基于FOFE的命名实体识别局部检测方法
2017-10-07 17:04
621 查看
A Local Detection Approach for Named Entity Recognition and Mention Detection
背景
这篇文章主要是基于2015年提出的一种变长编码方法FOFE(Fixed-size Ordinally Forgetting Encoding)提出来的一个解决NER问题的一个方法。通过对句子的切分词段以及其上下文进行FOFE编码表示后进行训练分类,再通过一层encode继续训练以得到更细粒度的结果。下面先简单介绍FOFE方法后再具体介绍文中处理方法。FOFE介绍
传统的神经网络模型要求输入是固定长度的向量形式,而对于自然语言不固定长度的序列,需要通过一种变长编码形式将它编码成固定长度的向量。由于语言具有前后依赖关系,传统的词袋模型并不能表示这种性质,而近年来提出的RNN模型起到了有效的效果,不过也存在着训练速度慢和梯度弥散等问题。所以作者提出了一种叫FOFE的变长编码方法。给定一个序列S=[w1,w2,...,wT] ,每个词wt表示成One-hot向量et,然后依次计算zt(1≤t≤T), 计算公式如下:
zt=α⋅zt−1+et(1≤t≤T)(z0=0)
zt 表示的是从位置1到位置t这段序列的编码,α(0<α<1)表示遗忘因子,表示前面序列对当前词的影响,实际上它的指数也反应了词在序列中的次序信息。具体例子如下图所示:

作者在论文中也证明了当α≤0.5时,FOFE编码是唯一的,当0.5<α<1时,FOFE几乎也是唯一的,只有当α取某些值时会存在冲突,但这种冲突也是建立在一个词的上下文重复的出现这种在自然语言中少出现的情况,因此也几乎可以忽略不计的。
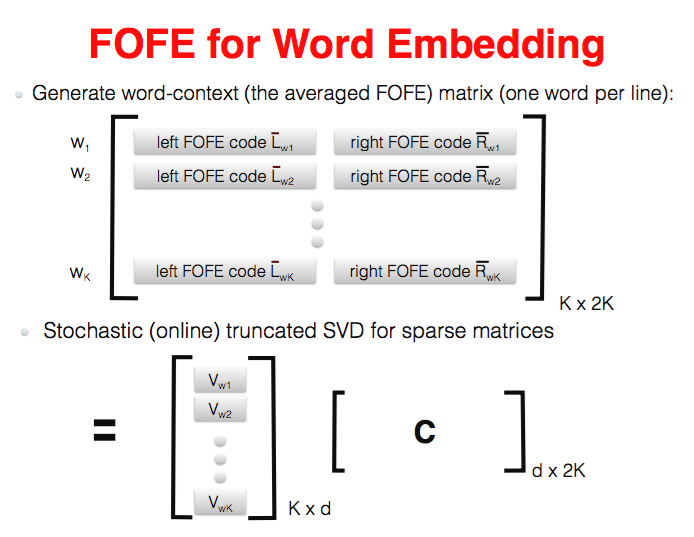
通过这种方式,编码既保留了上下文信息,也保留了其前后依赖关系,可以说几乎无损的。利用这种编码方法,后面可以为很多NLP任务提供帮助,比如Word Embedding,NER,Language Model等等,作者在论文中就是基于Mikolov提出的FNNLM进行改进,并且优胜于原来的FNNLM、RNNLM和LSTM等。对于Word Embedding任务,FOFE也提供了一种简单有效的方法,假设vocabulary共有K个词,那么对于语料中每个词w,对其上下文若干词分别作FOFE编码,(如果w出现多次便用词w所有的上下文FOFE编码取平均)可以得到K*2K的contex encodet矩阵,再对其进行SVD分解就可以得到Word Embedding了。
FOFE-NER
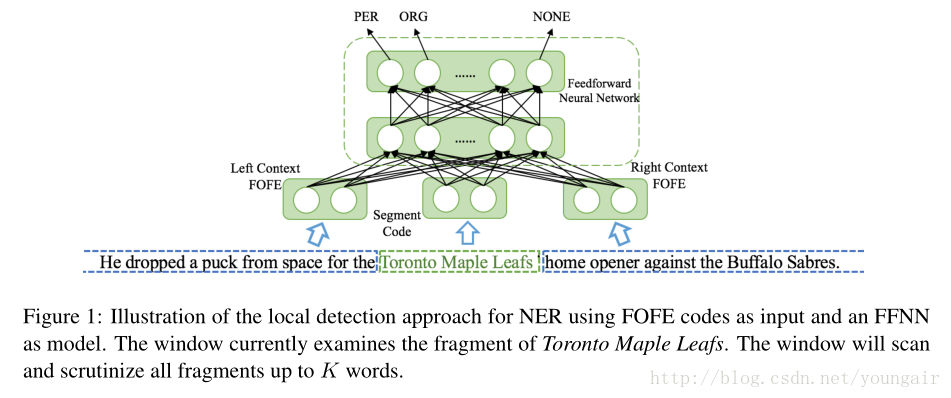
如图所示,作者是把一个序列按照K个词划分为一个片段,整个序列就被划分为上文L,片段S,下文R三部分。然后分别对其进行FOFE编码成定长编码,利用神经网络进行训练预测该片段是否是命名实体。作者分别从word-level和character-level两个层面的特征去验证。
Word-level
把上下文分成加不加片段信息进去,即(L+S, S, S+R)或(L, S, R),然后分别用区别大小写和不区分大小写的Word-Embedding进行训练。
Character-level
主要考虑正向编码和反向编码两种形式。
在预测过程中,如果一个segment是实体类型,则会得到一个模型给出的分数。由于命名实体长度不是固定的,所以可能出现Segment中K个word只包括部分实体(如for the Toronto),或其中产生实体的嵌套(如Toronto Maple Leaf 和Toronto)。对于这种情况,有以下两种解决方案选择:
higest-first: 检查序列中的每个词,如果它被多个segment所包含,只取最高分数所属的实体类型。
longest-first: 检查序列中的每个词,如果它被多个segment所包含 ,只取片段最长所属的实体类型。
