机器学习-->集成学习-->Bagging,Boosting,Stacking
2017-09-20 11:03
357 查看
目录(?)[-]
Boosting
Bagging
stacking
在一些数据挖掘竞赛中,后期我们需要对多个模型进行融合以提高效果时,常常会用到Bagging,Boosting,Stacking等这几个框架算法。下面就来分别详细讲述这三个框架算法。这里我们只做原理上的讲解,不做数学上推导。
集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前接触较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost、GBDT、XGBOOST、后者的代表算法主要是随机森林。
Boosting有很多种,比如AdaBoost(Adaptive Boosting), Gradient Boosting等,这里以AdaBoost,Gradient Boosting为典型讲下。
Boosting也是集合了多个决策树,但是Boosting的每棵树是顺序生成的,每一棵树都依赖于前一颗树。顺序运行会导致运行速度慢。
首先介绍下AdaBoost的思想,而不去阐述Boosting决策树的构建构建方法和数学公式推导。
AdaBoost,运用了迭代的思想。每一轮都加入一个新训练一个预测函数,直到达到一个设定的足够小的误差率,或者达到最大的树的数目。
①开始的时候每一个训练样本都被赋予一个初始权重,用*所有样本*训练第一个预测函数。计算该预测函数的误差,然后利用该误差计算训练的预测函数的权重系数(该预测函数在最终的预测函数中的权重,此处忽略公式)。接着利用误差更新样本权重(此处忽略公式)。如果样本被错误预测,权重会增加;如果样本被正确预测,权重会减少。通过权重的变化,使下轮的训练器对错误样本的判断效果更好。
②以后每轮训练一个预测函数。根据最后得出的预测函数的误差计算新训练的预测函数在最终预测中的权重,然后更新样本的权重。权重更新之后,所有样本用于下轮的训练。
③如此迭代,直到误差小于某个值或者达到最大树数。
这里涉及到两个权重,每轮新训练的预测函数在最终预测函数中所占的权重和样本下一轮训练中的权重。这两个权重都是关于 每轮训练的预测函数产生的误差 的函数。
Adaboost的算法流程:
假设训练数据集为T={(X1,Y1),(X2,Y2),(X3,Y3),(X4,Y4),(X5,Y5)} 其中Yi={-1,1}
1、初始化训练数据的分布
训练数据的权重分布为D={W11,W12,W13,W14,W15},其中W1i=1/N。即平均分配。
2、选择基本分类器
这里选择最简单的线性分类器y=aX+b ,分类器选定之后,最小化分类误差可以求得参数。
3、计算分类器的系数和更新数据权重
误差率也可以求出来为e1.同时可以求出这个分类器的系数。基本的Adaboost给出的系数计算公式为
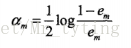
上面求出的am就是这个分类器在最终的分类器中的权重。然后更新训练数据的权重分布。如果样本被错误预测,权重会增加;如果样本被正确预测,权重会减少。
总而言之:Boosting每次迭代循环都是利用所有的训练样本,每次迭代都会训练出一个分类器,根据这个分类器的误差率计算出该分类器的在最终的分类器中的权重,并且更新训练样本的权重。这就使得每次迭代训练出的分类器都依赖上一次的分类器,串行速度慢。
Boosting最终的组合弱分类器方式:
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
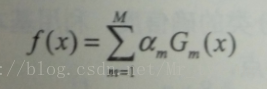
GBDT算法流程:

简单理解上面流程,其中N为样本个数,M为树的数目。其中(a),(b),(c)步骤表示根据梯度计算出下一棵树以及下一棵树在组合中的权重。
注意:
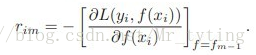
,是损失函数对f(x)求偏导,并不是对x求偏导。
Gradient Boost与传统的Boost的区别是,Gradient Boost会定义一个loassFunction,每一次的计算是为了减少上一次的loss,而为了消除loss,我们可以在loss减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的loss往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
1)从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping(有放回)的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(我们这里假设k个训练集之间是相互独立的,事实上不是完全独立)
2)每次使用一个训练集得到一个模型,k个训练集共得到k个模型。但是是同种模型。(注:,k个训练集虽然有重合不完全独立,训练出来的模型因为是同种模型也是不完全独立。这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
3)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
对于Bagging需要注意的是,每次训练集可以取全部的特征进行训练,也可以随机选取部分特征训练,例如随机森林就是每次随机选取部分特征
讲完Boosting,Bagging,我们来总结下这两种框架算法的异同点:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:理论上各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。计算角度来看,两种方法都可以并行。bagging, random forest并行化方法显而意见。boosting有强力工具stochastic gradient boosting
