深度学习笔记(6)——CNN中的卷积block
2017-10-06 13:44
225 查看
因为最近写各种论文所以一直没有更新,准备先开个坑之后再填。这篇博客将是CNN网络的终结篇,之后将会开始介绍RNN网络。
CNN网络最初诞生的时候结构比较简单,都是几个卷积层堆叠一下。但是微软的Resnet和谷歌的Inception系列网络把CNN带到一个设计各种block反复调用的时代。比起传统的CNN网络,新的block设计能够在简化运算的同时保持甚至提高网络的泛化能力。那么本篇博客就来介绍一下现在各种主流block的结构和原理,主要包括Resnet系列(ResNet, ResNeXt, DenseNet, SeNet, ShuffleNet)和GoogleNet系列(Inception-v1, Inception-v2, Inception-v3, Inception-v4, Xception)。
最后Inception-v2的网络结构长成这样,就是把v1的5×5卷积核拆成了两个3×3的卷积核:
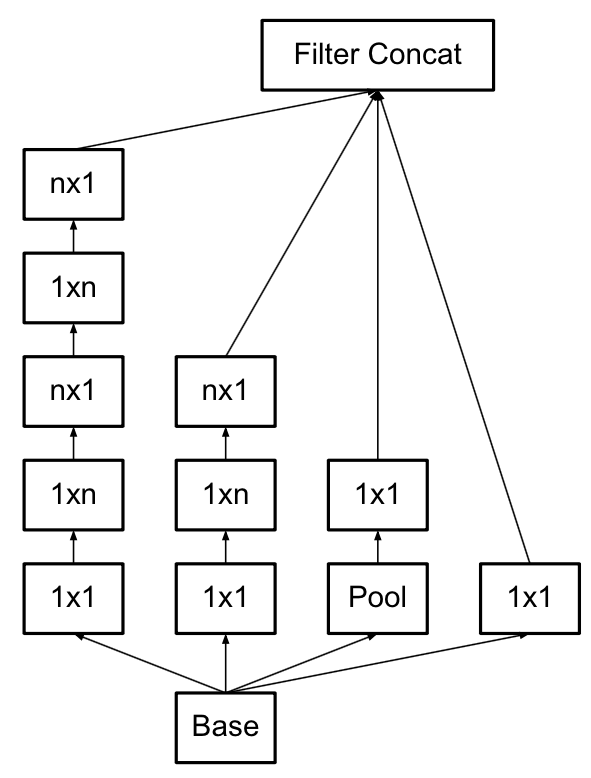
当然除了这种思想是通用的,除了3×3的卷积核以外,v3还把7×7等卷积核也进一步分解为两个了,此外把图像的输入大小从224×224改为了299×299,来进一步精心的控制了feature map的尺寸。
综上其实用的比较多的Inception-v2系列,v2应该是性能和简洁度上比较折中的一个网络,后面的Inception网络写起来确实比较繁琐。
CNN网络最初诞生的时候结构比较简单,都是几个卷积层堆叠一下。但是微软的Resnet和谷歌的Inception系列网络把CNN带到一个设计各种block反复调用的时代。比起传统的CNN网络,新的block设计能够在简化运算的同时保持甚至提高网络的泛化能力。那么本篇博客就来介绍一下现在各种主流block的结构和原理,主要包括Resnet系列(ResNet, ResNeXt, DenseNet, SeNet, ShuffleNet)和GoogleNet系列(Inception-v1, Inception-v2, Inception-v3, Inception-v4, Xception)。
GoogleNet系列
GoogleNet是比较经典的一个系列,主要包括Inception和Xception两个子系列,GoogleNet系列的网络特点在于融合不同尺度的feature map和使用group convolution的思想。Inception-v1
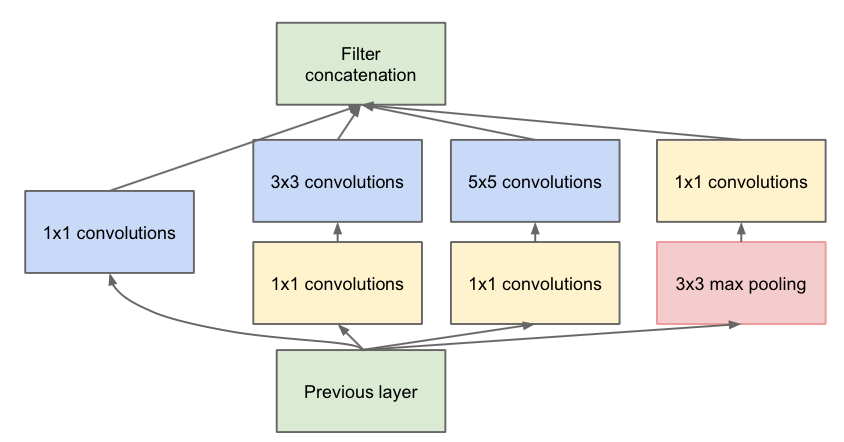
Inception-v1是第一代GoogleNet,其block没有太多特色的地方,但是相比于VggNet、AlexNet这种方方正正的上古网络,Inception-v1融合不同尺寸的feature map和感受野。实现方式是用三个不同size的卷积核(1×1,3×3,5×5)去得到不同尺度的feature map,最早的v0版本的inception就是直接用三个卷积核进行卷积,v1做了一个微小的改进就是引入了1×1的卷积层来控制feature map的channel,减少参数量。Inception-v1还有一个pooling层分支,如果不做pooling这个pooling是不需要的,并且卷积核的stride也为1;如果要做pooling的话那么max pooling和卷积核的stride需要一致,基本大部分情况都会设置成2。最后通过concatenate不同感受野的feature map就得到了block的输出,这个设计的好处可以得到不同感受野尺寸的特征。Inception-v2
