强化学习之Actor Critic
2017-09-18 17:18
573 查看
参考:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/6-1-actor-critic/
一句话概括 Actor Critic 方法:结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率.
Actor Critic 方法的优势: 可以进行单步更新, 比传统的 Policy Gradient 要快(回合结束更新).
Actor Critic 方法的劣势: 取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题.
Actor 修改行为时就像蒙着眼睛一直向前开车, Critic 就是那个扶方向盘改变 Actor 开车方向的.
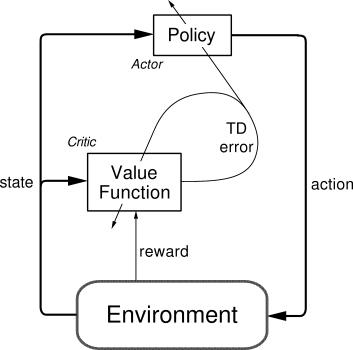
或者说详细点, 就是 Actor 在运用 Policy Gradient 的方法进行 Gradient ascent 的时候, 由 Critic 来告诉他, 这次的 Gradient ascent 是不是一次正确的 ascent, 如果这次的得分不好, 那么就不要 ascent 那么多.
DDPG
它吸收了 Actor critic 让 Policy gradient 单步更新的精华, 而且还吸收让计算机学会玩游戏的 DQN 的精华, 合并成了一种新算法, 叫做 Deep Deterministic Policy Gradient一句话概括 DDPG: Google DeepMind 提出的一种使用 Actor Critic 结构, 但是输出的不是行为的概率, 而是具体的行为, 用于连续动作 (continuous action) 的预测. DDPG 结合了之前获得成功的 DQN 结构, 提高了
Actor Critic 的稳定性和收敛性.
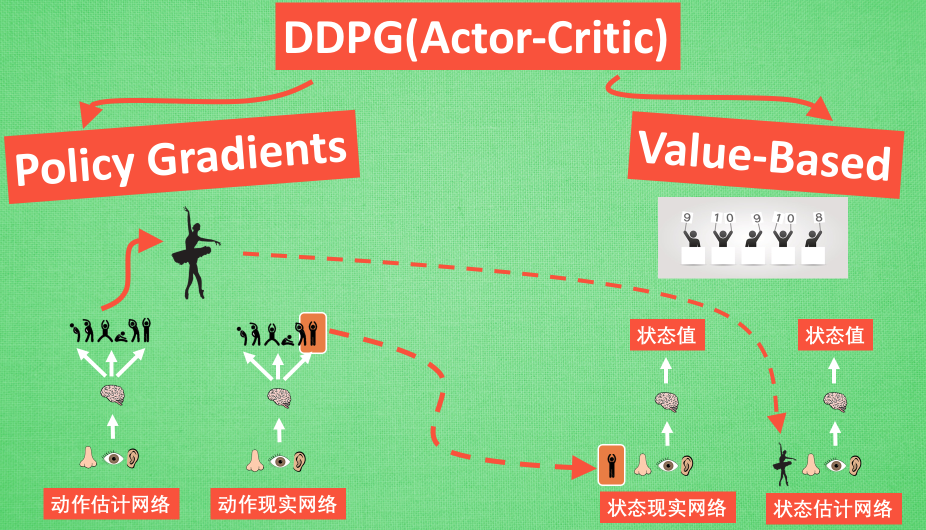
现在我们来说说 DDPG 中所用到的神经网络. 它其实和我们之前提到的 Actor-Critic 形式差不多, 也需要有基于策略 Policy 的神经网络和基于价值 Value 的神经网络, 但是为了体现 DQN 的思想, 每种神经网络我们都需要再细分为两个, Policy Gradient 这边, 我们有估计网络和现实网络, 估计网络用来输出实时的动作, 供 actor 在现实中实行. 而现实网络则是用来更新价值网络系统的. 所以我们再来看看价值系统这边, 我们也有现实网络和估计网络, 他们都在输出这个状态的价值,
而输入端却有不同, 状态现实网络这边会拿着从动作现实网络来的动作加上状态的观测值加以分析, 而状态估计网络则是拿着当时 Actor 施加的动作当做输入.在实际运用中, DDPG 的这种做法的确带来了更有效的学习过程.
DDPG中,actor网络的输入是state,输出Action,以DNN进行函数拟合,对于连续动作NN输出层可以用tanh或sigmod,离散动作以softmax作为输出层则达到概率输出的效果。Critic网络的输入为state和action,输出为Q值。

A3C(Asynchronous Advantage Actor-Critic)
我们知道目前的计算机多半是有双核, 4核, 甚至 6核, 8核. 一般的学习方法, 我们只能让机器人在一个核上面玩耍. 但是如果使用 A3C 的方法, 我们可以给他们安排去不同的核, 并行运算. 实验结果就是, 这样的计算方式往往比传统的方式快上好多倍.
一句话概括 A3C: Google DeepMind 提出的一种解决 Actor-Critic 不收敛问题的算法. 它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所以更新的相关性被降低, 收敛性提高.