5)bagging是减少variance,而boosting是减少bias
在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模型的性能(performance)。然而我们学习一个模型的目的是为了解决实际的问题(或者说是训练数据集这个领域(field)中的一般化问题),单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization
error。而generalization error又可以细分为Bias和Variance两个部分。
即error=Bias+Variance
可以通过降低Bias或者降低Variance来减小error
Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均。由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。由于

,所以bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,则有
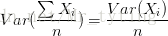
,此时可以显著降低variance。若各子模型完全相同,则
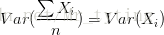
,此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。为了进一步降低variance,Random
forest通过随机选取变量子集做拟合的方式de-correlated了各子模型(树),使得variance进一步降低。boosting从优化角度来看,是用forward-stagewise这种贪心法去最小化损失函数
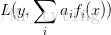
。例如,常见的AdaBoost即等价于用这种方法最小化exponential
loss:
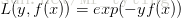
。所谓forward-stagewise,就是在迭代的第n步,求解新的子模型f(x)及步长a(或者叫组合系数),来最小化

,这里
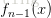
是前n-1步得到的子模型的和。因此boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度。
6)Bagging里面每个分类器是强分类器,因为他降低的是方差,方差过高需要降低是过拟合。boosting里面每个分类器是弱分类器,因为他降低的是偏差,偏差过高是欠拟合。
先讲讲stacking具体的算法流程
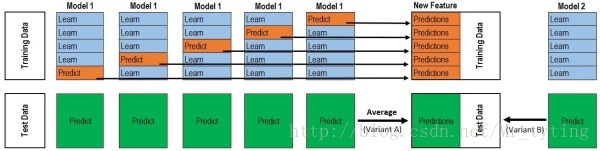
以上图为例,我们现在有训练集train_x,train_y,测试集test
① 我们首先选择一种模型比如随机森林rf。(未经训练)
②这里假设把训练集均分成5份,把其中四份作为小的训练集s_train_x,s_train_y另外一份作为小的测试集s_test,测试集test不变。
③我们以s_train_x,s_train_y训练rf模型,训练出的模型预测s_test得出对应的s_pred,再预测test得出y_pred。
④在训练集再选择另外一份作为小的测试集s_test_x,其他四份作为训练集训练模型rf。
⑤重复②,③,④步骤五次。我们会得到五个s_pred和五个y_pred。
五个s_pred作为一个train_X,原始的train_y作为train_Y训练模型得到模型G,五个y_pred取个平均值作为新的test_X,把test_X带入到模型G中得出预测结果。
以上就是stacking的第一层,在第二层中,我们以第一层的输出train再结合其他的特征集再做一层stacking。不同的层数之间有各种交互,还有将经过不同的 Preprocessing 和不同的 Feature Engineering 的数据用 Ensemble 组合起来的做法。
上面是以一种模型随机森林进行模型训练,当然可以分别用不同种的模型。
以下代码是典型的stacking第一层
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Boosting
Bagging
stacking
在一些数据挖掘竞赛中,后期我们需要对多个模型进行融合以提高效果时,常常会用到Bagging,Boosting,Stacking等这几个框架算法。下面就来分别详细讲述这三个框架算法。这里我们只做原理上的讲解,不做数学上推导。
集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前接触较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost、GBDT、XGBOOST、后者的代表算法主要是随机森林。
Boosting
Boosting有很多种,比如AdaBoost(Adaptive Boosting), Gradient Boosting等,这里以AdaBoost,Gradient Boosting为典型讲下。Boosting也是集合了多个决策树,但是Boosting的每棵树是顺序生成的,每一棵树都依赖于前一颗树。顺序运行会导致运行速度慢。
首先介绍下AdaBoost的思想,而不去阐述Boosting决策树的构建构建方法和数学公式推导。
AdaBoost,运用了迭代的思想。每一轮都加入一个新训练一个预测函数,直到达到一个设定的足够小的误差率,或者达到最大的树的数目。
