视频目标检测 - Object Detection from Video Tubelets with Convolutional Neural Networks
2016-10-20 15:28
661 查看
CVPR2016
code: https://github.com/myfavouritekk/vdetlib
基于静态图像的CNN目标检测问题已经很多人研究。而基于视频的CNN目标检测问题则是刚刚起步。主要问题是目标检测和跟踪的有效结合。

针对视频中的目标,单独的检测和单独的跟踪都会有波动。
我们的视频目标检测框架图:
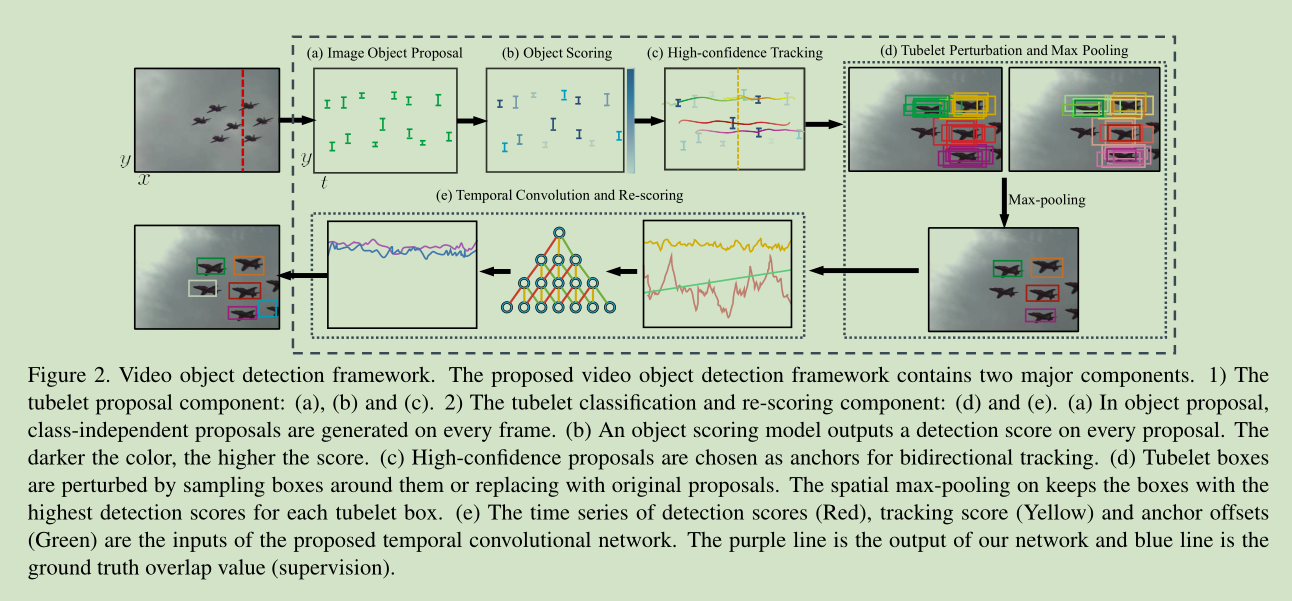
主要包括两个模块:
1 a spatio-temporal tubelet proposal module
2 a tubelet classification and re-scoring module
3.2. Spatio-temporal tubelet proposal
tubelet proposal module 包含三个步骤:
Step 1: Image object proposal,对每帧图像使用 Selective Search (SS) 进行候选区域提取。然后使用 R-CNN 对候选区域进行一个过滤,将明显非目标区域过滤,大约 6.1%的候选区域留下来。
Step 2: Object proposal scoring,使用经 DET 任务微调的 GoogLeNet 作为检测器,使用第五层池化特征训练SVM分类器,对剩下的候选区域打分。
Step 3: High-confidence proposal tracking 这里使用文献【36】中的跟踪算法来对候选区域进行跟踪,跟踪的初始位置 “anchors”使用上一个步骤中 most confident box proposals,对跟踪还进行了一些处理,使其更加稳定。
3.3. Tubelet classification and rescoring
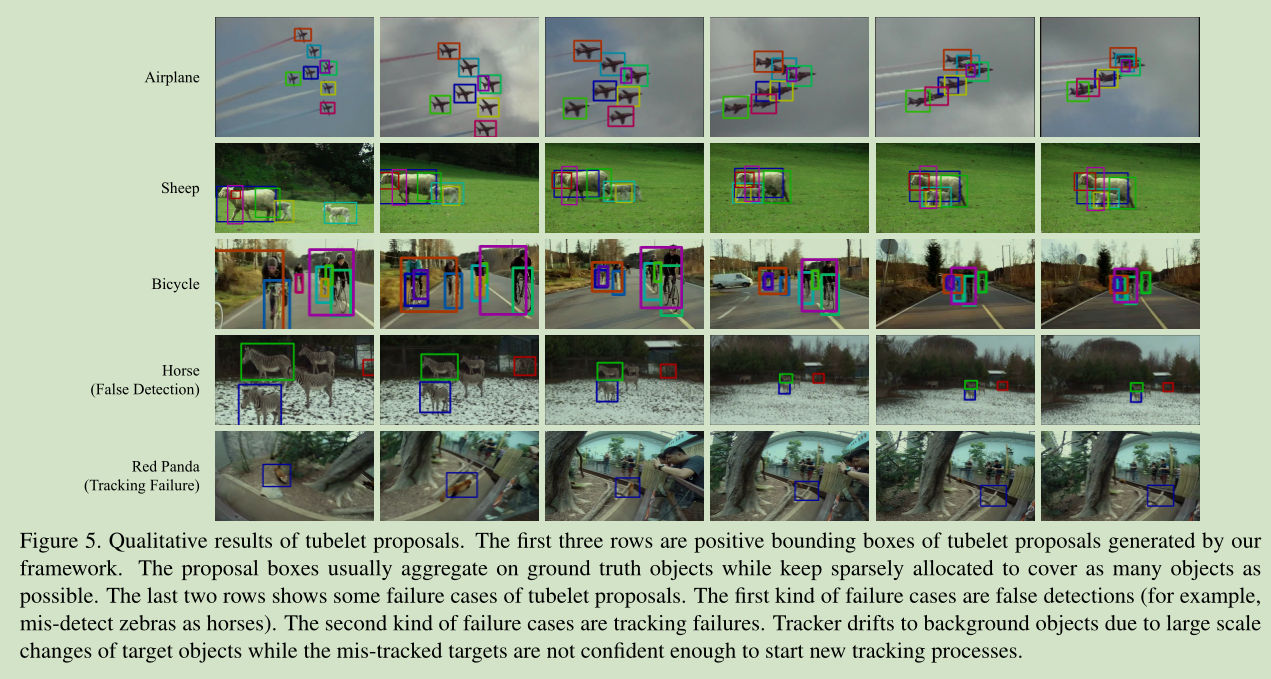
经过 tubelet proposal module处理,对每个类,我们得到了 tubelets with high-confidence anchor detections,接下来怎么做?一个很直接的方法就是对 tubelet 中的每个矩形框进行分类。这个方法和基于R-CNN静态图像目标检测效果差不多。原因大致有4点:
1) tubelets 中的矩形候选区域数量要比 Selective Search 少很多,这可能会让我们漏掉一些目标。
2) 针对静态图像训练的目标检测器 对于目标位置的变化比较敏感,如图1(a)所示,所以tubelets 中的矩形候选区域的分数比较低。
3) 在跟踪过程中,我们进行了 proposal sup-pression,这也可能是我们丢失一些目标。
4)我们应该嵌入 temporal information是的检测更稳定。
为了解决 tubelet classification 中的这些问题,我们设计以下步骤来增加候选区域,提高检测位置稳定性,嵌入时间信息。augment proposals,increase spatial detection robustness and incorporate temporal consistency into the detection scores
Step 4. Tubelet box perturbation and max-pooling
The tubelet box perturbation and max-pooling process is to re-
place tubelet boxs with boxes of higher confidence.
针对视频中tubelet 矩形框检测分数的不稳定性,我们在tubelet 矩形框 邻域做目标检测,将检测分数最高的矩形框替代tubelet原来的矩形框。从而达到降低tubelet 矩形框检测分数的不稳定性。
