Hadoop 2.x 入门学习(一)--Centos 6.8 系统Hadoop 2.7.4 伪分布式安装配置详解
2017-09-23 00:00
1076 查看
摘要: 本文作为Hadoop2.X的入门级文章,主要详细介绍了自己搭建Hadoop2.7.4伪分布式测试环境的完整过程,作为Hadoop的业余爱好者, 本文主要通过对hadoop2.7.4伪分布式配置的过程加以梳理,所有的步骤都是通过自己实际测试,在此整理了一些自己业余学习的心得与问题,希望与大家一同交流。
一、测试环境准备
由于个人硬件环境的限制,在测试过程中我是以VMware开虚拟机来替代真实的机器,宿主机和虚拟机配置如下:
宿主机:
CPU: Intel i5-3470 CPU 3.20GHz 内存: 8.00 GB 操作系统: Windows 7 旗舰版 (64位)
虚拟机:
操作系统: Centos 6.8 x86_64 内存: 2.00 GB CPU核数: 1 网络模式: host-only
在准备好Linux环境之后,下面进行一些前期的准备工作,主要包括虚拟机网络模式设置、修改Linux主机名、修改IP、修改主机名和IP的映射关系以及关闭防火墙,下面一一介绍具体操作步骤:
1. 修改虚拟机网络模式
在测试过程中为方便操作Linux虚拟机,这里我们把虚拟机与宿主机的网络连接方式改为host-only模式(这里虚拟机不需要连接外网),当然选择NAT、桥接模式也是可以的。具体的设置方式为:
(1). 点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.33.0 子网掩码:255.255.255.0 -> apply -> ok
(2). 回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.33.10 子网掩码:255.255.255.0 -> 点击确定
(3). 在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
当然修改虚拟机网络的方式有好多种,只要配置连接方式为host-only,设置好相应的IP就行了,这里我采用的是192.168.33.0网段,连接Windows一端的IP我设置成了192.168.33.10,Linux自身的IP设置为192.168.33.100,如有疑问也可以参考其他文章进行操作。
2. 修改Linux主机名
为了操作方便,这里我们修改一下Linux主机名。设置方式为:
[hadoop@server ~]$ sudo vim /etc/sysconfig/network
3. 修改Linux自身IP
修改Linux环境IP,有两种方式,喜欢使用图形界面操作的可以选择方式一,对于那些高大上的熟悉命令行操作的朋友可以选择方式二(个人认为,玩Linux还是推荐命令行模式比较好)。
方式一:通过Linux图形界面进行修改
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.33.100 子网掩码:255.255.255.0 网关:192.168.33.1 -> apply
方式二:修改配置文件方式(###代表修改的部分,其他的可以不变)
[hadoop@server ~]$ sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改完成后,重启网络,sudo service network restart,看到一切OK说明网络设置成功,如果出现Feild删除网络连接再进行上述配置(这时候图形模式就体现优势了),最后通过ping进行验证是否设置成功。
4. 修改主机名和IP的映射关系
[hadoop@server ~]$ sudo vim /etc/hosts
192.168.33.100 server.chargehadoop.com
5. 关闭防火墙
#查看防火墙状态
[hadoop@server ~]$ sudo service iptables status
#关闭防火墙
[hadoop@server ~]$ sudo service iptables stop
#查看防火墙开机启动状态
[hadoop@server ~]$ sudo chkconfig iptables --list
#关闭防火墙开机启动
[hadoop@server ~]$ sudo chkconfig iptables off
6. 配置ssh免登陆
生成ssh免登陆密钥
cd ~,进入到我的home目录
[hadoop@server ~]$ cd .ssh/
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
[hadoop@server ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或
[hadoop@server ~]$ ssh-copy-id -i localhost
7. 重启Linux
[hadoop@server ~]$ sudo reboot
到此,安装Hadoop的准备工作已经完毕,下面分析Hadoop伪分布式配置的详细过程。
二、安装jdk
1. 上传jdk安装包
到oracle官网http://www.oracle.com/technetwork/java/javase/downloads/index.html下载一个相对应的jdk安装包,这里使用的是jdk1.8.0_121 x64 linux版本,上传到Linux虚拟机中。
2. 解压jdk
#创建文件夹
[hadoop@server ~]$ sudo mkdir /usr/java
#解压
[hadoop@server ~]$ sudo tar -zxvf jdk-8u121-linux-x64.tar.gz -C /usr/java/
