或者执行刷新缓冲区(fflush)操作才会进行磁盘操作。
⒉行缓冲:这种情况下,当在输入/输出中遇到换行符时执行I/O操作。标准输入/输出流(stdin/stdout)就是使用行缓冲。
⒊无缓冲:不使用缓冲区进行I/O操作,即对流的读写操作会立即操作实际文件。标准出错流(stderr)是不带缓冲的,这就使得当发生错误时,错误信息能第一时间显示在终端上,而不管错误信息是否包含换行符。
示例1.1:stdout使用行缓冲形式
效果:不会立即打印内容,而是等待'\n'或者缓冲区满才输出。
#include<stdio.h>
int main()
{
while(1)
{
printf("Hello World");
sleep(1);//延时1秒
}
return 0;
}
示例1.2:stdout使用行缓冲形式
效果:当添加了'\n'之后,会正确地输出
#include<stdio.h>
int main()
{
while(1)
{
printf("Hello World\n");
sleep(1);//延时1秒
}
return 0;
}
示例1.3:stderr使用无缓冲形式
效果:stderr使用无缓冲,即使不使用'\n'仍能立即输出
#include<stdio.h>
int main()
{
while(1)
{
perror("Hello World");
sleep(1);//延时1秒
}
return 0;
}
示例2:编写程序实现以下功能:
⒈向标准输出流输出HelloWorld
⒉向标准错误流输出HelloWorld
⒊控制输出重定向,使程序仅能输出标准输出流的字符
⒋控制输出重定向,使程序仅能输出标准错误流的字符
#include<stdio.h>
int main()
{
fprintf(stdout,"%s","This is stdout:HelloWorld!\n");
fprintf(stderr,"%s","This is stderr:HelloWorld!\n");
//fprintf的作用是向某个流(文件)中按格式输出指定内容
return 0;
}
实现第三步的功能:在执行时:./a.out 2> /dev/null
实现第四步的功能:在执行时:./a.out 1> /dev/null
四、标准I/O编程
关于标准IO编程的相关函数及其用法:(参考来自于man手册)



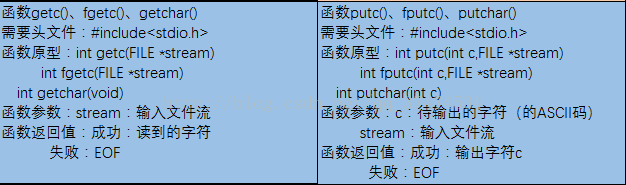

1、文件定义
定义:文件(File)是一个具有符号名字的一组相关联元素的有序序列。文件可以包含的内容十分广泛,操作系统和用户都可以将具有一定独立功能的一个程序模块、一组数据或一组文字命名为一个文件。
文件名:这个数据有序序列集合(文件)的名称。
2、文件的分类
文件由许多种,运行的方式也各有不同。在Windows中,我们是通过文件的后缀名来对文件分类的。例如.txt、.doc、.exe等。而在Linux系统中则不是,它不以文件后缀来区分文件的类型。
在Linux中,我们可以使用ls -l指令来查看文件的类型。在Linux系统中,文件主要有7种类型。
- 普通文件 指ASCII文本文件、二进制文件以及硬链接文件
d 目录文件 包含若干文件或子目录
l 符号链接 只保留所指向文件的地址而非文件本身
p 管道文件 用于进程间通信
c 字符设备 原始的I/O设备文件,每次操作仅操作1个字符(例如键盘)
b 块设备 按块I/O设备文件(例如硬盘)
s 套接字 套接字是方便进程间通信的特殊文件,与管道不同的是套接字能通过网络连接使不同的计算机的进程进行通信
3、Linux的文件目录结构
Linux系统中文件采取树形结构,即一个根目录(/),包含下级目录或文件的信息;子目录又包含更下级的目录或文件的信息。依次类推层层延伸,最终构成一棵树。
//见附图
Linux系统的每个目录都有其特定的功能,这里只简单介绍一些主要目录及其功能
目录 功能说明
/etc 存放系统配置文件
/bin 存放常用指令
/sbin (root用户的)存放指令目录
/home 用户主目录,所有用户p的文件默认建立在此目录下(用户工作目录)
/boot 包含内核启动文件
/dev 存放设备文件(与底层驱动交互)
/usr 存放应用程序
/mnt 挂载目录
/root root用户主目录