Step 5. Temporal convolution and re-scoring
这里我们提出了一个 Temporal Convolutional Network (TCN) 来嵌入时序信息来提高tubelet 矩形框检测分数的稳定性。
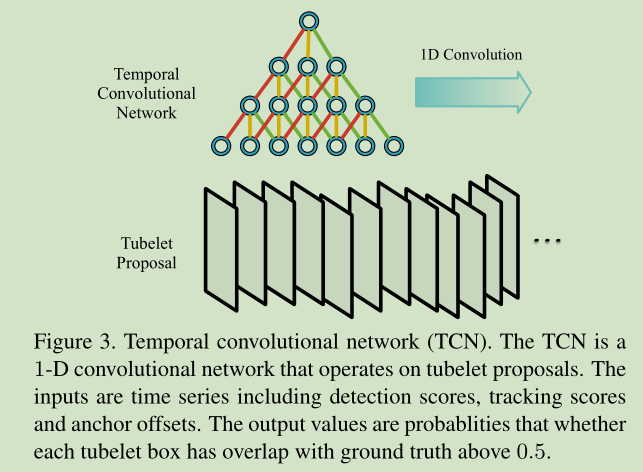
有点类似高斯平滑的意思啊,就是根据相邻的检测分数来提高检测的稳定性。
code: https://github.com/myfavouritekk/vdetlib
基于静态图像的CNN目标检测问题已经很多人研究。而基于视频的CNN目标检测问题则是刚刚起步。主要问题是目标检测和跟踪的有效结合。
针对视频中的目标,单独的检测和单独的跟踪都会有波动。
我们的视频目标检测框架图:
主要包括两个模块:
1 a spatio-temporal tubelet proposal module
2 a tubelet classification and re-scoring module
3.2. Spatio-temporal tubelet proposal
tubelet proposal module 包含三个步骤:
Step 1: Image object proposal,对每帧图像使用 Selective Search (SS) 进行候选区域提取。然后使用 R-CNN 对候选区域进行一个过滤,将明显非目标区域过滤,大约 6.1%的候选区域留下来。
Step 2: Object proposal scoring,使用经 DET 任务微调的 GoogLeNet 作为检测器,使用第五层池化特征训练SVM分类器,对剩下的候选区域打分。
Step 3: High-confidence proposal tracking 这里使用文献【36】中的跟踪算法来对候选区域进行跟踪,跟踪的初始位置 “anchors”使用上一个步骤中 most confident box proposals,对跟踪还进行了一些处理,使其更加稳定。
3.3. Tubelet classification and rescoring
经过 tubelet proposal module处理,对每个类,我们得到了 tubelets with high-confidence anchor detections,接下来怎么做?一个很直接的方法就是对 tubelet 中的每个矩形框进行分类。这个方法和基于R-CNN静态图像目标检测效果差不多。原因大致有4点:
1) tubelets 中的矩形候选区域数量要比 Selective Search 少很多,这可能会让我们漏掉一些目标。
2) 针对静态图像训练的目标检测器 对于目标位置的变化比较敏感,如图1(a)所示,所以tubelets 中的矩形候选区域的分数比较低。
3) 在跟踪过程中,我们进行了 proposal sup-pression,这也可能是我们丢失一些目标。
4)我们应该嵌入 temporal information是的检测更稳定。
为了解决 tubelet classification 中的这些问题,我们设计以下步骤来增加候选区域,提高检测位置稳定性,嵌入时间信息。augment proposals,increase spatial detection robustness and incorporate temporal consistency into the detection scores
Step 4. Tubelet box perturbation and max-pooling
The tubelet box perturbation and max-pooling process is to re-
place tubelet boxs with boxes of higher confidence.
针对视频中tubelet 矩形框检测分数的不稳定性,我们在tubelet 矩形框 邻域做目标检测,将检测分数最高的矩形框替代tubelet原来的矩形框。从而达到降低tubelet 矩形框检测分数的不稳定性。