3. 将java添加到环境变量中
[hadoop@server ~]$ vim /etc/profile
#在文件最后添加
#刷新配置
[hadoop@server ~]$ source /etc/profile
三、安装Hadoop
1. 上传hadoop安装包
到Hadoop官网http://mirrors.cnnic.cn/apache/hadoop/common/下载Hadoop2.7.4安装包,上传Hadoop2.7.4.tar.gz文件到虚拟机中。
2. 解压hadoop安装包
[hadoop@server ~]$ sudo mkdir -p /opt/modules/hadoop
更改目录的属主为hadoop用户
[hadoop@server ~]$ chown -R hadoop:hadoop /opt/modules/hadoop
#解压到/opt/modules/hadoop目录下
[hadoop@server ~]$ tar -zxvf hadoop-2.7.4.tar.gz -C /opt/modules/hadoop
3. 修改配置文件(这里需要修改5个)
第一个:配置hadoop-env.sh、mapred-env.sh、yarn-env.sh的JAVA_HOME设置
找到对应的JAVA_HOME设置项,更改为:
第二个:core-site.xml
第三个:hdfs-site.xml
第四个:mapred-site.xml.template 需要重命名: mv mapred-site.xml.template mapred-site.xml
第五个:yarn-site.xml
4. 将hadoop添加到环境变量
[hadoop@server hadoop-2.7.4]$ vim /etc/profile
[hadoop@server hadoop-2.7.4]$ source /etc/profile
5. 格式化HDFS(namenode)第一次使用时要格式化
[hadoop@server hadoop-2.7.4]$ bin/hdfs namenode -format
6. 启动hadoop
先启动HDFS
1) 先启动namenode:
[hadoop@server hadoop-2.7.4]$ sbin/hadoop-daemon.sh start namenode
2) 接着启动datanode:
[hadoop@server hadoop-2.7.4]$ sbin/hadoop-daemon.sh start datanode
再启动YARN
1) 先启动ResourceManager:
[hadoop@server hadoop-2.7.4]$ sbin/yarn-daemon.sh start resourcemanager
2) 接着启动NodeManager:
[hadoop@server hadoop-2.7.4]$ sbin/yarn-daemon.sh start nodemanager
7. 验证是否启动成功
[hadoop@server ~]$ jps
2369 NameNode
3010 ResourceManager
4854 Jps
2456 DataNode
3259 NodeManager
如果安装成功,通过jps命令可以看到以上四个java进程。同时可以通过hadoop自带的管理界面验证服务是否成功。
http://192.168.33.100:50070 (HDFS管理界面)
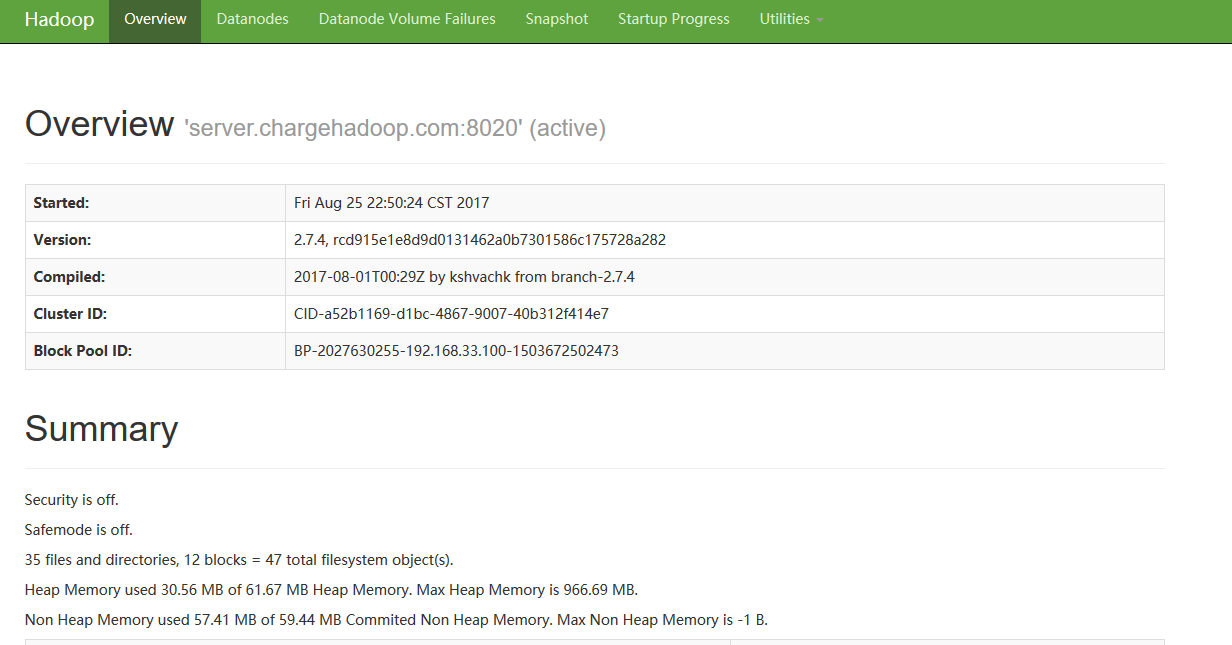
http://192.168.33.100:8088 (MR管理界面)

到此,hadoop2.7.4伪分布式搭建已经完成,大家可以用一下操作进行验证。
1. 验证HDFS
向hdfs上传一个文件,然后查看hdfs中是否存在
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -mkdir -p /user/hadoop/conf
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -put etc/hadoop/core-site.xml /user/hadoop/conf
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -ls /user/hadoop/conf
2. 验证YARN
运行一下hadoop提供的demo中的WordCount程序,统计每个单词出现的次数
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount input output
注意,这里需要事先创建hdfs上的input目录,并将准备好的文件上传到此目录下,并且output目录必须不存在,否则运行失败。
[hadoop@server hadoop-2.7.4]$ cd /opt/data/hadoop/data/
[hadoop@server data]$ vim wc.input
[hadoop@server hadoop-2.7.4]$ cd /opt/modules/hadoop/hadoop-2.7.4
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -mkdir -p /user/hadoop/wordcount/input
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -put /opt/data/hadoop/data/wc.input /user/hadoop/wordcount/output