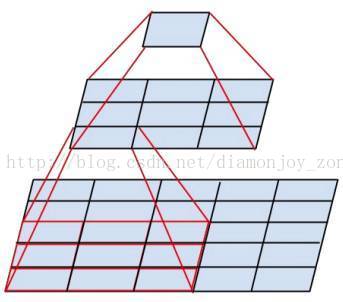
Inception-v2是Inception-v1的改进版,改动浮动不大,主要的思想是认为两个3×3的卷积核串联在感受野上等效于一个5×5的卷积核,但是卷积核参数量从25减少到了18。最后Inception-v2的网络结构长成这样,就是把v1的5×5卷积核拆成了两个3×3的卷积核:
Inception-v3
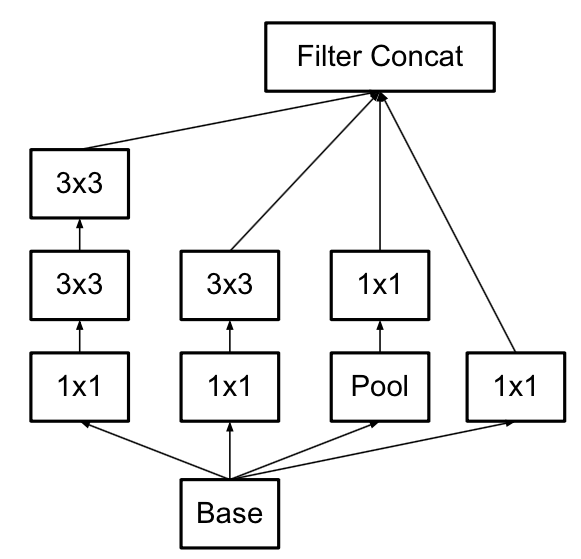
Inception-v3是Inception-v2的改进版,改进同样也不大,就是进一步做了卷积核的拆解。一个很直白的思想就是一个3×3的卷积核可以拆解为1×3和3×1的串联,而保证感受野不变,但是参数量从9变成6。Inception网络中有大量的3×3的卷积核,所以这个操作最终能够减少蛮多参数量和计算量。最终Inception-v3的结构为:当然除了这种思想是通用的,除了3×3的卷积核以外,v3还把7×7等卷积核也进一步分解为两个了,此外把图像的输入大小从224×224改为了299×299,来进一步精心的控制了feature map的尺寸。
Inception-v4
Inception-v4主要是引入了Resnet的shortcut思想,得到了一个Inception-Resnet v2网络,这个在之后的Resnet里面介绍一下shortcut就行。另外一个就是进一步改造了一下Inception网络,我感觉这些改造并不漂亮,所以不介绍了,感兴趣的可以自己看原论文。综上其实用的比较多的Inception-v2系列,v2应该是性能和简洁度上比较折中的一个网络,后面的Inception网络写起来确实比较繁琐。
Xception

相关文章推荐
- 数据挖掘、目标检测中的cnn和cn---卷积网络和卷积神经网络
- 基于手工打造的卷积CNN的性别识别
- 卷积神经网路(CNN)
- CNN中的卷积操作的参数数计算
- 深度卷积网络CNN与图像语义分割
- CNN-卷积反卷积
- 深度学习 —— 卷积神经网路 CNN
- CNN 中, 1X1卷积核到底有什么作用呢?
- 深度卷积网络CNN与图像语义分割
- cnn神经网络卷积层可视化
- CNN详解(卷积层及下采样层)
- CNN卷积核
- 卷积神经网络CNN:Tensorflow实现(以及对卷积特征的可视化)
- 深度学习与自然语言处理之四:卷积神经网络模型(CNN)
- 深度卷积网络CNN与图像语义分割
- cnn卷积核存储--转载
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算
- 为什么使用卷积层替代CNN末尾的全连接层
- 深度学习, cnn,本质不是深而是卷积pooling,验证。
- TensorFlow 中的卷积网络(cnn)