python3模拟登录知乎
2017-09-17 15:01
465 查看
1,前言
在爬虫的世界里,模拟登录是一项必备的技能,很多网站登录才能有浏览信息的权限,今天就在python来模拟登录知乎
2,获取登录时post的参数
在网页上输入知乎的url:https://www.zhihu.com/#signin,随便输入一个手机号(13265604588)和密码(1234),按f12,然后点击登录,在 network就能获取提交的表单
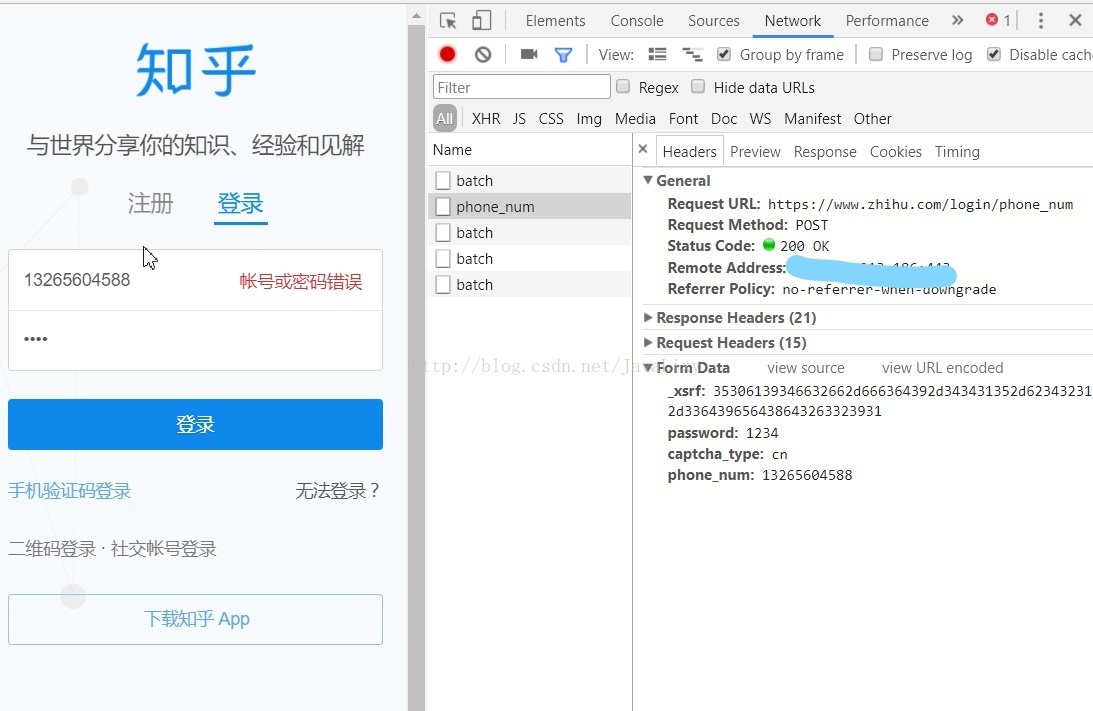
这里登录时需要提交的数据有四个:手机号码和密码由我们自己输入,_xsrf 为知乎的隐藏随机码,captcha_type 为验证码类型
请求的url是:https://www.zhihu.com/login/phone_num,后面会用到
2.1 获取_xsrf
在登录页面右键检查网页源码,就可以在提交表单那里发现
<input type="hidden" name="_xsrf" value="
">
这个通过一个正则表达式就可以提取出来
其中在提取那里(.*?)要注意加入问号取消贪婪匹配
方法代码如下:
2.2 获取验证码
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
print(captcha_url)
response = session.get(captcha_url, headers=header)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
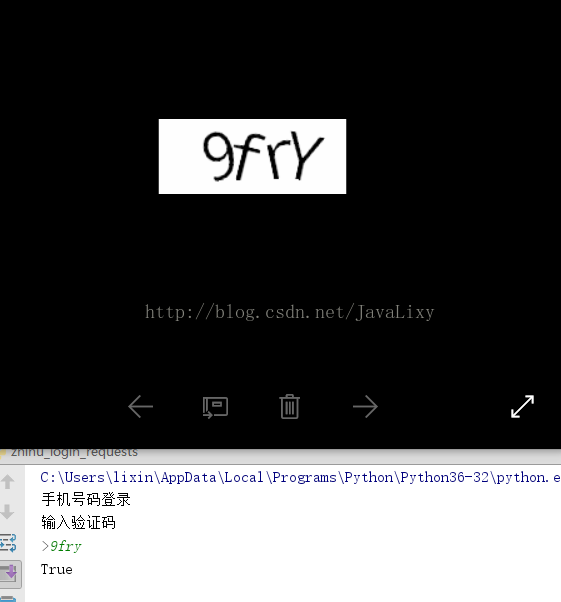
captcha = input('请输入验证码: ')
return captcha这里的获取验证码需要人工验证,按照生成的gif输入即可
3,创建登录函数
4,检验登录是否成功
在未登录成功时是无法访问查询个人私信的网站:https://www.zhihu.com/inbox
在网页上输入该网址
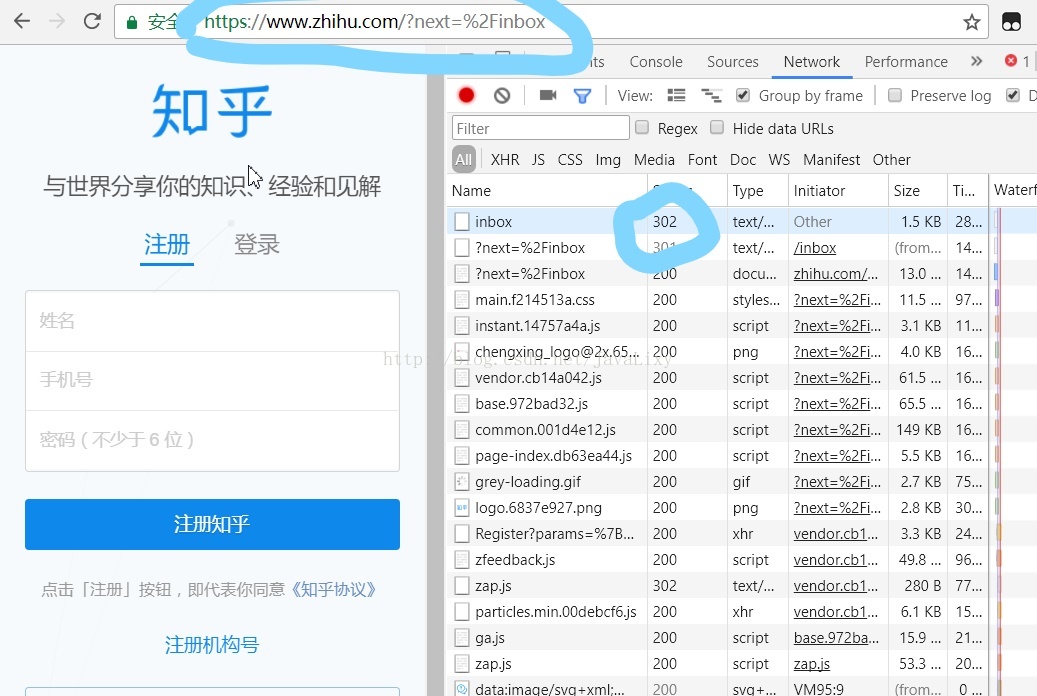
可以看到访问身份信息为302即临时跳转,知乎将我们网址跳转到登录界面,即没有访问权限,可以通过检验response的身份信息来检验是否登录成功,代码如下
这里注意session的allow_redirects参数, 取消了网页重定向功能。如果不取消,即使访问失败也会重新跳转到登录界面,这样返回的身份信息还是 200
5,完整代码
在爬虫的世界里,模拟登录是一项必备的技能,很多网站登录才能有浏览信息的权限,今天就在python来模拟登录知乎
2,获取登录时post的参数
在网页上输入知乎的url:https://www.zhihu.com/#signin,随便输入一个手机号(13265604588)和密码(1234),按f12,然后点击登录,在 network就能获取提交的表单
这里登录时需要提交的数据有四个:手机号码和密码由我们自己输入,_xsrf 为知乎的隐藏随机码,captcha_type 为验证码类型
请求的url是:https://www.zhihu.com/login/phone_num,后面会用到
2.1 获取_xsrf
在登录页面右键检查网页源码,就可以在提交表单那里发现
<input type="hidden" name="_xsrf" value="
37616639663361332d393965632d346634632d396166362d356538383763653738367
">
这个通过一个正则表达式就可以提取出来
text = '<input type="hidden" name="_xsrf" value="37616639663361332d393965632d346634632d396166362d356538383763653738367">'
match_obj = re.match('.*name="_xsrf" value="(.*?)"',text)if match_obj: print (match_obj.group(1))