[hadoop@server hadoop-2.7.4]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /user/hadoop/wordcount/input /user/hadoop/wordcount/output
等待运行完成可以查看运行结果:
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -ls /user/hadoop/wordcount/output

运行结果保存在part-r-00000中,可以通过以下命令查看具体结果
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -text /user/hadoop/wordcount/output/pa*

OK,至此,hadoophadoop2.7.4伪分布式搭建已经完成,大功告成!!!
一、测试环境准备
由于个人硬件环境的限制,在测试过程中我是以VMware开虚拟机来替代真实的机器,宿主机和虚拟机配置如下:
宿主机:
CPU: Intel i5-3470 CPU 3.20GHz 内存: 8.00 GB 操作系统: Windows 7 旗舰版 (64位)
虚拟机:
操作系统: Centos 6.8 x86_64 内存: 2.00 GB CPU核数: 1 网络模式: host-only
在准备好Linux环境之后,下面进行一些前期的准备工作,主要包括虚拟机网络模式设置、修改Linux主机名、修改IP、修改主机名和IP的映射关系以及关闭防火墙,下面一一介绍具体操作步骤:
1. 修改虚拟机网络模式
在测试过程中为方便操作Linux虚拟机,这里我们把虚拟机与宿主机的网络连接方式改为host-only模式(这里虚拟机不需要连接外网),当然选择NAT、桥接模式也是可以的。具体的设置方式为:
(1). 点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.33.0 子网掩码:255.255.255.0 -> apply -> ok
(2). 回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.33.10 子网掩码:255.255.255.0 -> 点击确定
(3). 在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
当然修改虚拟机网络的方式有好多种,只要配置连接方式为host-only,设置好相应的IP就行了,这里我采用的是192.168.33.0网段,连接Windows一端的IP我设置成了192.168.33.10,Linux自身的IP设置为192.168.33.100,如有疑问也可以参考其他文章进行操作。
2. 修改Linux主机名
为了操作方便,这里我们修改一下Linux主机名。设置方式为:
[hadoop@server ~]$ sudo vim /etc/sysconfig/network
NETWORKING=yes HOSTNAME=server.chargehadoop.com
3. 修改Linux自身IP
修改Linux环境IP,有两种方式,喜欢使用图形界面操作的可以选择方式一,对于那些高大上的熟悉命令行操作的朋友可以选择方式二(个人认为,玩Linux还是推荐命令行模式比较好)。
方式一:通过Linux图形界面进行修改
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.33.100 子网掩码:255.255.255.0 网关:192.168.33.1 -> apply
方式二:修改配置文件方式(###代表修改的部分,其他的可以不变)
[hadoop@server ~]$ sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0" BOOTPROTO="static" ### IPV6INIT="yes" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" IPADDR="192.168.33.100" ### NETMASK="255.255.255.0" ### GATEWAY="192.168.33.1" ###
修改完成后,重启网络,sudo service network restart,看到一切OK说明网络设置成功,如果出现Feild删除网络连接再进行上述配置(这时候图形模式就体现优势了),最后通过ping进行验证是否设置成功。
4. 修改主机名和IP的映射关系
[hadoop@server ~]$ sudo vim /etc/hosts
192.168.33.100 server.chargehadoop.com
5. 关闭防火墙
#查看防火墙状态
[hadoop@server ~]$ sudo service iptables status
#关闭防火墙
[hadoop@server ~]$ sudo service iptables stop
#查看防火墙开机启动状态
[hadoop@server ~]$ sudo chkconfig iptables --list
#关闭防火墙开机启动
[hadoop@server ~]$ sudo chkconfig iptables off
6. 配置ssh免登陆
生成ssh免登陆密钥
cd ~,进入到我的home目录
[hadoop@server ~]$ cd .ssh/
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
[hadoop@server ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或
