基于 bi-LSTM和CRF的中文命名实体识别
2017-09-20 14:12
176 查看
follow: https://github.com/zjy-ucas/ChineseNER
这里边主要识别的实体如图所示,其实也就主要识别人名PER,机构ORG和地点LOC: B表示开始的字节,I表示中间的字节,E表示最后的字节,S表示该实体是单字节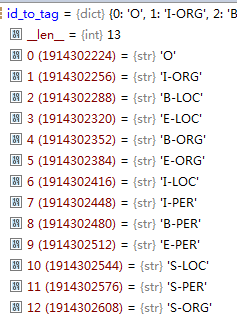 例子:
例子:
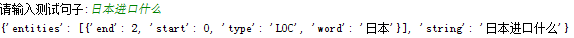

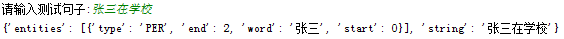 实现架构:1. 读取数据集,数据集共三个文件,训练集,交叉测试集和测试集,文件中每一行包含两个元素,字和标识。每一句话间由一个空格隔开
实现架构:1. 读取数据集,数据集共三个文件,训练集,交叉测试集和测试集,文件中每一行包含两个元素,字和标识。每一句话间由一个空格隔开

 2. 处理数据集 1) 更新数据集中的标签,如: 单独的B-LOC→S-LOC,B-LOC,I-LOC→B-LOC,E-LOC,B-LOC,I-LOC,I-LOC→B-LOC, I-LOC, E-LOC 2) 给每个char和tag分配一个id,得到一个包含所有字的字典dict,以及char_to_id, id_to_char, tag_to_id, id_to_tag, 将其存在map.pkl中3. 准备训练集 将训练集中的每句话变成4个list,第一个list是字,如[今,天,去,北,京],第二个list是char_to_id [3,5,6,8,9],第三个list是通过jieba分词得到的分词信息特征,如[1,3,0,1,3] (1,词的开始,2,词的中间,3,词的结尾,0,单个词),第四个list是target,如[0,0,0,2,3](非0的元素对应着tag_to_id中的数值)4. BatchManager 将训练集划分成若干个batch,每个batch有20个句子,划分时,是现按句子长度从大到小排列5. 配置model的参数6. 构建模型 1)input: 输入两个特征,char_to_id的list以及通过jieba得到的分词特征list 2)embedding: 预先训练好了100维词向量模型,通过查询将得到每个字的100维向量,加上分词特征向量,输出到drouput(0.5) 3)bi-lstm 4)project_layer:两层的Wx+b 逻辑回归 5)loss_layer:内嵌了CRF
2. 处理数据集 1) 更新数据集中的标签,如: 单独的B-LOC→S-LOC,B-LOC,I-LOC→B-LOC,E-LOC,B-LOC,I-LOC,I-LOC→B-LOC, I-LOC, E-LOC 2) 给每个char和tag分配一个id,得到一个包含所有字的字典dict,以及char_to_id, id_to_char, tag_to_id, id_to_tag, 将其存在map.pkl中3. 准备训练集 将训练集中的每句话变成4个list,第一个list是字,如[今,天,去,北,京],第二个list是char_to_id [3,5,6,8,9],第三个list是通过jieba分词得到的分词信息特征,如[1,3,0,1,3] (1,词的开始,2,词的中间,3,词的结尾,0,单个词),第四个list是target,如[0,0,0,2,3](非0的元素对应着tag_to_id中的数值)4. BatchManager 将训练集划分成若干个batch,每个batch有20个句子,划分时,是现按句子长度从大到小排列5. 配置model的参数6. 构建模型 1)input: 输入两个特征,char_to_id的list以及通过jieba得到的分词特征list 2)embedding: 预先训练好了100维词向量模型,通过查询将得到每个字的100维向量,加上分词特征向量,输出到drouput(0.5) 3)bi-lstm 4)project_layer:两层的Wx+b 逻辑回归 5)loss_layer:内嵌了CRF
null
这里边主要识别的实体如图所示,其实也就主要识别人名PER,机构ORG和地点LOC: B表示开始的字节,I表示中间的字节,E表示最后的字节,S表示该实体是单字节
例子:
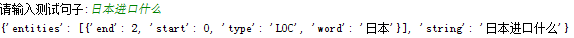

