数据结构与算法(周鹏-未出版)-第六章 树-6.5 Huffman 树
2017-10-11 00:17
302 查看
6.5 Huffman 树
Huffman 树又称最优树,可以用来构造最优编码,用于信息传输、数据压缩等方面,是一类有着广泛应用的二叉树。
6.5.1 二叉编码树
在计算机系统中,符号数据在处理之前首先需要对符号进行二进制编码。例如,在计算机中使用的英文字符的 ASCII 编码就是 8 位二进制编码,由于 ASCII 码使用固定长度的二进制位表示字符,因此 ASCII 码是一种定长编码。为了缩短数据编码长度,可以采用不定长编码。其基本思想是:给使用频度较高的字符编较短的编码,这是数据压缩技术的最基本思想。如何给数据中的字符编以不定长编码,而使数据编码的平均长度最短呢?
首先分析第一个问题:如何对字符集进行不定长编码。在一个编码系统中,任何一个编码都不是其他编码的前缀,则称该编码系统的编码是前缀码。例如: 01, 10, 110, 111, 101 就不是前缀编码,因为 10 是 101 的前缀,如果去掉 10 或101 就是前缀编码。当在一个编码系统中采用定长编码时,可以不需要分隔符;如果采用不是前缀编码,因为 10 是 101 的前缀,如果去掉 10 或101 就是前缀编码。当在一个编码系统中采用定长编码时,可以不需要分隔符;如果采用不定长编码时,必须使用前缀编码或分隔符,否则在解码时会产生歧义。所谓解码就是由二进制位串还原字符数据的过程。而使用分隔符会加大编码长度,因此一般采用前缀编码。例 6-1 说明了这个问题。
例 6-1 假设字符集为{A, B, C, D},原文为 ABACCDA。
一种等长编码方案为 A:00 B:01 C:10 D:11,此时编解码不会产生歧义,过程如下。
编码: ABACCDA → 00010010101100
解码: 00010010101100 → ABACCDA
一种不等长编码方案为: A:0 B:00 C:1 D:01,由于此编码不是前缀码,此时在编解码的过程中会产生歧义。对于同一编码可以有不同的解码,过程如下。
编码: ABACCDA → 000011010
解码: 000011010 → AAAACCDA
000011010 → BBCCDA 错误!出现歧义。
为产生没有歧义的前缀编码,可以使用二叉编码树来实现。使用二叉树对字符集中的字符进行编码的方法是,将字符集中的所有字符作为二叉树的叶子结点;在二叉树中,每一个“父亲—左孩子”关系对应一位二进制位 0,每一个“父亲—右孩子”关系对应一位二进制位 1 ;于是从根结点通往每个叶子结点的路径,就对应于相应字符的二进制编码。每个字符编码的长度 L 等于对应路径的长度,也等于该叶子结点的层次数。例如对于例 6-1 中的每个字符可以按照图 6-15 所示的二叉编码树
进行编码。按照图 6-15 中的二叉编码树对 A、 B、 C、 D 四个字符进行编码,则 A 的编码是 0, B 的编码是 100, C 的编码是 11 , D的编码是 101。这个编码显然是一个前缀编码。
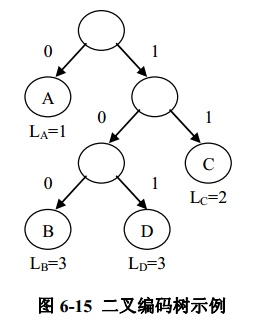