/proc process的所写,存放描述系统进程的详细信息
/lib 存放常见库文件
/lost+found 可以找到一些误删除或丢失的文件并恢复它们
二、系统调用与用户编程接口(API)
系统调用(System Call)是由操作系统实现提供的 有系统调用所构成的程序接口的集合。是应用程序与操作系统间的接口与纽带。
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境来使应用程序具有良好的兼容性。为了达到这个目的,内核提供一系列具备预定功能的函数,通过系统调用的接口呈现给用户。当用户访问系统调用,系统调用把应用程序的请求传递给内核,调用相应的内核函数完成所需处理,将处理结果返回给应用程序。
应用程序编程接口(API,Application Programming Interface)是一些预定义的函数,目的是提供应用程序与开发人员基于软件/硬件得以访问一组例程的能力,而又无需访问源码或理解内部工作原理机制。
在实际开发应用程序的过程中,我们并不直接使用系统调用接口,而是使用用户编程接口(API)。为什么呢?
⒈系统调用功能非常简单,有时无法满足程序的需求。
⒉不同操作系统的系统调用接口不兼容,若使用系统调用接口则程序移植工作量非常大。
用户编程接口使用各种库(在C语言中最主要的是C库)中的函数。为了提高编程效率,C库中实现了很多函数。这些函数实现了许多常用功能供程序开发者调用。这样一来,程序开发者无需自己编写这些代码,直接可以调用函数就能实现功能,提高了编码效率和代码复用率。
使用用户编程接口还有一个好处:一定程度上解决了程序的可移植性(虽然C语言的可移植性仍没有Java好)。几乎所有的操作系统上都实现了C库,因此使用C语言编写的程序只需在不同的系统下重新编译即可运行。
通常情况下,用户编程接口API在实现时需要依赖系统调用接口。例如创建进程API函数fork()需要调用内核空间的sys_fork()系统调用。但是还有一些API无需调用任何系统调用。
在Linux中用户编程接口遵循在Unix系统中最流行的应用编程编程标准POSIX标准。
/***************POSIX简介*************************/
POSIX表示可移植操作系统接口(Portable Operating System Interface ,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称,其正式称呼为IEEE 1003,而国际标准名称为ISO/IEC 9945。
POSIX标准意在期望获得源代码级别的软件可移植性。换句话说,为一个POSIX兼容的操作系统编写的程序,应该可以在任何其它的POSIX操作系统(即使是来自另一个厂商)上编译执行。
/***************POSIX简介end**********************/
标准I/O与文件I/O的区别:
⒈文件I/O又称为低级磁盘I/O,遵循POSIX标准。任何兼容POSIX标准的操作系统都支持文件I/O。标准I/O又称为高级磁盘I/O,遵循ANSI C相关标准。只要开发环境有标准C库,标准I/O就可以使用。
在Linux系统中使用GLIBC标准,它是标准C库的超集,既支持ANSI C中定义的函数又支持POSIX中定义的函数。因此Linux下既可以使用标准I/O,也可以使用文件I/O。
⒉通过文件I/O读写文件时,每次操作都会执行相关系统调用。这样的好处是直接读写实际文件,坏处是频繁的系统调用会增加系统开销。标准I/O在文件I/O的基础上封装了缓冲机制,每次先操作缓冲区,必要时再访问文件,从而减少了系统调用的次数。
⒊文件I/O使用文件描述符打开操作一个文件,可以访问不同类型的文件(例如普通文件、设备文件和管道文件等)。而标准I/O使用FILE指针来表示一个打开的文件,通常只能访问普通文件。
三、Linux标准I/O
1、标准I/O定义
标准I/O指的是ANSI C中定义的用于I/O操作的一系列函数。只要操作系统安装了C库,就可以调用标准I/O。换句话说,若程序使用标准I/O函数,那么源代码无需进行任何修改就可以在其他操作系统上编译,具有更好的可移植性。