[hadoop@server ~]$ ssh-copy-id -i localhost
7. 重启Linux
[hadoop@server ~]$ sudo reboot
到此,安装Hadoop的准备工作已经完毕,下面分析Hadoop伪分布式配置的详细过程。
二、安装jdk
1. 上传jdk安装包
到oracle官网http://www.oracle.com/technetwork/java/javase/downloads/index.html下载一个相对应的jdk安装包,这里使用的是jdk1.8.0_121 x64 linux版本,上传到Linux虚拟机中。
2. 解压jdk
#创建文件夹
[hadoop@server ~]$ sudo mkdir /usr/java
#解压
[hadoop@server ~]$ sudo tar -zxvf jdk-8u121-linux-x64.tar.gz -C /usr/java/
3. 将java添加到环境变量中
[hadoop@server ~]$ vim /etc/profile
#在文件最后添加
export JAVA_HOME=/usr/java/jdk1.8.0_121 export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
[hadoop@server ~]$ source /etc/profile
三、安装Hadoop
1. 上传hadoop安装包
到Hadoop官网http://mirrors.cnnic.cn/apache/hadoop/common/下载Hadoop2.7.4安装包,上传Hadoop2.7.4.tar.gz文件到虚拟机中。
2. 解压hadoop安装包
[hadoop@server ~]$ sudo mkdir -p /opt/modules/hadoop
更改目录的属主为hadoop用户
[hadoop@server ~]$ chown -R hadoop:hadoop /opt/modules/hadoop
#解压到/opt/modules/hadoop目录下
[hadoop@server ~]$ tar -zxvf hadoop-2.7.4.tar.gz -C /opt/modules/hadoop
3. 修改配置文件(这里需要修改5个)
第一个:配置hadoop-env.sh、mapred-env.sh、yarn-env.sh的JAVA_HOME设置
找到对应的JAVA_HOME设置项,更改为:
export JAVA_HOME=/usr/java/jdk1.8.0_121
第二个:core-site.xml
<configuration> <!-- 指定HDFS(namenode)的通信地址 --> <property> <name>fs.defaultFS</name> <!--hadoop2.x以后版本namenode的rpc端口一般都用8020,1.x默认使用9000--> <value>hdfs://server.chargehadoop.com:8020</value> </property> <!-- 指定hadoop运行时产生文件的存储路径 --> <property> <name>hadoop.tmp.dir</name> <!--需要提前创建好此目录--> <value>/opt/data/hadoop/tmp</value> </property> </configuration>
第三个:hdfs-site.xml
<configuration> <!-- 设置hdfs副本数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
第四个:mapred-site.xml.template 需要重命名: mv mapred-site.xml.template mapred-site.xml
<configuration> <!-- 通知框架MR使用YARN --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
第五个:yarn-site.xml
<configuration> <!-- reducer取数据的方式是mapreduce_shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
4. 将hadoop添加到环境变量
[hadoop@server hadoop-2.7.4]$ vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_121 export HADOOP_HOME=/opt/modules/hadoop/hadoop-2.7.4 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
[hadoop@server hadoop-2.7.4]$ source /etc/profile
5. 格式化HDFS(namenode)第一次使用时要格式化
[hadoop@server hadoop-2.7.4]$ bin/hdfs namenode -format
6. 启动hadoop
先启动HDFS
1) 先启动namenode:
[hadoop@server hadoop-2.7.4]$ sbin/hadoop-daemon.sh start namenode
2) 接着启动datanode:
[hadoop@server hadoop-2.7.4]$ sbin/hadoop-daemon.sh start datanode
再启动YARN
1) 先启动ResourceManager:
[hadoop@server hadoop-2.7.4]$ sbin/yarn-daemon.sh start resourcemanager