①开始的时候每一个训练样本都被赋予一个初始权重,用*所有样本*训练第一个预测函数。计算该预测函数的误差,然后利用该误差计算训练的预测函数的权重系数(该预测函数在最终的预测函数中的权重,此处忽略公式)。接着利用误差更新样本权重(此处忽略公式)。如果样本被错误预测,权重会增加;如果样本被正确预测,权重会减少。通过权重的变化,使下轮的训练器对错误样本的判断效果更好。
②以后每轮训练一个预测函数。根据最后得出的预测函数的误差计算新训练的预测函数在最终预测中的权重,然后更新样本的权重。权重更新之后,所有样本用于下轮的训练。
③如此迭代,直到误差小于某个值或者达到最大树数。
这里涉及到两个权重,每轮新训练的预测函数在最终预测函数中所占的权重和样本下一轮训练中的权重。这两个权重都是关于 每轮训练的预测函数产生的误差 的函数。
Adaboost的算法流程:
假设训练数据集为T={(X1,Y1),(X2,Y2),(X3,Y3),(X4,Y4),(X5,Y5)} 其中Yi={-1,1}
1、初始化训练数据的分布
训练数据的权重分布为D={W11,W12,W13,W14,W15},其中W1i=1/N。即平均分配。
2、选择基本分类器
这里选择最简单的线性分类器y=aX+b ,分类器选定之后,最小化分类误差可以求得参数。
3、计算分类器的系数和更新数据权重
误差率也可以求出来为e1.同时可以求出这个分类器的系数。基本的Adaboost给出的系数计算公式为
上面求出的am就是这个分类器在最终的分类器中的权重。然后更新训练数据的权重分布。如果样本被错误预测,权重会增加;如果样本被正确预测,权重会减少。
总而言之:Boosting每次迭代循环都是利用所有的训练样本,每次迭代都会训练出一个分类器,根据这个分类器的误差率计算出该分类器的在最终的分类器中的权重,并且更新训练样本的权重。这就使得每次迭代训练出的分类器都依赖上一次的分类器,串行速度慢。
Boosting最终的组合弱分类器方式:
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
GBDT算法流程:
简单理解上面流程,其中N为样本个数,M为树的数目。其中(a),(b),(c)步骤表示根据梯度计算出下一棵树以及下一棵树在组合中的权重。
注意:
,是损失函数对f(x)求偏导,并不是对x求偏导。
Gradient Boost与传统的Boost的区别是,Gradient Boost会定义一个loassFunction,每一次的计算是为了减少上一次的loss,而为了消除loss,我们可以在loss减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的loss往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
Bagging
1)从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping(有放回)的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(我们这里假设k个训练集之间是相互独立的,事实上不是完全独立)2)每次使用一个训练集得到一个模型,k个训练集共得到k个模型。但是是同种模型。(注:,k个训练集虽然有重合不完全独立,训练出来的模型因为是同种模型也是不完全独立。这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
3)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
对于Bagging需要注意的是,每次训练集可以取全部的特征进行训练,也可以随机选取部分特征训练,例如随机森林就是每次随机选取部分特征
讲完Boosting,Bagging,我们来总结下这两种框架算法的异同点:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:理论上各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。计算角度来看,两种方法都可以并行。bagging, random forest并行化方法显而意见。boosting有强力工具stochastic gradient boosting
5)bagging是减少variance,而boosting是减少bias
在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模型的性能(performance)。然而我们学习一个模型的目的是为了解决实际的问题(或者说是训练数据集这个领域(field)中的一般化问题),单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization
error。而generalization error又可以细分为Bias和Variance两个部分。
即error=Bias+Variance
可以通过降低Bias或者降低Variance来减小error
Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均。由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。由于
,所以bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,则有
,此时可以显著降低variance。若各子模型完全相同,则
,此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。为了进一步降低variance,Random
forest通过随机选取变量子集做拟合的方式de-correlated了各子模型(树),使得variance进一步降低。boosting从优化角度来看,是用forward-stagewise这种贪心法去最小化损失函数