除此之外,由于标准I/O封装了缓冲区,使得在读写文件的时候减少了系统调用的次数,提高了效率。在执行系统调用的时候,Linux必须从用户态切换到内核态,在内核中处理相应的请求,然后再返回用户态。如果频繁地执行系统调用则会增加这种开销。标准I/O为了减少这种开销,采取缓冲机制,为用户空间创建缓冲区,读写时优先操作缓冲区,在必须访问文件时(例如缓冲区满、强制刷新、文件读写结束等情况)再通过系统调用将缓冲区的数据读写实际文件中,从而避免了系统调用的次数。
2、流的定义
标准I/O的核心对象是流。当用标准I/O打开一个文件时,就会创建一个FILE结构体描述该文件。我们把这个FILE结构体称为“流”。标准I/O函数都是基于流进行各种操作的。
/**********************流的分类***********************/
流的分类分为文本流和二进制流两种:
文本流:文本流是由字符文件组成的序列, 每一行包含0个或多个字符并以'\n'结尾。在流处理过程中所有数据以字符形式出现,'\n'被当做回车符CR和换行符LF两个字符处理,即'\n'ASCII码存储形式是0x0D和0x0A。当输出时,0x0D和0x0A转换成'\n'
二进制流:二进制流是未经处理的字节组成的序列,在流处理过程中把数据当做二进制序列,若流中有字符则把字符当做ASCII码的二进制数表示。'\n'不进行变换。
例如:2016在文本流中和二进制流中的数据类型不同:
文本流:2016---->'2''0''1''6'---->50 48 49 54
二进制流:2016-->数字2016--->0000011111010001
在Linux/Unix系统中,文本流与二进制流没有差异,但是在Windows中稍有差异,所以标准C库定义了两种流。
/**********************流的分类end********************/
在使用标准I/O操作文件的时候,每个被程序使用的文件都会在内存中开辟一块区域,用来存放与文件相关的属性信息,这些信息存放在一个FILE类型的结构体中,FILE类型的结构体是由系统定义的一个结构体:
typedef struct
{
short level;//缓冲区满/空的状态
unsigned flags;//文件状态标志
char fd;//文件描述符
unsigned char hold;//如缓冲区无内容则不读取字符
short bsize;//缓冲区的大小
unsigned char *buffer;//数据缓冲区的位置
unsigned char *curp;//指针当前的指向
unsigned istemp;//临时文件指示器
short token;//用于有效性检查
}FILE;
在标准I/O中,常用FILE类型的结构体指针FILE*来操作文件。
/***************对“流”与“文件”的关系的讨论************/
在初学C语言文件I/O相关知识点时,经常会陷入“什么是流?”“什么是文件?”“流和文件有什么关系(区别)?”等问题。在这里对“流”与“文件”进行简单的讨论,基础好的同学可跳过该部分。
《C Primer Plus》上说,C程序处理一个流而不是直接处理文件。但是后面的解释十分抽象:『流(stream)是一个理想化的数据流,实际输入或输出映射到这个数据流』。
本质上来说,文件本身就是数据的有序序列,因此我们操作文件时是按顺序依次操作该文件的数据。我们可以想象一个传送带,传送带上的产品就是待操作数据。当我们对文件内的数据进行操作时,已操作的数据从当前位置离开,待操作的数据不断流向当前位置,这样文件内的数据就产生了流动的感觉,这个“传送带”就是C语言内“流”的原型。
我们打开一个流,就意味着将该流与该文件进行了连接(即让文件内的“产品”放上“传送带”),关闭流将断开流与该文件的连接。此时我们对流进行操作就是对文件进行操作。通常在不产生歧义的情况下,“文件”与“流”可以不予区分。
在程序开始执行的时候,操作系统会默认开启stdin、stdout、stderr三个文件,这三个文件作为输入、输出、输出错误的流,这样我们使用诸如scanf()、printf()等就无需手动加载流,方便使用。
当我们使用fopen()打开一个文件的时候,该文件会返回一个FILE*类型的指针,例如:
FILE *fp = fopen("hello.txt","w")
