Yarn的应用场景与原理
2017-09-25 15:46
267 查看
Yarn的应用场景与原理
Yarn产生的背景
hadoop1.0不能满足多系统集成的背景孕育了yarn的产生。由于多分布式系统可以很好的集成,因此yarn的出现使得整个集群的运维成本大大降低。同时,yarn可以很好的利用集群资源,避免资源的浪费,除此之外,yarn的出现实现了集群的数据共享问题,不同的分布式计算框架可以实现数据的共享。总结来说为以下两点:直接源于MR在几个方面的缺陷
-扩展性受限
-单点故障
-难以支持MR之外的计算
多计算框架各自为战,数据共享困难
-MR:离线计算框架
-Storm:实时计算框架
-Spark:内存计算框架
Yarn的基本构成
我们通过Yarn的工作流程图来了解Yarn的组织架构,如下图:
(1)Client向ResourceManager发送请求
(2)ResourceManager指定一个NodeManager启动起ApplicationMaster
(3)ApplicationMaster将计算任务反馈给ResourceManager
(4)ApplicationMaster将任务分割分发到不同的NodeManager
(5)NodeManager启动Task执行work
接着需要了解的是Yarn的每个节点的详细功能:
ResourceManager
整个集群中只有一个,负责集群资源的统一管理和调度
详细功能:
-处理客户端请求
-启动/监控ApplicationMaster
-监控NodeManager
-资源分配与调度
NodeManager
整个集群有多个,负责单节点资源管理和使用
详细功能:
-单个节点上的资源管理和任务管理
-处理来自ResourceManager的命令
-处理来自ApplicationMaster的命令
ApplicationMaster
每个应用只有一个,负责应用程序的管理
详细功能:
-数据切分
-为应用程序申请资源,并进一步分配给内部任务
-任务监控与容错
Container
对任务运行环境的抽象
详细信息:
-任务运行资源(节点,内存,CPU)
-任务启动命令
-任务运行环境
下面给出Yarn的运行剖析图:
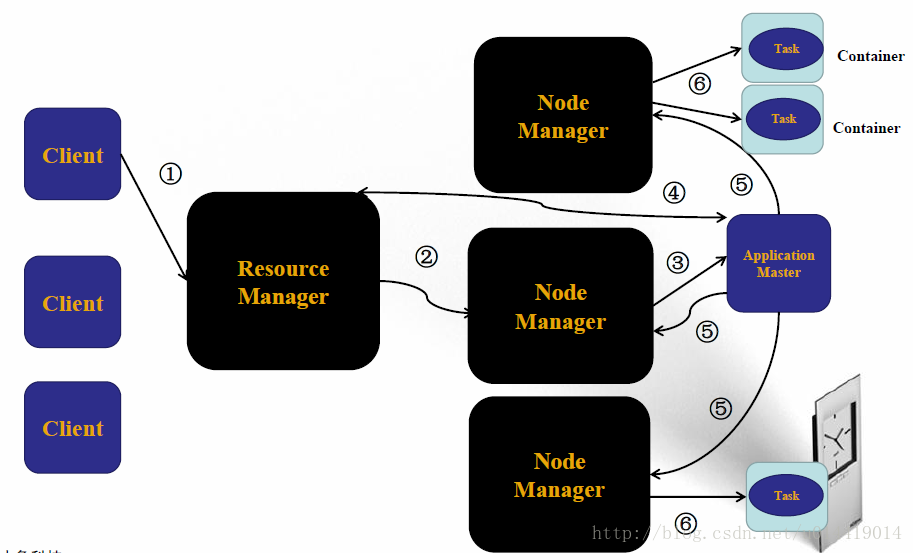
Yarn具有双层调度策略
ResourceManager将资源分配给ApplicationMaster,ApplicationMaster再将资源分配给NodeManager。此外,Yarn具有预留的调度策略,资源不够时,会为Task预留资源直到资源积累充足。
Yarn具有较好的容错机制
当任务失败时,ResourceManager将失败任务告诉ApplicationMaster。由ApplicationMaster处理失败任务,ApplicationMaster会保存已经执行的Task,重启不会重新执行。
Yarn支持内存和CPU两种资源隔离。
内存是一种决定生死的资源,CPU是一种影响快慢的资源,其中,内存隔离包括基于线程监控的方案和基于Cgroups的方案,而CPU隔离包括默认不对CPU资源进行隔离和基于Cgroups的方案。
Yarn支持的调度语义
yarn支持的语义有请求某个特定节点/机架上的特定资源量和将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源,请求归还某些资源。
Yarn不支持的语义有请求任意节点/机架上的特定资源量;请求一组或几组符合某种特质的资源;超细粒度资源;动态调整Container资源。
Yarn的设计目标
Yarn是通用的统一资源管理系统,同时运行长应用程序和短应用程序。长应用程序通常情况下,指永不停止运行的程序service,http server等,短应用程序指短时间(秒级,分钟级,小时级)内会运行结束的程序MR job,Spark Job等。以Yarn为核心的生态系统也越来越多了

比如,离线计算框架MapReduce,DAG计算框架TeZ,流式计算框架Strom,内存计算框架Spark等等,详细介绍后续更新。

相关文章推荐
- YARN应用场景、原理与资源调度
- 【Hadoop系列第四章】YARN应用场景、原理和资源调度
- YARN应用场景、原理与资源调度
- 《Oracle物化视图实战手册》-原理讲解-应用场景-实战
- Elasticsearch的由来、原理及应用场景分析
- HBase应用场景、原理与基本架构
- ETCD:从应用场景到实现原理的全方位解读
- Spring aop 原理及各种应用场景
- Docker五种存储驱动原理及应用场景和性能测试对比
- java 中泛型的原理以及应用场景
- zookeeper原理讲解(讲的很深奥不易懂 原理可以看上一篇 应用场景可以看看)
- Docker五种存储驱动原理及应用场景和性能测试对比
- MapReduce 2.0应用场景和原理、基本架构和编程模型
- Scala中Stream的应用场景及其实现原理
- 回声消除的原理和应用场景
- Spark Streaming 的原理以及应用场景介绍
- impala的原理架构介绍及应用场景
- 简单理解ThreadLocal原理和适用场景,多数据源下ThreadLocal的应用
- Scala中Stream的应用场景及其实现原理
- etcd:从应用场景到实现原理的全方位解读