其中在提取那里(.*?)要注意加入问号取消贪婪匹配
方法代码如下:
def get_xsrf():
#获取xsrf code
response = session.get("https://www.zhihu.com",headers = header)
match_obj = re.match('.*name="_xsrf" value="(.*?)"',response.text)
# print(match_obj.group(1))
if match_obj:
return (match_obj.group(1))
return ""2.2 获取验证码
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
print(captcha_url)
response = session.get(captcha_url, headers=header)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('请输入验证码: ')
return captcha这里的获取验证码需要人工验证,按照生成的gif输入即可
3,创建登录函数
import requests
import re
session =requests.session()
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.91 Safari/537.36"
header = {
"HOST":"www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': agent
}def zhihu_login(account,password):
#知乎登录
if re.match("^1\d{10}",account):
print("手机号码登录")#前面提取的手机号码登录请求url
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf": get_xsrf(),
"phone_num": account,
"password": password,
"captcha":get_captcha()
}
response_text = session.post(post_url,data=post_data,headers=header)这样结合之前的的get_xsrf,get_captcha方法就能顺利登录知乎了,如何验证?4,检验登录是否成功
在未登录成功时是无法访问查询个人私信的网站:https://www.zhihu.com/inbox
在网页上输入该网址
可以看到访问身份信息为302即临时跳转,知乎将我们网址跳转到登录界面,即没有访问权限,可以通过检验response的身份信息来检验是否登录成功,代码如下
def is_login(): #通过个人中心页面返回状态码来判断是否为登录状态 inbox_url = "https://www.zhihu.com/inbox" #allow_redirects使重定向为false response = session.get(inbox_url, headers=header, allow_redirects=False) if response.status_code != 200: return False else: return True
这里注意session的allow_redirects参数, 取消了网页重定向功能。如果不取消,即使访问失败也会重新跳转到登录界面,这样返回的身份信息还是 200
5,完整代码
import requests运行结果:
import re
session =requests.session()
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.91 Safari/537.36"
header = {
"HOST":"www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': agent
