【视频变化检测】2017CVPR Spatio-Temporal Self-Organizing Map Deep Network for Dynamic Object Detection from
2017-09-28 18:01
851 查看
Spatio-Temporal Self-Organizing Map Deep Network for DynamicObject Detection from Videos
Yang Du1,Chunfeng Yuan1∗,Bing Li1, Weiming Hu1 and Stephen Maybank2CAS Centerfor Excellence in Brain Science and Intelligence Technology,NationalLaboratory of Pattern Recognition, Institute of Automation, Chinese Academy ofSciences;Universityof Chinese Academy of Sciences, Beijing, China 针对动目标检测问题,更好的探索空域和时域的特性来描述复杂的背景。提出Spatio-Temporal Self-Organizing Map(STSOM)深度网络。总结复杂背景含有两个属性:1、 全局背景的空间变换,包括相机的变焦、抖动等。认为背景运动的空域属性。2、 局部背景随着时间的变化。主要指背景的动态属性,比如河流、泉水和坏天气等。认为为背景运动的时域属性。本文基于SOM进行背景描述。SOM(Self-Organizing Map)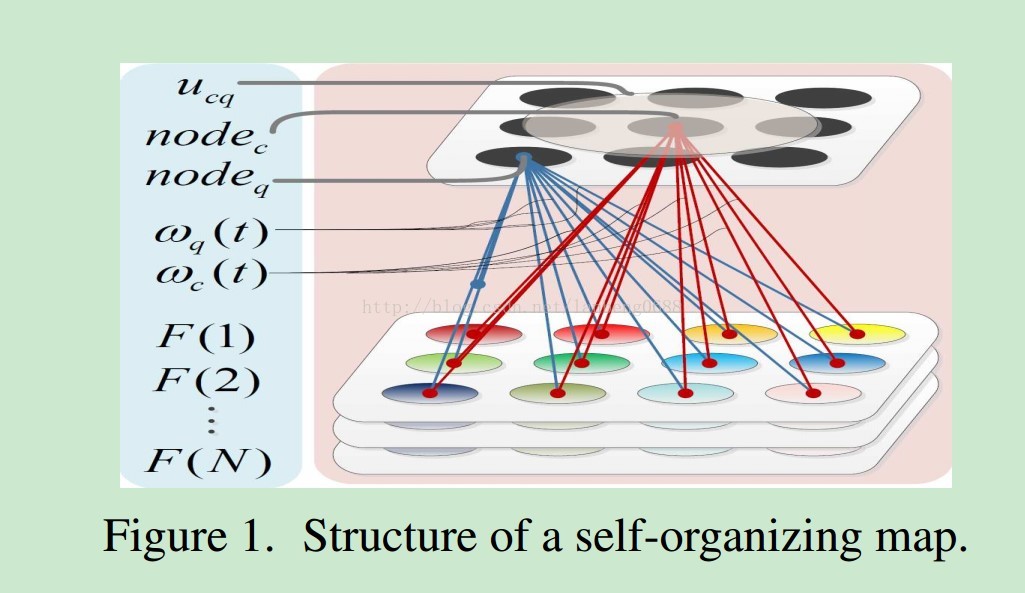 一个通常的SOM单元包含一系列神经节点,可以通过自己组织的神经节点的权重来学习输入刺激的特征模式。输入的元素与所有的节点是全链接关系,其中的关系可以用一个权重向量来表示。特殊地,获胜节点c被定义为其权重向量与输入图像有最小的距离。公式如下:
一个通常的SOM单元包含一系列神经节点,可以通过自己组织的神经节点的权重来学习输入刺激的特征模式。输入的元素与所有的节点是全链接关系,其中的关系可以用一个权重向量来表示。特殊地,获胜节点c被定义为其权重向量与输入图像有最小的距离。公式如下: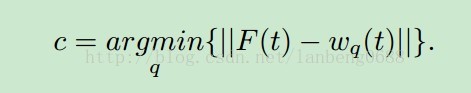 SOM的学习规则为找到获胜节点,然后更新获胜节点和领域节点的权重。则可以考虑到领域平滑信息。其权重更新公式如下:
SOM的学习规则为找到获胜节点,然后更新获胜节点和领域节点的权重。则可以考虑到领域平滑信息。其权重更新公式如下: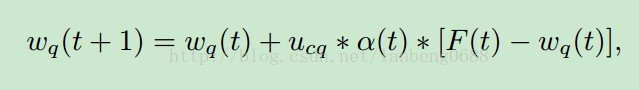
