Python selenium使用总结
2017-10-11 08:14
519 查看
简介以及安装:
selenium作为一个自动化的测试工具,主要用于web页面的测试,在Python爬虫中,我们可以使用此工具来对网页元素进行操作,例如启动浏览器,打开网页,前进与后退,定位元素,键盘输入与鼠标点击操作等。可以说,只要在浏览器能够进行的操作,我们都可以用selenium来实现OK,首先我们需要先安装selenium
如果你的电脑上安装了Python和pip的话,我们只需要调用
pip install selenium
这个命令就可以了
安装完毕之后我们需要测试一下
from selenium import webdriver
调用FireFox浏览器
broswer=webdriver.Firefox()
打开百度
broswer.get('http://www.baidu.com')
显示百度的源代码
print(broswer.page_source)这样我们就可以通过火狐来打开百度的页面并且可以显示出百度的源代码了。
PS:因为是通过浏览器打开的页面,所以此时的源代码为JS渲染过之后的源代码
如果在代码运行的时候出错,系统无法启动火狐的话,且错误代码为
selenium.common.exceptions.WebDriverException: Message: ‘geckodriver’ executable needs to be in PATH.
原因1、:selenium的版本过低,不支持相应的Firefox的版本; 解决办法: 下载最新的selenium进行安装(这个原因一般可能性不大)
原因2、你使用的是火狐47以上的版本,需要下载第三方driver,即geckodriver,然后将geckodriver.exe放置在python.exe同一目录下或者将geckodriver.exe所在目录添加至环境变量就可以了
元素操作
当我们把selenium安装调试完成之后,我们就可以使用它来操作网页了首先,我们知道网页是由各式各样的元素拼接而成的,你需要对网页进行修改,我们首先需要定位到你需要修改的网页元素。