此时文件hello.txt与流指针fp就关联了起来,对fp的操作就相当于对文件hello.txt进行操作。
/***************对“流”与“文件”的关系的讨论end*********/
在标准I/O中预定义了三块缓冲区:stdin、stdout、stderr,分别代表标准输入流、标准输出流、标准输出错误流。见下:
流的名称 程序中使用
标准输入 stdin
标准输出 stdout
标准错误输出 stderr
标准I/O中的流的缓冲类型有三种:
⒈全缓冲:这种情况下,当缓冲区被填满后才进行实际的I/O操作。对于存放在磁盘上的普通文件用标准I/O打开时默认是全缓冲的。当缓冲区满或者执行刷新缓冲区(fflush)操作才会进行磁盘操作。
⒉行缓冲:这种情况下,当在输入/输出中遇到换行符时执行I/O操作。标准输入/输出流(stdin/stdout)就是使用行缓冲。
⒊无缓冲:不使用缓冲区进行I/O操作,即对流的读写操作会立即操作实际文件。标准出错流(stderr)是不带缓冲的,这就使得当发生错误时,错误信息能第一时间显示在终端上,而不管错误信息是否包含换行符。
示例1.1:stdout使用行缓冲形式
效果:不会立即打印内容,而是等待'\n'或者缓冲区满才输出。
#include<stdio.h>
int main()
{
while(1)
{
printf("Hello World");
sleep(1);//延时1秒
}
return 0;
}
示例1.2:stdout使用行缓冲形式
效果:当添加了'\n'之后,会正确地输出
#include<stdio.h>
int main()
{
while(1)
{
printf("Hello World\n");
sleep(1);//延时1秒
}
return 0;
}
示例1.3:stderr使用无缓冲形式
效果:stderr使用无缓冲,即使不使用'\n'仍能立即输出
#include<stdio.h>
int main()
{
while(1)
{
perror("Hello World");
sleep(1);//延时1秒
}
return 0;
}
示例2:编写程序实现以下功能:
⒈向标准输出流输出HelloWorld
⒉向标准错误流输出HelloWorld
⒊控制输出重定向,使程序仅能输出标准输出流的字符
⒋控制输出重定向,使程序仅能输出标准错误流的字符
#include<stdio.h>
int main()
{
fprintf(stdout,"%s","This is stdout:HelloWorld!\n");
fprintf(stderr,"%s","This is stderr:HelloWorld!\n");
//fprintf的作用是向某个流(文件)中按格式输出指定内容
return 0;
}
实现第三步的功能:在执行时:./a.out 2> /dev/null
实现第四步的功能:在执行时:./a.out 1> /dev/null
四、标准I/O编程
关于标准IO编程的相关函数及其用法:(参考来自于man手册)

相关文章推荐
- linux系统编程之基础必备(二):C 标准IO 库函数与Unbuffered IO函数
- 2.Linux应用编程——标准IO
- Linux应用编程基础--(2)文件IO
- Linux IO操作应用编程基础
- 【linux草鞋应用编程系列】_1_ 开篇_系统调用IO接口与标准IO接口
- Linux应用编程基础之多路复用:select和poll的简单使用示例
- linux编程-标准IO
- Linux 系统应用编程——标准I/O
- 【Linux系统编程应用】 V4L2编程基础(一)
- Linux 系统应用编程——进程基础
- Linux网络编程基础_6_应用层(下)--E-mail,WWW(大结局)
- Linux 系统应用编程——进程基础
- Linux高性能server编程——Linux网络基础API及应用
- Linux编程-标准IO(2)
- Linux 系统应用编程——进程基础
- Linux 系统应用编程——线程基础
- Linux 系统应用编程——标准I/O
- Linux 系统应用编程——线程基础
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO
- Linux 系统应用编程——标准I/O