由于在二叉树中任何一个叶子结点都不会出现在根到其他叶子结点的路径上,那么按照上述二叉编码树的编码方法,任何一个叶子结点表示的编码都不会是任何其他叶子表示编码的前缀,因此由二叉编码树得到的编码都是前缀码。反过来如果要进行解码,也可以由二叉编码树便捷的完成。解码的过程是从头开始扫描二进制编码位串,并从二叉编码树的根结点开始,根据比特位不断进入下一层结点,当碰到0 时向左深入,为 1 时向右深入;到达叶子结点后输出其对应的字符,然后重新回到根结点,并继续扫描二进制位串直到完毕。还是如图 6-15 所示,此时将 ABACCDA 进行编码得到: 0100011111010。解码过程是从左到右扫描二进制位串。在读出最前端的 0 后,相应的从根结点到达结点,于是输出 A,重新回到根结点;依次扫描后续二进制位 100,到达叶子结点 B,于是输出 B,重新回到根结点;读出下一个二进制位 0,输出 A;读出 11 ,输出 C;读出 11 ,输出 C;读出 101,输出 D;最后读出 0,输出 A;此时二进制位串扫描完毕,相应的解码工作也完成,最后得到字符数据 ABACCDA。
6.5.2 Huffman 树及 Huffman 编码
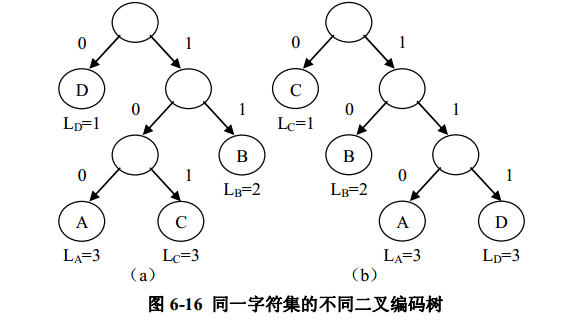
在上一小节中介绍了如何对字符集进行不定长编码的方法,但是同时我们看到对于同一个字符集进行编码的二叉编码树可以有很多,只要叶子结点个数与字符个数对应即可。例如
对例 6-1 中字符即进行编码的二叉树就可以有,但不限于图 6-16 所示的二叉树。在这些不同的编码中哪个才是使得编码长度最小的呢?例如在例 6-1 中,选择图 6-15 中的编码方案比选择图 6-16 中的两种编码方案好。由于
字符 A、 B、 C、 D 分别出现了 3 次、 1 次、2 次、 1 次。使用图 6-15 的编码方案,编码的长度为 3×1+1×3+2×2+1×3=13;使用图 6-16( a)的编码方案,编码的长度为 3×3+1×2+2×3+1×1
=18;使用图 6-16( b)的编码方案,编码的长度为 3×3+1×2+2×1+1×3=16。
字符集中各种字符出现的概率是不同的,字符的出现概率决定了编码方案的选择。

当引入以上概念以后,求最佳编码方案实际上就抽象为求在叶子结点个数与权确定时带权路径长度最小的二叉树。那么什么样的树带权路径长度最小呢?
对于给定n个权值w1, w2, … wn( n≥2),求一棵具有n个叶子结点的二叉树,使其带权路径长度∑ WiLi最小。由于Huffman给出了构造具有这种树的方法,因此这种树称为Huffman树。
Huffman 树: 它是由 n 个带权叶子结点构成的所有二叉树中带权路径长度最小的二叉树, Huffman 树又称最优二叉树。
构造 Huffman 树的算法步骤如下:
① 根据给定的 n 个权值,构造 n 棵只有一个根结点的二叉树, n 个权值分别是这些二叉树根结点的权, F 是由这 n 棵二叉树构成的集合;
② 在 F 中选取两棵根结点树值最小的树作为左、右子树,构造一颗新的二叉树,置新二叉树根的权值=左子树根结点权值+右子树根结点权值;
③ 从 F 中删除这两颗树,并将新树加F:
④ 重复②、③,直到 F 中只含一棵树为止。