2) 接着启动NodeManager:
[hadoop@server hadoop-2.7.4]$ sbin/yarn-daemon.sh start nodemanager
7. 验证是否启动成功
[hadoop@server ~]$ jps
2369 NameNode
3010 ResourceManager
4854 Jps
2456 DataNode
3259 NodeManager
如果安装成功,通过jps命令可以看到以上四个java进程。同时可以通过hadoop自带的管理界面验证服务是否成功。
http://192.168.33.100:50070 (HDFS管理界面)
http://192.168.33.100:8088 (MR管理界面)
到此,hadoop2.7.4伪分布式搭建已经完成,大家可以用一下操作进行验证。
1. 验证HDFS
向hdfs上传一个文件,然后查看hdfs中是否存在
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -mkdir -p /user/hadoop/conf
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -put etc/hadoop/core-site.xml /user/hadoop/conf
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -ls /user/hadoop/conf
2. 验证YARN
运行一下hadoop提供的demo中的WordCount程序,统计每个单词出现的次数
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount input output
注意,这里需要事先创建hdfs上的input目录,并将准备好的文件上传到此目录下,并且output目录必须不存在,否则运行失败。
[hadoop@server hadoop-2.7.4]$ cd /opt/data/hadoop/data/
[hadoop@server data]$ vim wc.input
hadoop spark hadoop hive mapreduce hive hadoop yarn hello world hello hadoop
[hadoop@server hadoop-2.7.4]$ cd /opt/modules/hadoop/hadoop-2.7.4
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -mkdir -p /user/hadoop/wordcount/input
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -put /opt/data/hadoop/data/wc.input /user/hadoop/wordcount/output
[hadoop@server hadoop-2.7.4]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /user/hadoop/wordcount/input /user/hadoop/wordcount/output
等待运行完成可以查看运行结果:
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -ls /user/hadoop/wordcount/output
运行结果保存在part-r-00000中,可以通过以下命令查看具体结果
[hadoop@server hadoop-2.7.4]$ bin/hdfs dfs -text /user/hadoop/wordcount/output/pa*
OK,至此,hadoophadoop2.7.4伪分布式搭建已经完成,大功告成!!!

相关文章推荐
- Hadoop学习6_CentOS6.5系统下Hadoop2.6.0完全分布式环境安装与配置信息介绍
- centos6.8系统安装 Hadoop 2.7.3伪分布式集群
- 【Hadoop入门】Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
- centos6.8系统安装 Hadoop 2.7.3伪分布式集群
- Hadoop1.2.1稳定版安装__全分布式模式__Hadoop1.0入门学习一
- Hadoop学习笔记_Ubuntu下伪分布式安装及配置
- Hadoop2.5.1伪分布式安装记录,Centos6.4系统,wordcount运行测试
- CentOS系统下docker的安装配置及使用详解
- CentOS学习10_CentOS系统安装过程和配置细节
- Ubuntu系统下的Hadoop集群(1)_Hadoop安装教程_单机/伪分布式配置
- centos 6.3下安装Hadoop 2.7.1并配置伪分布式集群
- CentOS系统下Hadoop 2.4.1集群安装配置(简易版)
- Hadoop完全分布式系统安装与配置
- centos 6.3下安装Hadoop 2.7.1并配置伪分布式集群
- CentOS系统下的Hadoop集群(第5期)_Hadoop安装配置
- CentOS系统下Hadoop 2.4.1集群安装配置(简易版)
- hadoop学习(五)Hadoop2.2.0完全分布式安装详解(1)
- CentOS系统下Hadoop、Hbase、Zookeeper安装配置
- CentOS系统下docker的安装配置及使用详解
- WMware 中CentOS系统Hadoop 分布式环境搭建(一)——Hadoop安装环境准备