Second-Pass Augmentation
由于第一轮的预测只用到上下文信息,所以在第一轮预测的基础上增加第二轮的训练,把第一轮预测的所有实体词替换成其对应的实体类型,利用这些类型进行再次预测,相当于利用了实体类型之间的信息进行预测。最后把两次预测分数进行一个线性插值,再decode得到结果。Result
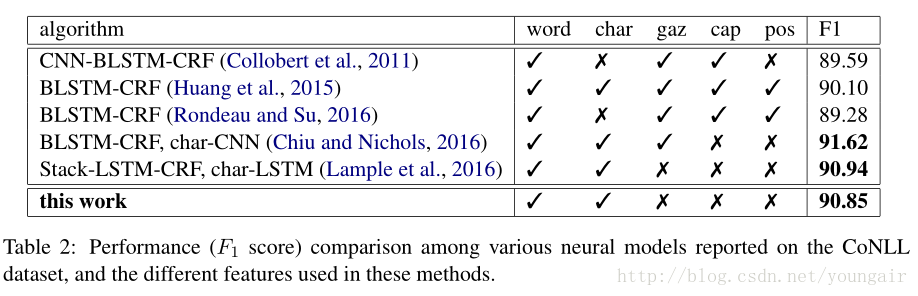
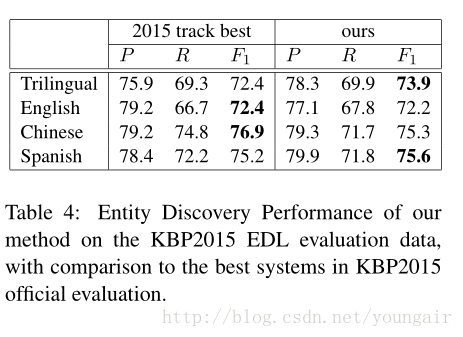
个人思考
本文的动机是借鉴人类的思维方式,浏览文中某个片段,结合其上下文进行局部的检测判断是否为实体类型,而不是把整个句子进行解码再判断(这里可能指的是Seq2Seq的模型,但从论文来看这个模型encode上下文信息时好像也几乎encode全文了,这个回头看代码再确认一下)。由于还没读过其他深度学习用于NER的论文,似乎这种通过上下文来预测实体类型的做法并不是很创新,主要还是体现在特征选择上,而且也在于FOFE编码使得上下文依赖得到有效的保留。在Second-pass部分是否可以换成CRF层呢?觉得同样是处理实体类型间的转化关系。
主要挑选这篇论文还是因为它提及的FOFE编码方法,感觉比较有意思,值得关注一下。其中也存在一些可改进的地方,对于较长的文本,α 连乘之后可能太小而丢失了一些信息,可以通过双向计算来保证精度。但这样会否增加编码冲突的可能性?
参考论文
Xu M, Jiang H. A FOFE-based Local Detection Approach for Named Entity Recognition and Mention Detection[J]. 2016.
Shiliang Zhang, Hui Jiang, Mingbin Xu, Jun-feng Hou, and Lirong Dai. 2015a. A fixed-size encoding method for variable-length sequences with its application to neural network language models. arXiv preprint arXiv:1505.01504.
Shiliang Zhang, Hui Jiang, Mingbin Xu, Junfeng Hou,and Lirong Dai. 2015b. The fixed-size ordinally-forgetting encoding method for neural network lan-guage models. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Association for Computational Linguistics (ACL).
源代码 Tensorflow 和Pytorch

相关文章推荐
- 命名实体识别(named entity recognition )基于统计方法的技术比较
- 关于冰壶的识别检测方法基于Haar的特征检测
- 【转】基于VSM的命名实体识别、歧义消解和指代消解
- 基于统计的命名实体识别特征选择
- 基于深层神经网络的命名实体识别技术
- 基于深层神经网络的命名实体识别技术
- 基于深层神经网络的命名实体识别技术
- 基于深层神经网络的命名实体识别技术
- 基于crf的命名实体识别的一部分总结加文本分类大致流程
- 基于深层神经网络的命名实体识别技术
- 基于深层神经网络的命名实体识别技术
- 基于深层神经网络的命名实体识别技术
- 【工程处理技巧一篇】基于半规则数据的命名实体消歧识别【未完】
- 基于CRF工具的机器学习方法命名实体识别的过
- 基于规则的命名实体识别
- 基于深层神经网络的命名实体识别技术
- 基于VSM的命名实体识别、歧义消解和指代消解
- 命名实体识别的两种方法
- 命名实体识别方法汇总
- 基于深层神经网络的命名实体识别技术