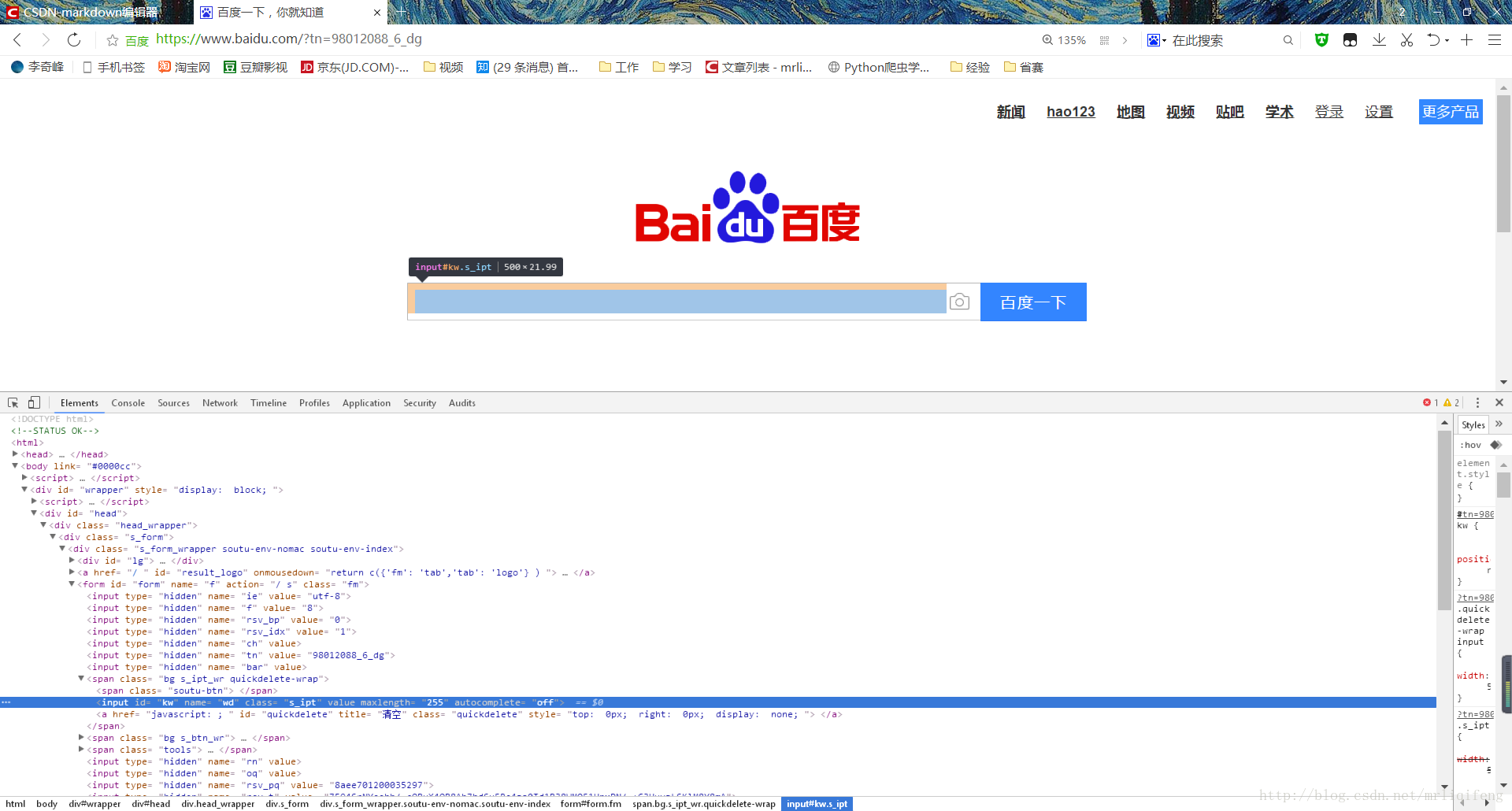
我们以百度为例,可以看到,百度的搜索框是这么一个元素
input id=”kw” name=”wd” class=”s_ipt” value=”” maxlength=”255” autocomplete=”off”
接下来,我们就可以通过定位这个元素,然后对搜索框进行操作了
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
broswer=webdriver.Firefox()
broswer.get('http://www.baidu.com')
通过id定位百度搜索框
searchItem=broswer.find_element_by_id('kw')
等待3秒
time.sleep(3)
向搜索框发送文字:图片
searchItem.send_keys('图片')
点击回车
searchItem.send_keys(Keys.ENTER)
显示当前页面的源代码
print(broswer.page_source)运行上述代码,系统首先会打开一个火狐浏览器,然后浏览器会自动打开百度页面,等待三秒后,搜索框会自动输入文字,然后点击回车
为什么要有
time.sleep(3)
这个操作呢,因为网页的加载需要时间,我们必须确保网页的元素全部加载出来才能进行操作
刚才我们使用过使用回车键来完成搜索,接下来我们通过点击搜索按钮来进行操作
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
broswer=webdriver.Firefox()
broswer.get('http://www.baidu.com')
通过id定位百度搜索框
searchItem=broswer.find_element_by_id('kw')
通过class定位“百度一下”按钮
searchButton=broswer.find_element_by_class_name('bg s_btn')
等待3秒
time.sleep(3)
向搜索框发送文字:图片
