ABAP程序优化
2017-10-10 10:42
190 查看
优化
降低CPU负荷(减少循环次数)、降低DB负荷(减少IO操作)、降低内存使用(减少内表大小)1.数据库
1. 不要使用 SELECT * ...,选择需要的字段, SELECT * 既浪费CPU,又浪费网络带宽资源,还需占用大量的ABAP内存2. 不要使用SELECT DISTINCT ...,会绕过缓存,可使用 SORT BY + DELETE ADJACENT DUPLICATES 代替
3. 少用相关子查询,因为子查询对外层查询结果集中的每条记录都会执行一次
4. 少用嵌套SELECT … ENDSELECT,可以使用联合查询或FOR ALL ENTRIES来替换,减少循环次数
5. 如果确定只查一条数据时,使用 SELECT SINGLE... 或者是 SELECT ...UP
TO 1 ROWS ...
6. 统计时,直接使用SQL聚合函数,而不是将数据读取出来后在程序里再进行统计
7. 使用游标读取数据,这样省掉了将从数据库中的取记录放入内表的INTO语句这一过程开销
8. 多使用inner join,必要时才使用left join
9. inner join获取数据时,尽量不要用太多的表关联,特别是大表关联,关联顺序为:小表-大表
10.where 条件里面多用索引、主键,顺序也要遵循小表-大表
11.inner join条件放置的位置应该按照 On、Where、Having的顺序放,因为SQL条件的的执行一般是按这个顺序来执行的,将条件放在最开始执行,则可过滤掉大部数据;但要注意Left
Outer Join,是否可以将ON中的条件移动到Where从句则要考虑(如果真能放在Where从句中,则应该使用Inner Join,而非Left Outer Join,因为Where条件会过滤掉那些包括在右表中不存在的左表数据),因为此时条件放在On后面与放在Where语句后面结果是不一样的(因为不管on中的条件是否为真,左表中在右边表不存在的数据也会被返回,但如放在where条件中,则会对On产生的数据再次过滤的条件,会滤掉不满足条件的记录——包括左表在右表中找不到的记录,这时已经没有left
join的含义)
12. 要根据主键或索引字段查找数据,且WHERE从句中的条件字段需按INDEX字段顺序书写,且将索引字段条件靠前(左边),如:在VBFA表中查找SO所对应的交货单DN,因为如果直接到LIPS中找时,SO的订单中号与行号在LIPS中非主键,但在VBFA是部分主键(VBFA中根据部分主键查找 SO
-> DN; 根据索引查找 SO -> PO,VBFA-VBELN+VBFA-POSNN组合字段上创建了索引,即根据SO找PO时,不要从EKKN关联表中查找,而是通过VBFA中查找。后来查看EKKN,发现在VBELN+VBELP字段上创建了索引,所以从VBFA与EKKO查找应该差不多,主要看哪个表数据量少的问题了)
检查条件组合字段是否是主键,或者是上在上面创建了索引,避免条件组合字段即不是主键又没有索引
13. SELECT语句WHERE条件,应该先将主键相关条件放在前面 然后按照比较符 = 、< 、>、 <> 、LIKE IN 的顺序排列WHERE条件
14.使用部分索引字段问题:如果一个索引是由多个字段组成的,只使用一部分关键字段来进行查询时,也是可以使用到索引,但使用时要注意要按照索引定义的顺序且取其前面部分
15. 请根据索引字段进行ORDER BY,否则通过程序进行SORT BY。与其在数据库在通过非索引字段进行排序,不如在程序中使用SORT BY语句进行排序,因为此情况下应用服务器上的执行速度要比数据库服务器快(应用服务器上采用的是内存排序)
16.避免在索引字段上使用:
l not、<>、!=、IS NULL、IS NOT NULL,可以用> 与 < 来替代
l 避免使用 LIKE,但LIKE '销售组1000'和LIKE '销售组1000%'可以用到,而LIKE '%销售组1000'(百分号前置)则用不到索引
l 不要使用OR来连接多个索引字段(但同一字段多个值之间可以使用OR);对于同一索引字段,可以使用IN来替代OR:


l带有BETWEEN 的WHERE 条件不能通过索引来搜索?也可使用IN代替
17.避免使用以下语句,因为使用这些语句时,不能使用 Table Buffer:
l Aggregate expressions
l Select distinct
l Select … for update
l Order by、group by、having从句
l Joins,使用JOIN时,会绕过SAP缓存,可以使用FOR
ALL ENTRIES来代替
l WHERE从句中使用Sub queries(子查询)
l WHERE从句中使用IS NULL条件
18.在下面情况下使用FOR ALL ENTRIES IN:
l在循环内表 LOOP...AT Itab中循环访问数据库时
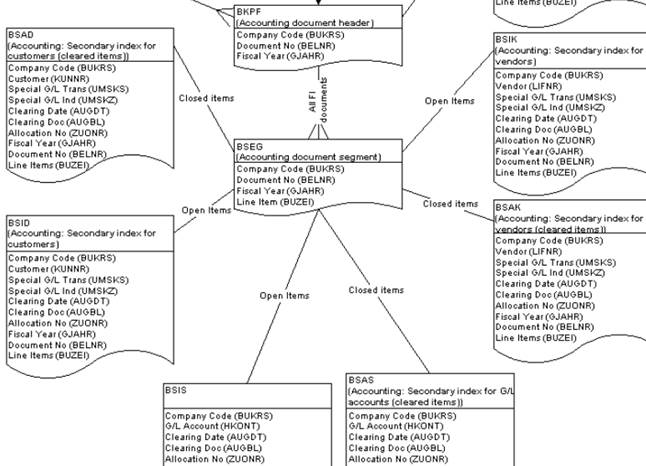
l簇表是禁止JOIN的表类型, 当需要联接簇表查询数据时,如:BSEG(会计凭证)、KONV(条件表)
簇表一般是由多个表组成,簇表中的数据来自于多个表,有点像视图,但不能直接通过簇表进行数据维护
lJOIN超过3个表会出现性能问题, 当使用JOIN联接的表超过3个时
l如果两个表的数据非常大时(上百万),使用JOIN进行联合查询会很慢,此时改用FOR ALL ENTRIES IN
19.使用内表批量操作数据库,而不要使用工作区一条条操作,如:
SELECT ... INTO TABLE itab
INSERT dbtab FROM TABLE itab
DELETE dbtab FROM TABLE itab
UPDATE/MODIFY dbtab FROM TABLE itab
20.如果你使用 CLIENT SPECIFIED,需在WHERE从句第一个位置上指明 MANDT条件,否则使用不到索引