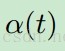 为学习率,
为学习率,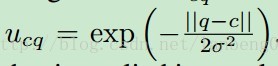 为领域函数,可保留空间拓扑结构。 STSOMDeep Network for Dynamic Object Detection
为领域函数,可保留空间拓扑结构。 STSOMDeep Network for Dynamic Object Detection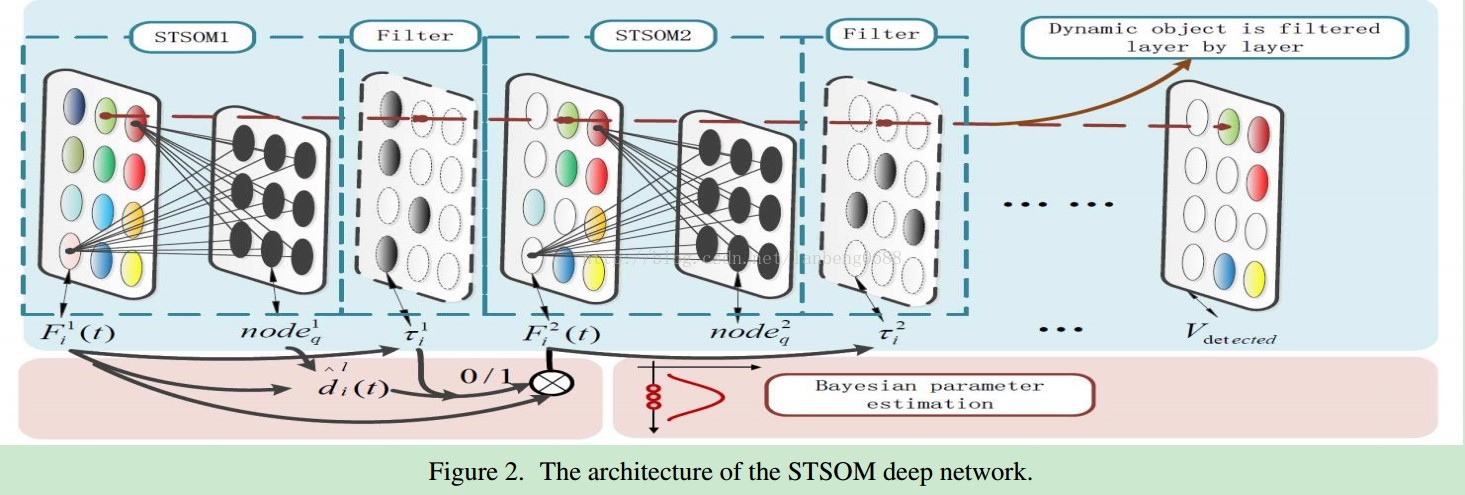 整体结构输入图像连接一个SOM,然后通过阈值得到之后的图像,再经过多层SOM得到最后的结果。通过多层数来更好的刻画复杂的背景。不同于SOBS,每一层的节点数目很少,只有3*3,所以需要更深的网络结构来刻画背景。1. 预训练整个视频图像都被用作预训练STSOM,先转化为HSV空间,在笛卡尔空间中计算像素点i与节点之间的距离:
整体结构输入图像连接一个SOM,然后通过阈值得到之后的图像,再经过多层SOM得到最后的结果。通过多层数来更好的刻画复杂的背景。不同于SOBS,每一层的节点数目很少,只有3*3,所以需要更深的网络结构来刻画背景。1. 预训练整个视频图像都被用作预训练STSOM,先转化为HSV空间,在笛卡尔空间中计算像素点i与节点之间的距离: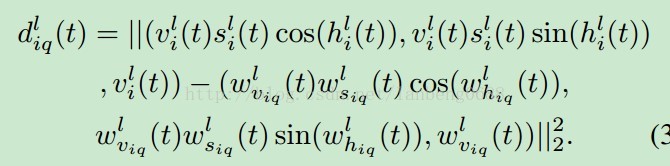
将会得到一个D的距离大矩阵。分为空域时域来分开更新权重。1) 空域权重更新对于同一帧的不同像素来说,可以用来刻画背景的空域特性,则每一帧的距离为这一帧所有的像素到节点p的和,找到最小距离的节点,即为获胜节点,再根据更新权重规则进行更新。离获胜权重越近,影响越大,距离越远,影响越小。2) 时域权重更新对于同一像素的不同帧,可以刻画背景的时域特性,则每一个像素点的获胜节点为同一像素不同帧的对于节点p的最小距离的节点。结合空域和时域的更新,使得STSOM有了很好的背景表达能力。3) 前向传递(forward propagation)通过一层一层的预训练,我们已经有了很多的STSOM层。对于每一层来说,我们可以获得结合了空域和时域信息的阈值,用来过滤图像是否为背景。首先,我们通过平均所有的图像来获取一个粗的背景模型,然后利用贝叶斯参数估计方法来获取最后的背景模型。(没看懂这里怎么估计的)利用这个背景模型,进行前向传递,通过一层,将最大的空域节点距离除以所有的像素个数设为空域阈值,最大的时域节点距离设为时域阈值,对空域阈值和时域阈值取平均。然后通过阈值,可获得下一层的输入。对于之后的层,再分别通过权重更新和背景前向传递进行一层一层的更新。获得最终每层的初始结果。2.精调(Fine-tuning)为了让网络更适用于复杂场景的变化,在精调步骤中,输入一个新的视频帧,对每一层的权重进行更新,不更新阈值。更新公式为:
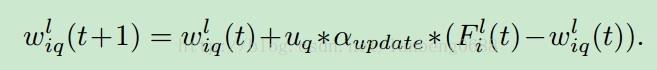 与预训练一样,但是α会设置的更小一些3.动目标检测(Dynamic Object Detection)通过之前的训练会得到一个描述背景的网络,然后对于这个网络来说,输入一个新的帧,通过阈值,就会得到最后的动目标检测结果。越深的层数会更精确的表达背景模型。 实验结果l 动背景,包括河流、运动的树、泉水、坏天气、相机抖动等等,有很大的提升效果。l 热流、阴影也可以不错的解决l 间断物体运动和低帧情况,达到最好的效果,因为模型可以动态实时更新。l PTZ夜晚视频,效果不佳l 整体效果超过了state-of-art
与预训练一样,但是α会设置的更小一些3.动目标检测(Dynamic Object Detection)通过之前的训练会得到一个描述背景的网络,然后对于这个网络来说,输入一个新的帧,通过阈值,就会得到最后的动目标检测结果。越深的层数会更精确的表达背景模型。 实验结果l 动背景,包括河流、运动的树、泉水、坏天气、相机抖动等等,有很大的提升效果。l 热流、阴影也可以不错的解决l 间断物体运动和低帧情况,达到最好的效果,因为模型可以动态实时更新。l PTZ夜晚视频,效果不佳l 整体效果超过了state-of-art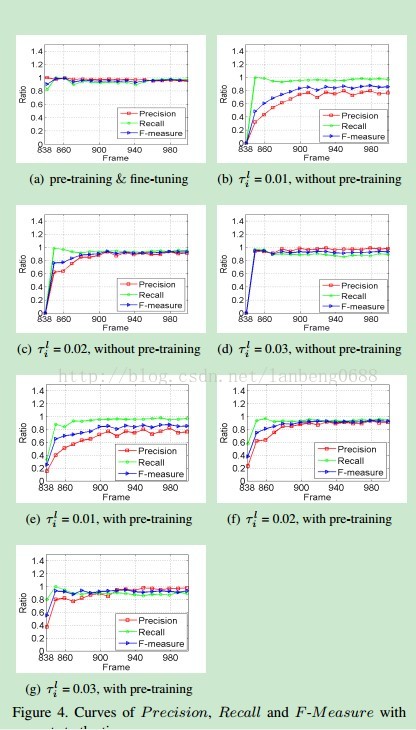 一堆实验证明,pre-training的阈值效果比较好,相对大的阈值效果更好一些。
一堆实验证明,pre-training的阈值效果比较好,相对大的阈值效果更好一些。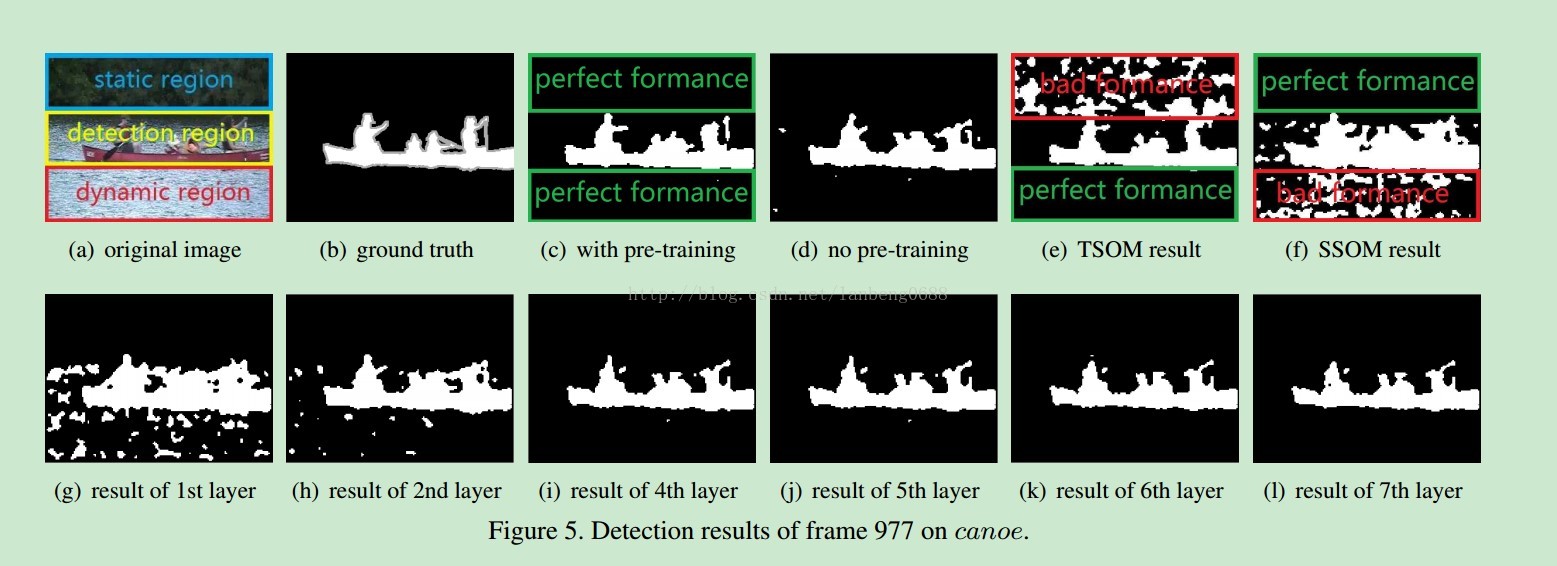 每层结果,可以看出,STSOM对于动态背景的有效表达能力。
每层结果,可以看出,STSOM对于动态背景的有效表达能力。

相关文章推荐
- 目标检测--A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 【文献阅读】Perceptual Generative Adversarial Networks for Small Object Detection –CVPR-2017
- MSCNN 论文解析(A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- MSCNN 论文解析(A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 目标检测“A MultiPath Network for Object Detection”
- 多尺度R-CNN论文笔记(5): A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- Deep Neural Networks for Object Detection(基于DNN的对象检测)
- [论文解读] MSCNN: A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 目标检测--PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- 论文笔记 MSCNN:A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- Deep Saliency:Multi_Task Deep Neural Network Model for Salient object detection
- 【Paper】DeepSaliency: Multi-Task Deep NeuralNetwork Model for Salient Object Detection
- 目标检测--PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- 目标检测--Single-Shot Refinement Neural Network for Object Detection
- DeepID-Net:multi-stage and deformable deep convolutional neural network for object detection
- CVPR 2017—Deep Joint Rain Detection and Removal from a Single Image
- 【论文笔记】视频物体检测(VID)系列 FGFA:Flow-Guided Feature Aggregation for Video Object Detection
- 视频目标检测--Flow-Guided Feature Aggregation for Video Object Detection
- 车辆检测“Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monoc”
- 视频目标检测 - Object Detection from Video Tubelets with Convolutional Neural Networks