searchItem.send_keys('图片')
点击搜索按钮
searchButton.click()
显示当前页面的源代码
print(broswer.page_source)以上代码可以实现和之前代码相同的操作,只不过我们是通过点击搜索按钮来完成搜索
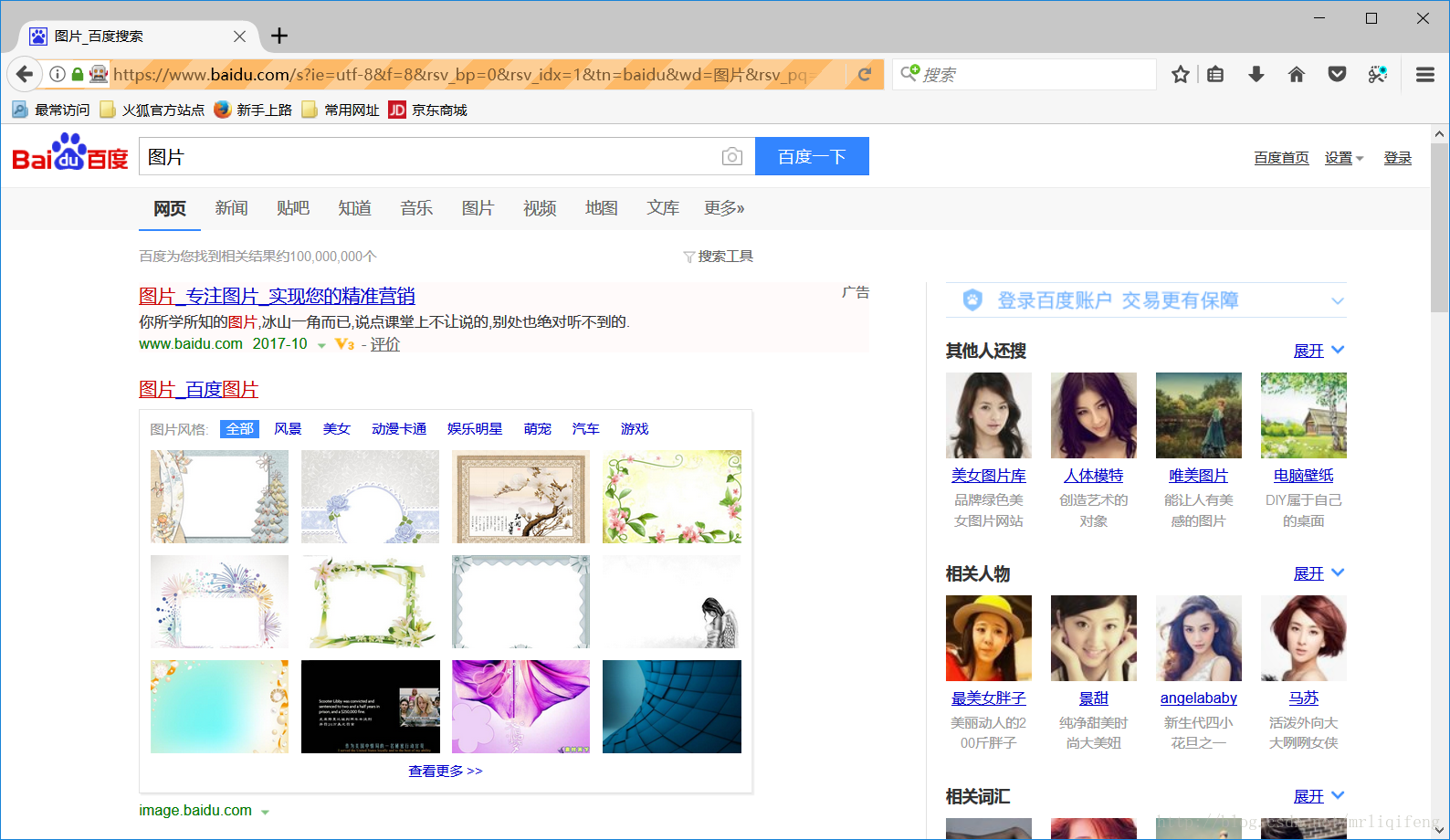
这是完成搜索之后的页面
关于selenium中页面元素的定位方式,大家可以参考一下这篇博客
Selenium Webdriver元素定位的八种常用方式
框架切换
页面中往往包含着很多iframe框架,很多元素都被放在了框架当中举例来说,我们需要模拟登陆QQ空间的页面

我们通过点击已登录的QQ头像来进行登录,首先我已经获取了头像的元素id为‘img_out_1356306040’,接下来我们就可以进行操作了
from selenium import webdriver
import time
broswer=webdriver.Firefox()
broswer.get(url='https://i.qq.com')
time.sleep(2)
broswer.find_element_by_id('img_out_1356306040').click()当我们运行程序之后,电脑会出现这样的错误
selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: [id="img_out_1356306040"]
这段代码表明没有找到 id=”img_out_1356306040”的这么一个元素,
我们再来仔细分析一下这个网页的构成
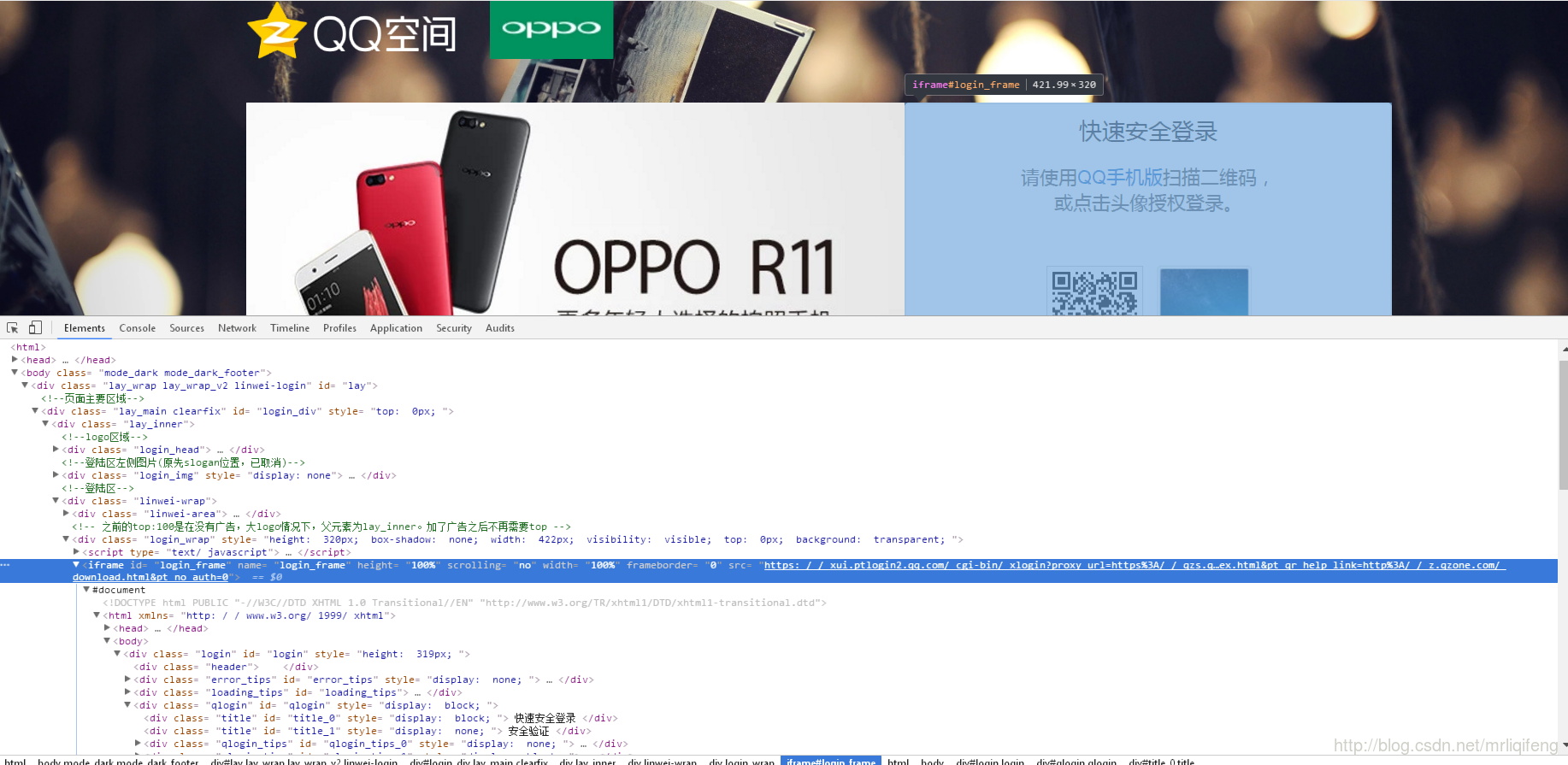
可以发现,登录头像的位置放在了一个 id=“login_frame”的iframe框架里,所以我们需要先定位这个框架,然后才能定位到框架中具体的元素
from selenium import webdriver
import time
broswer=webdriver.Firefox()
broswer.get(url='https://i.qq.com')