}
def get_xsrf():
#获取xsrf code
response = session.get("https://www.zhihu.com",headers = header)
# print(response.text)
# text = '<input type="hidden" name="_xsrf" value="37616639663361332d393965632d346634632d396166362d356538383763653738363637">'
match_obj = re.match('.*name="_xsrf" value="(.*?)"',response.text)
# print(match_obj.group(1))
if match_obj:
return (match_obj.group(1))
return ""
def get_captcha():
import time
t = str(int(time.time()*1000))
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
t = session.get(captcha_url, headers=header)
with open("captcha.jpg","wb") as f:
f.write(t.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
pass
captcha = input("输入验证码\n>")
return captcha
def zhihu_login(account,password): #知乎登录 if re.match("^1\d{10}",account): print("手机号码登录")
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf": get_xsrf(),
"phone_num": account,
"password": password,
"captcha":get_captcha()
}
response_text = session.post(post_url,data=post_data,headers=header)
def is_login(): #通过个人中心页面返回状态码来判断是否为登录状态 inbox_url = "https://www.zhihu.com/inbox" #allow_redirects使重定向为false response = session.get(inbox_url, headers=header, allow_redirects=False) if response.status_code != 200: return False else: return True
zhihu_login("yourPhoneNumber","password")
print(is_login())

相关文章推荐
- python--python3爬虫之模拟登录知乎
- 使用Python模拟登录知乎
- 使用python脚本模拟登录知乎
- 【python爬虫01】使用requests库模拟登录知乎
- Python网络爬虫之模拟登录(以知乎为例)
- python之selenium模拟登录知乎
- python模拟登录知乎
- python 模拟知乎登录
- Python爬虫之模拟知乎登录的方法教程
- [Python]网络爬虫(三):使用cookiejar管理cookie 以及 模拟登录知乎
- 【python爬虫03】使用Scrapy框架模拟登录知乎
- python-知乎模拟登录
- Python网络爬虫之模拟登录(以知乎为例)
- python 利用浏览器 Cookie 模拟登录的用户访问知乎
- Python爬虫初学(三)—— 模拟登录知乎
- Python 模拟登录知乎
- python模拟登录知乎
- 如何利用python模拟登录(附源码)
- Python 爬虫模拟登陆知乎
- Python爬虫模拟登录带验证码网站