直观地看,先选择权值小的,所以权值小的结点被放置在树的较深层,而权值较大的离根较近,这样自然在 Huffman 树中权越大的叶子离根越近,这样一来,在计算树的带权路径长度时,自然会具有最小的带权路径长度,这种生成算法就是一种典型的贪心算法。用上述算法可以验证在例 6-1 中,图 6-15 所示的二叉树就是 Huffman 树,即例 6-1 中原文 ABACCDA 的最短编码长度为 13。
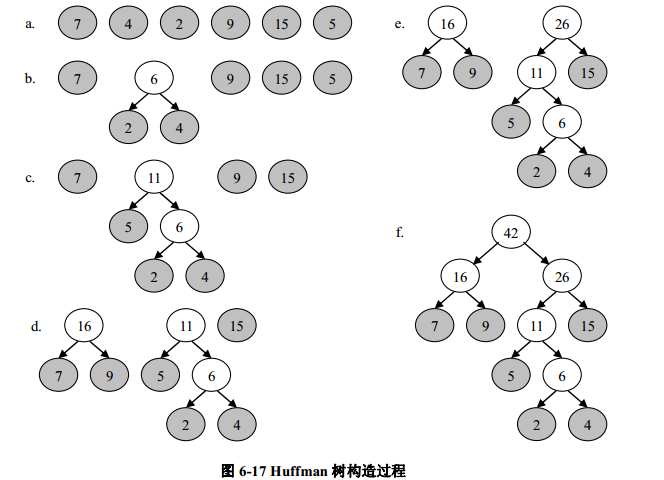
例6-2 假设有一组权值{7, 4, 2, 9, 15, 5},试构造以这些权值为叶子的 Huffman 树。构造 Huffman 树的过程如图 6-17 所示
使用二叉编码树进行编码,以字符出现的概率作为相应叶子的权值,当这棵二叉编码树是 Huffman 树时,所得到的编码称之为 Huffman 编码。例 6-1 中 A、 B、 C、 D 四个字符的Huffman 编码分别是 0、 100、 11、 101。
下面讨论构造 Huffman 树的具体实现。
Huffman 树的实现可以使用顺序的存储结构也可以使用链式的存储结构。前面给出了二叉树的链式存储实现,这里我们也给出 Huffman 树的链式存储结构的实现。
Huffman 树也是一棵二叉树,其结点可以继承二叉树的结点来实现,但是需要两个新的属性,即权值和编码。代码 6-2 定义了 Huffman 树的节点结构。
代码 6-2 Huffman树结点定义
构造 Huffman 树的过程可以通过算法 6-7 实现。
算法 6-7 buildHuffmanTree
输入: 结点数组 nodes
输出: Huffman 树的根结点
代码:
算法 6-7 说明:算法使用一个线性表l保存在生成Huffman树过程中森林F的所有树的根结点,并保持在线性表中这些根结点的权值从大到小有序。不难知道当线性表采用数组实现时方法insertToList的运行时间为Ο(n)。因此初始化将n个叶子结点插入线性表的时间为Ο(n2)。在有线性表l之后,取得最小权值的 2 个根结点,只需要Ο(1)的时间,合并 2 棵树需要Ο(1)时间,将新树插入线性表l需要Ο(n)时间,循环执行n-1 次,因此构造Huffman树的时间为Ο(n2)。综上所述,算法buildHuffmanTree的时间复杂度T(n)= Ο(n2)。
Huffman 编码可以在 Huffman 树中递归生成,算法 6-8 实现了这个操作。
算法 6-8 generateHuffmanCode
输入: Huffman 树根结点
输出: 生成 Huffman 编码
Huffman 树又称最优树,可以用来构造最优编码,用于信息传输、数据压缩等方面,是一类有着广泛应用的二叉树。
6.5.1 二叉编码树
在计算机系统中,符号数据在处理之前首先需要对符号进行二进制编码。例如,在计算机中使用的英文字符的 ASCII 编码就是 8 位二进制编码,由于 ASCII 码使用固定长度的二进制位表示字符,因此 ASCII 码是一种定长编码。为了缩短数据编码长度,可以采用不定长编码。其基本思想是:给使用频度较高的字符编较短的编码,这是数据压缩技术的最基本思想。如何给数据中的字符编以不定长编码,而使数据编码的平均长度最短呢?