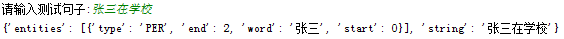 实现架构:1. 读取数据集,数据集共三个文件,训练集,交叉测试集和测试集,文件中每一行包含两个元素,字和标识。每一句话间由一个空格隔开
2. 处理数据集 1) 更新数据集中的标签,如: 单独的B-LOC→S-LOC,B-LOC,I-LOC→B-LOC,E-LOC,B-LOC,I-LOC,I-LOC→B-LOC, I-LOC, E-LOC 2) 给每个char和tag分配一个id,得到一个包含所有字的字典dict,以及char_to_id, id_to_char, tag_to_id, id_to_tag, 将其存在map.pkl中3. 准备训练集 将训练集中的每句话变成4个list,第一个list是字,如[今,天,去,北,京],第二个list是char_to_id [3,5,6,8,9],第三个list是通过jieba分词得到的分词信息特征,如[1,3,0,1,3] (1,词的开始,2,词的中间,3,词的结尾,0,单个词),第四个list是target,如[0,0,0,2,3](非0的元素对应着tag_to_id中的数值)4. BatchManager 将训练集划分成若干个batch,每个batch有20个句子,划分时,是现按句子长度从大到小排列5. 配置model的参数6. 构建模型 1)input: 输入两个特征,char_to_id的list以及通过jieba得到的分词特征list 2)embedding: 预先训练好了100维词向量模型,通过查询将得到每个字的100维向量,加上分词特征向量,输出到drouput(0.5) 3)bi-lstm 4)project_layer:两层的Wx+b 逻辑回归 5)loss_layer:内嵌了CRF
实现架构:1. 读取数据集,数据集共三个文件,训练集,交叉测试集和测试集,文件中每一行包含两个元素,字和标识。每一句话间由一个空格隔开
2. 处理数据集 1) 更新数据集中的标签,如: 单独的B-LOC→S-LOC,B-LOC,I-LOC→B-LOC,E-LOC,B-LOC,I-LOC,I-LOC→B-LOC, I-LOC, E-LOC 2) 给每个char和tag分配一个id,得到一个包含所有字的字典dict,以及char_to_id, id_to_char, tag_to_id, id_to_tag, 将其存在map.pkl中3. 准备训练集 将训练集中的每句话变成4个list,第一个list是字,如[今,天,去,北,京],第二个list是char_to_id [3,5,6,8,9],第三个list是通过jieba分词得到的分词信息特征,如[1,3,0,1,3] (1,词的开始,2,词的中间,3,词的结尾,0,单个词),第四个list是target,如[0,0,0,2,3](非0的元素对应着tag_to_id中的数值)4. BatchManager 将训练集划分成若干个batch,每个batch有20个句子,划分时,是现按句子长度从大到小排列5. 配置model的参数6. 构建模型 1)input: 输入两个特征,char_to_id的list以及通过jieba得到的分词特征list 2)embedding: 预先训练好了100维词向量模型,通过查询将得到每个字的100维向量,加上分词特征向量,输出到drouput(0.5) 3)bi-lstm 4)project_layer:两层的Wx+b 逻辑回归 5)loss_layer:内嵌了CRFnull

相关文章推荐
- 基于深度学习的命名实体识别bi-lstm+crf
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
- Bi-LSTM + CRF 命名实体识别
- 基于CRF的中文分词
- 词法分析之Bi-LSTM-CRF框架
- crf++中文命名实体识别
- 【Natural Language Processing】基于CRF++的中文分词
- End to End Sequence Labeling via Bi-directional LSTM CNNs CRF
- 阿里巴巴、狗尾草、苏大联合论文:基于对抗学习的众包标注用于中文命名实体识别
- 基于CRF序列标注的中文依存句法分析器的Java实现
- keras实现Bi-LSTM+CRF
- 记使用CRF++做中文命名实体识别
- Pytorch Bi-LSTM + CRF 代码详解
- 基于CRF++0.54搭建中文分词系统
- lstm+crf实现命名实体识别
- 【tf系列4】Bi-LSTM中文分词
- 基于LSTM的中文语法错误诊断
- BiLSTM-CRF 模型实现中文命名实体识别
- 基于CRF的中文分词(ZT)
- 基于Simase_LSTM的计算中文句子相似度经验总结与分享