Step 5. Temporal convolution and re-scoring
这里我们提出了一个 Temporal Convolutional Network (TCN) 来嵌入时序信息来提高tubelet 矩形框检测分数的稳定性。
有点类似高斯平滑的意思啊,就是根据相邻的检测分数来提高检测的稳定性。

相关文章推荐
- READING NOTE: Object Detection from Video Tubelets with Convolutional Neural Networks
- Object Detection from Video Tubelets with Convolutional Neural Networks
- 视频目标检测--Flow-Guided Feature Aggregation for Video Object Detection
- 使用判别训练的部件模型进行目标检测 Object Detection with Discriminatively Trained Part Based Models
- 目标检测--RON: Reverse Connection with Objectness Prior Networks for Object Detection
- 【论文笔记】视频物体检测(VID)系列 FGFA:Flow-Guided Feature Aggregation for Video Object Detection
- Improving Multiview Face Detection with Multi-Task Deep Convolutional Neural Networks 基于深度学习的人脸检测算法
- 目标检测-- DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling
- 目标检测--A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 使用判别训练的部件模型进行目标检测 Object Detection with Discriminatively Trained Part Based Models
- 目标检测--Improving Object Detection With One Line of Code
- [目标检测] RON-Reverse Connection with Objectness Prior Networks for Object Detection
- 目标检测--R-FCN: Object Detection via Region-based Fully Convolutional Networks
- 【视频变化检测】2017CVPR Spatio-Temporal Self-Organizing Map Deep Network for Dynamic Object Detection from
- 使用判别训练的部件模型进行目标检测 Object Detection with Discriminatively Trained Part Based Models
- 【深度学习:目标检测】 RCNN学习笔记(11):R-FCN: Object Detection via Region-based Fully Convolutional Networks
- 基于视频的移动目标检测 Moving Object Detection
- 目标检测:Improving Object Detection With One Line of Code
- (译)使用判别训练的部件模型进行目标检测 Object Detection with Discriminatively Trained Part Based Models
- 特征金字塔特征用于目标检测:Feature Pyramid Networks for Object Detection