首先分析第一个问题:如何对字符集进行不定长编码。在一个编码系统中,任何一个编码都不是其他编码的前缀,则称该编码系统的编码是前缀码。例如: 01, 10, 110, 111, 101 就不是前缀编码,因为 10 是 101 的前缀,如果去掉 10 或101 就是前缀编码。当在一个编码系统中采用定长编码时,可以不需要分隔符;如果采用不是前缀编码,因为 10 是 101 的前缀,如果去掉 10 或101 就是前缀编码。当在一个编码系统中采用定长编码时,可以不需要分隔符;如果采用不定长编码时,必须使用前缀编码或分隔符,否则在解码时会产生歧义。所谓解码就是由二进制位串还原字符数据的过程。而使用分隔符会加大编码长度,因此一般采用前缀编码。例 6-1 说明了这个问题。
例 6-1 假设字符集为{A, B, C, D},原文为 ABACCDA。
一种等长编码方案为 A:00 B:01 C:10 D:11,此时编解码不会产生歧义,过程如下。
编码: ABACCDA → 00010010101100
解码: 00010010101100 → ABACCDA
一种不等长编码方案为: A:0 B:00 C:1 D:01,由于此编码不是前缀码,此时在编解码的过程中会产生歧义。对于同一编码可以有不同的解码,过程如下。
编码: ABACCDA → 000011010
解码: 000011010 → AAAACCDA
000011010 → BBCCDA 错误!出现歧义。
为产生没有歧义的前缀编码,可以使用二叉编码树来实现。使用二叉树对字符集中的字符进行编码的方法是,将字符集中的所有字符作为二叉树的叶子结点;在二叉树中,每一个“父亲—左孩子”关系对应一位二进制位 0,每一个“父亲—右孩子”关系对应一位二进制位 1 ;于是从根结点通往每个叶子结点的路径,就对应于相应字符的二进制编码。每个字符编码的长度 L 等于对应路径的长度,也等于该叶子结点的层次数。例如对于例 6-1 中的每个字符可以按照图 6-15 所示的二叉编码树
进行编码。按照图 6-15 中的二叉编码树对 A、 B、 C、 D 四个字符进行编码,则 A 的编码是 0, B 的编码是 100, C 的编码是 11 , D的编码是 101。这个编码显然是一个前缀编码。
由于在二叉树中任何一个叶子结点都不会出现在根到其他叶子结点的路径上,那么按照上述二叉编码树的编码方法,任何一个叶子结点表示的编码都不会是任何其他叶子表示编码的前缀,因此由二叉编码树得到的编码都是前缀码。反过来如果要进行解码,也可以由二叉编码树便捷的完成。解码的过程是从头开始扫描二进制编码位串,并从二叉编码树的根结点开始,根据比特位不断进入下一层结点,当碰到0 时向左深入,为 1 时向右深入;到达叶子结点后输出其对应的字符,然后重新回到根结点,并继续扫描二进制位串直到完毕。还是如图 6-15 所示,此时将 ABACCDA 进行编码得到: 0100011111010。解码过程是从左到右扫描二进制位串。在读出最前端的 0 后,相应的从根结点到达结点,于是输出 A,重新回到根结点;依次扫描后续二进制位 100,到达叶子结点 B,于是输出 B,重新回到根结点;读出下一个二进制位 0,输出 A;读出 11 ,输出 C;读出 11 ,输出 C;读出 101,输出 D;最后读出 0,输出 A;此时二进制位串扫描完毕,相应的解码工作也完成,最后得到字符数据 ABACCDA。
6.5.2 Huffman 树及 Huffman 编码
在上一小节中介绍了如何对字符集进行不定长编码的方法,但是同时我们看到对于同一个字符集进行编码的二叉编码树可以有很多,只要叶子结点个数与字符个数对应即可。例如
对例 6-1 中字符即进行编码的二叉树就可以有,但不限于图 6-16 所示的二叉树。在这些不同的编码中哪个才是使得编码长度最小的呢?例如在例 6-1 中,选择图 6-15 中的编码方案比选择图 6-16 中的两种编码方案好。由于
字符 A、 B、 C、 D 分别出现了 3 次、 1 次、2 次、 1 次。使用图 6-15 的编码方案,编码的长度为 3×1+1×3+2×2+1×3=13;使用图 6-16( a)的编码方案,编码的长度为 3×3+1×2+2×3+1×1
=18;使用图 6-16( b)的编码方案,编码的长度为 3×3+1×2+2×1+1×3=16。
字符集中各种字符出现的概率是不同的,字符的出现概率决定了编码方案的选择。
当引入以上概念以后,求最佳编码方案实际上就抽象为求在叶子结点个数与权确定时带权路径长度最小的二叉树。那么什么样的树带权路径长度最小呢?