一句话概括 Actor Critic 方法:结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率.
Actor Critic 方法的优势: 可以进行单步更新, 比传统的 Policy Gradient 要快(回合结束更新).
Actor Critic 方法的劣势: 取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题.
Actor 修改行为时就像蒙着眼睛一直向前开车, Critic 就是那个扶方向盘改变 Actor 开车方向的.
或者说详细点, 就是 Actor 在运用 Policy Gradient 的方法进行 Gradient ascent 的时候, 由 Critic 来告诉他, 这次的 Gradient ascent 是不是一次正确的 ascent, 如果这次的得分不好, 那么就不要 ascent 那么多.
DDPG
它吸收了 Actor critic 让 Policy gradient 单步更新的精华, 而且还吸收让计算机学会玩游戏的 DQN 的精华, 合并成了一种新算法, 叫做 Deep Deterministic Policy Gradient一句话概括 DDPG: Google DeepMind 提出的一种使用 Actor Critic 结构, 但是输出的不是行为的概率, 而是具体的行为, 用于连续动作 (continuous action) 的预测. DDPG 结合了之前获得成功的 DQN 结构, 提高了
Actor Critic 的稳定性和收敛性.
现在我们来说说 DDPG 中所用到的神经网络. 它其实和我们之前提到的 Actor-Critic 形式差不多, 也需要有基于策略 Policy 的神经网络和基于价值 Value 的神经网络, 但是为了体现 DQN 的思想, 每种神经网络我们都需要再细分为两个, Policy Gradient 这边, 我们有估计网络和现实网络, 估计网络用来输出实时的动作, 供 actor 在现实中实行. 而现实网络则是用来更新价值网络系统的. 所以我们再来看看价值系统这边, 我们也有现实网络和估计网络, 他们都在输出这个状态的价值,
而输入端却有不同, 状态现实网络这边会拿着从动作现实网络来的动作加上状态的观测值加以分析, 而状态估计网络则是拿着当时 Actor 施加的动作当做输入.在实际运用中, DDPG 的这种做法的确带来了更有效的学习过程.
DDPG中,actor网络的输入是state,输出Action,以DNN进行函数拟合,对于连续动作NN输出层可以用tanh或sigmod,离散动作以softmax作为输出层则达到概率输出的效果。Critic网络的输入为state和action,输出为Q值。
A3C(Asynchronous Advantage Actor-Critic)
我们知道目前的计算机多半是有双核, 4核, 甚至 6核, 8核. 一般的学习方法, 我们只能让机器人在一个核上面玩耍. 但是如果使用 A3C 的方法, 我们可以给他们安排去不同的核, 并行运算. 实验结果就是, 这样的计算方式往往比传统的方式快上好多倍.
一句话概括 A3C: Google DeepMind 提出的一种解决 Actor-Critic 不收敛问题的算法. 它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所以更新的相关性被降低, 收敛性提高.

相关文章推荐
- 深度强化学习之Policy Gradient & Actor-Critic Model & A3C
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
- 深度增强学习(DRL)漫谈 - 从AC(Actor-Critic)到A3C(Asynchronous Advantage Actor-Critic)
- 强化学习——A3C,GA3C
- DeepMind最新论文提出「Rainbow」,将深度强化学习组合改进
- 强化学习ROS实战-RLagent解析(上)
- TensorFlow实战13:实现策略网络(强化学习一)
- 强化知识,刻苦学习
- 对深度强化学习的理解
- CS294--深度强化学习
- 强化学习-几个基本概念
- Akka学习笔记:Actor消息处理-请求和响应(2)
- Akka学习笔记:子Actor和Actor路径
- 【Java强化】Java强化学习之路
- 强化学习之五:基于模型的强化学习(Model-based RL)
- 第95讲:Akka第一个案例动手实战MasterActor代码详解学习笔记
- 深度强化学习中的DQN系列算法
- c++学习笔记 内存四区 函数调用模型 指针强化
- Tensorflow实现策略网络(深度强化学习一)
- 强化学习用于发掘GAN在NLP领域的潜力