time.sleep(2)
定位到'login_frame'框架
broswer.switch_to.frame('login_frame')
broswer.find_element_by_id('img_out_1356306040').click()
返回至默认框架
broswer.switch_to.default_content()
print(broswer.page_source)运行上述代码,我们就可以成功登录到QQ空间里了
总结:
以上就是selenium的简单用法,我们可以通过selenium来对网页进行各种操作,我感觉浏览器能实行的操作,好像通过selenium都可以做到,总之是一个非常强大的工具,通过selenium我们就可以进一步的使用python爬虫来爬取互联网的数据
相关文章推荐
- Windows环境下使用python selenium 打开Firefox的问题总结
- python下初步使用selenium/phantomJS问题总结
- Python字符串使用总结
- 【转帖】使用python爬虫抓站的一些技巧总结:进阶篇
- 使用swig为python添加c扩展总结
- Python SIP使用总结(Win&Linux通用)
- Django在使用mod_python+apache中配置VirtualHost的问题总结
- python采用pika库使用rabbitmq总结,多篇笔记和示例
- python最近使用问题总结
- Python中PyQuery库的使用总结
- .net下Selenium2使用方法总结
- python 各种解析xml包使用方法总结 - 转
- selenium+python+API分类总结
- 使用python和正则表达式获取url,及总结
- python中使用selenium
- Selenium的运行环境不要使用python3
- Python使用SOAPpy调用.net写的WebService的乱码问题总结
- Selenium-解决使用Webdrive打开Firefox不含有插件的问题(python)
- python 字符串使用总结