对于给定n个权值w1, w2, … wn( n≥2),求一棵具有n个叶子结点的二叉树,使其带权路径长度∑ WiLi最小。由于Huffman给出了构造具有这种树的方法,因此这种树称为Huffman树。
Huffman 树: 它是由 n 个带权叶子结点构成的所有二叉树中带权路径长度最小的二叉树, Huffman 树又称最优二叉树。
构造 Huffman 树的算法步骤如下:
① 根据给定的 n 个权值,构造 n 棵只有一个根结点的二叉树, n 个权值分别是这些二叉树根结点的权, F 是由这 n 棵二叉树构成的集合;
② 在 F 中选取两棵根结点树值最小的树作为左、右子树,构造一颗新的二叉树,置新二叉树根的权值=左子树根结点权值+右子树根结点权值;
③ 从 F 中删除这两颗树,并将新树加F:
④ 重复②、③,直到 F 中只含一棵树为止。
直观地看,先选择权值小的,所以权值小的结点被放置在树的较深层,而权值较大的离根较近,这样自然在 Huffman 树中权越大的叶子离根越近,这样一来,在计算树的带权路径长度时,自然会具有最小的带权路径长度,这种生成算法就是一种典型的贪心算法。用上述算法可以验证在例 6-1 中,图 6-15 所示的二叉树就是 Huffman 树,即例 6-1 中原文 ABACCDA 的最短编码长度为 13。
例6-2 假设有一组权值{7, 4, 2, 9, 15, 5},试构造以这些权值为叶子的 Huffman 树。构造 Huffman 树的过程如图 6-17 所示
使用二叉编码树进行编码,以字符出现的概率作为相应叶子的权值,当这棵二叉编码树是 Huffman 树时,所得到的编码称之为 Huffman 编码。例 6-1 中 A、 B、 C、 D 四个字符的Huffman 编码分别是 0、 100、 11、 101。
下面讨论构造 Huffman 树的具体实现。
Huffman 树的实现可以使用顺序的存储结构也可以使用链式的存储结构。前面给出了二叉树的链式存储实现,这里我们也给出 Huffman 树的链式存储结构的实现。
Huffman 树也是一棵二叉树,其结点可以继承二叉树的结点来实现,但是需要两个新的属性,即权值和编码。代码 6-2 定义了 Huffman 树的节点结构。
代码 6-2 Huffman树结点定义
package test;
public class HuffmanTreeNode extends BinTreeNode {
private int weight; // 权值
private String coding = ""; // 编码
// 构造方法
public HuffmanTreeNode(int weight) {
this(weight, null);
}
public HuffmanTreeNode(int weight, Object e) {
super(e);
this.weight = weight;
}
// 改写父类方法
public HuffmanTreeNode getParent() {
return (HuffmanTreeNode) super.getParent();
}
public HuffmanTreeNode getLChild() {
return (HuffmanTreeNode) super.getLChild();
}
public HuffmanTreeNode getRChild() {
return (HuffmanTreeNode) super.getRChild();
}
// get&set 方法
public int getWeight() {
return weight;
}
public String getCoding() {
return coding;
}
public void setCoding(String coding) {
this.coding = coding;
}
}构造 Huffman 树的过程可以通过算法 6-7 实现。
算法 6-7 buildHuffmanTree
输入: 结点数组 nodes
输出: Huffman 树的根结点
代码:
package test;
public class Test {
// 通过结点数组生成 Huffman 树
private static HuffmanTreeNode buildHuffmanTree(HuffmanTreeNode[] nodes) {
int n = nodes.length;
if (n < 2)
return nodes[0];
List l = new ListArray(); // 根结点线性表,按 weight 从大到小有序
for (int i = 0; i < n; i++) // 将结点逐一插入线性表
insertToList(l, nodes[i]);
for (int i = 1; i < n; i++) { // 选择 weight 最小的两棵树合并,循环 n-1 次