。例如,常见的AdaBoost即等价于用这种方法最小化exponential
loss:
。所谓forward-stagewise,就是在迭代的第n步,求解新的子模型f(x)及步长a(或者叫组合系数),来最小化
,这里
是前n-1步得到的子模型的和。因此boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度。
6)Bagging里面每个分类器是强分类器,因为他降低的是方差,方差过高需要降低是过拟合。boosting里面每个分类器是弱分类器,因为他降低的是偏差,偏差过高是欠拟合。
stacking
先讲讲stacking具体的算法流程以上图为例,我们现在有训练集train_x,train_y,测试集test
① 我们首先选择一种模型比如随机森林rf。(未经训练)
②这里假设把训练集均分成5份,把其中四份作为小的训练集s_train_x,s_train_y另外一份作为小的测试集s_test,测试集test不变。
③我们以s_train_x,s_train_y训练rf模型,训练出的模型预测s_test得出对应的s_pred,再预测test得出y_pred。
④在训练集再选择另外一份作为小的测试集s_test_x,其他四份作为训练集训练模型rf。
⑤重复②,③,④步骤五次。我们会得到五个s_pred和五个y_pred。
五个s_pred作为一个train_X,原始的train_y作为train_Y训练模型得到模型G,五个y_pred取个平均值作为新的test_X,把test_X带入到模型G中得出预测结果。
以上就是stacking的第一层,在第二层中,我们以第一层的输出train再结合其他的特征集再做一层stacking。不同的层数之间有各种交互,还有将经过不同的 Preprocessing 和不同的 Feature Engineering 的数据用 Ensemble 组合起来的做法。
上面是以一种模型随机森林进行模型训练,当然可以分别用不同种的模型。
以下代码是典型的stacking第一层
#coidng:utf-8
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold
train=pd.read_csv("train.csv")
test=pd.read_csv("test.csv")
ntrain=train.shape[0] ## 891
ntest=test.shape[0] ## 418
kf=KFold(n_splits=5,random_state=2017)
def get_oof(clf,x_train,y_train,x_test):
oof_train=np.zeros((ntrain,)) ##shape为(ntrain,)表示只有一维 891*1
oof_test=np.zeros((ntest,)) ## 418*1
oof_test_skf=np.empty((5,ntest)) ## 5*418
for i,(train_index,test_index) in enumerate(kf.split(x_train)):
kf_x_train=x_train[train_index] ## (891/5 *4)*7 故shape:(712*7)
kf_y_train=y_train[train_index] ## 712*1
kf_x_test=x_train[test_index] ## 179*7
clf.train(kf_x_train,kf_y_train)
oof_train[test_index]=clf.predict(kf_x_test)
oof_test_skf[i,:]=clf.predict(x_test)
oof_test[:]=oof_test_skf.mean(axis=0)
return oof_train.reshape(-1,1),oof_test.reshape(-1,1)12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28

相关文章推荐
- 机器学习-->集成学习-->Bagging,Boosting,Stacking
- 集成学习(Ensemble Learning)-bagging-boosting-stacking
- python机器学习案例系列教程——集成学习(Bagging、Boosting、随机森林RF、AdaBoost、GBDT、xgboost)
- 机器学习总结(六):集成学习(Boosting,Bagging,组合策略)
- 机器学习(五):Bagging与Boosting
- 【机器学习】Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting
- 集成学习(Ensemble)相关概念及算法(Adaboost,Bagging,Stacking)
- 机器学习之集成学习(六)Bagging与随机森林
- 模式识别与机器学习—bagging与boosting
- 机器学习-->集成学习-->Xgboost详解
- 机器学习-->集成学习-->Xgboost,GBDT,Adaboost总结
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
- 机器学习-->集成学习-->GBDT,RandomForest
- 机器学习-->集成学习-->Adaboost
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
- 【机器学习】Bootstrap--Bagging--Boosting--AdaBoost
- Bagging, boosting and stacking in machine learning
- 模型融合:bagging、Boosting、Blending、Stacking
- 机器学习——boosting 与 bagging 知识点+面试题总结