HuffmanTreeNode min1 = (HuffmanTreeNode) l.remove(l.getSize() - 1);
HuffmanTreeNode min2 = (HuffmanTreeNode) l.remove(l.getSize() - 1);
HuffmanTreeNode newRoot = new HuffmanTreeNode(min1.getWeight() + min2.getWeight());
newRoot.setLChild(min1);
newRoot.setRChild(min2); // 合并
insertToList(l, newRoot);// 新树插入线性表
}
return (HuffmanTreeNode) l.get(0);// 返回 Huffman 树的根
}
// 将结点按照 weight 从大到小的顺序插入线性表
private static void insertToList(List l, HuffmanTreeNode node) {
for (int j = 0; j < l.getSize(); j++)
if (node.getWeight() > ((HuffmanTreeNode) l.get(j)).getWeight()) {
l.insert(j, node);
return;
}
l.insert(l.getSize(), node);
}
}算法 6-7 说明:算法使用一个线性表l保存在生成Huffman树过程中森林F的所有树的根结点,并保持在线性表中这些根结点的权值从大到小有序。不难知道当线性表采用数组实现时方法insertToList的运行时间为Ο(n)。因此初始化将n个叶子结点插入线性表的时间为Ο(n2)。在有线性表l之后,取得最小权值的 2 个根结点,只需要Ο(1)的时间,合并 2 棵树需要Ο(1)时间,将新树插入线性表l需要Ο(n)时间,循环执行n-1 次,因此构造Huffman树的时间为Ο(n2)。综上所述,算法buildHuffmanTree的时间复杂度T(n)= Ο(n2)。
Huffman 编码可以在 Huffman 树中递归生成,算法 6-8 实现了这个操作。
算法 6-8 generateHuffmanCode
输入: Huffman 树根结点
输出: 生成 Huffman 编码
package test;
public class Test {
// 递归生成 Huffman 编码
private static void generateHuffmanCode(HuffmanTreeNode root) {
if (root == null)
return;
if (root.hasParent()) {
if (root.isLChild())
root.setCoding(root.getParent().getCoding() + "0"); // 向左为 0
else
root.setCoding(root.getParent().getCoding() + "1"); // 向右为 1
}
generateHuffmanCode(root.getLChild());
generateHuffmanCode(root.getRChild());
}
}

相关文章推荐
- 数据结构与算法(周鹏-未出版)-第六章 树-6.3 二叉树基本操作的实现
- 数据结构与算法(周鹏-未出版)-第六章 树-6.4 树、森林
- 数据结构与算法(周鹏-未出版)-第六章 树-6.1 树的定义及基本术语
- 数据结构与算法(周鹏-未出版)-第六章 树-6.2 二叉树
- 数据结构与算法(周鹏-未出版)-第六章 树-习题
- 为什么我要放弃javaScript数据结构与算法(第六章)—— 集合
- 第六章 6.5 图的遍历
- 【第六章】 AOP 之 6.5 AspectJ切入点语法详解 ——跟我学spring3
- 算法导论第六章6.5有限队列中的6.5-9课后练习
- 第六章 堆排序 6.5 优先队列
- 【第六章】 AOP 之 6.5 AspectJ切入点语法详解 ——跟我学spring3
- 【第六章】 AOP 之 6.5 AspectJ切入点语法详解 ——跟我学spring3
- 算法竞赛入门经典:第六章 数据结构基础 6.5小球下落
- 链表的实现 -- 数据结构与算法的javascript描述 第六章
- 【第六章】 AOP 之 6.5 AspectJ切入点语法详解 ——跟我学spring3
- 《Java实战开发经典》第六章6.5
- 算法导论 第六章 堆排序 习题6.5-8 k路合并排序
- 【第六章】 AOP 之 6.5 AspectJ切入点语法详解 ——跟我学spring3
- 第六章:iOS恶意软件和后门 ——6.5 针对iOS使用Metasploit
- 【第六章】 AOP 之 6.5 AspectJ切入点语法详解 ——跟我学spring3