[NLP论文阅读] Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning
2017-09-14 16:13
609 查看
论文原文:Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning
你的模型是用来学习句子表示的是吧?那么你的模型是不是也要能判断两句相邻句子的前后顺序?这就是第一个任务,训练模型能判断两句句子的顺序,作者称之为ORDER。
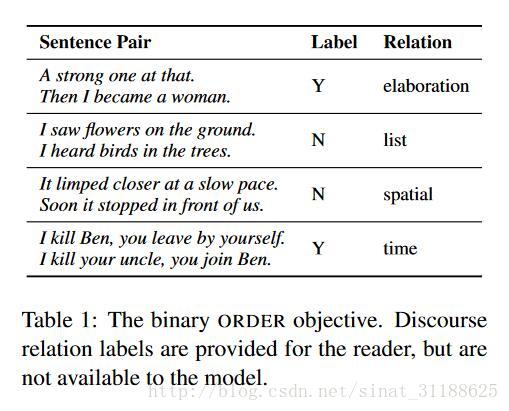
这个表展示了数据集中的4个句子对,如果两句句子排序正确,那么Label就是Y,否则就是N。当然我们不难发现,对于list关系,两个句子是并列的,谁前谁后很难判断。当然这种情况不是很多。
Next Sentence

以上是作者的理论基础吧,没有明白是什么意思。
这个预训练任务,希望句子编码器学习的句子表示能够具备根据段落中连续的3句话,判断出下一句是候选集合中的哪一句的能力。
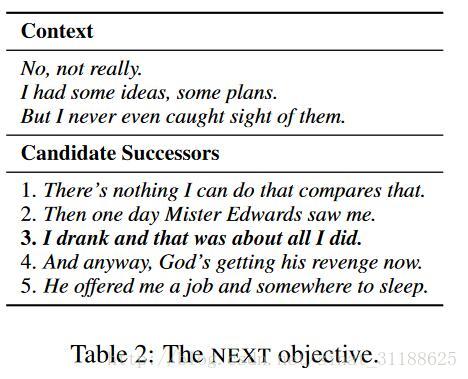
文中的例子如上,给出Context中的3句话,要在Candidate中选出紧随其后的那一句(加粗的那句话)。
Conjunction Prediction
第三个任务是连接词预测。作者将语料库中所有第二句是以连接词开头的句子对抽取出来,隐藏了连接词。然后希望句子编码器学习的句子表示能让分类器正确的找到输入句子对之间的连接关系。
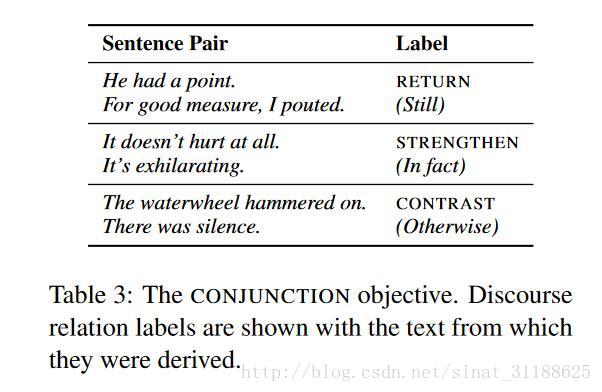
以上是作者提供的例子,作者将所有连接词都找了出来,然后进行了分类,分成了如下几类:
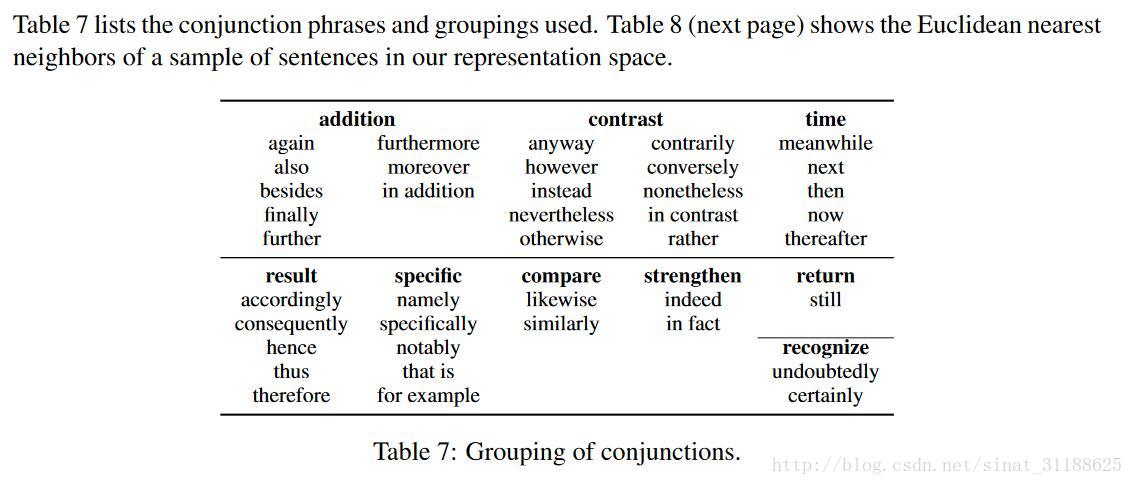
然后希望编码器学习的句子表示在输入分类器后能正确被分类。
总的来说,作者的想法就是,你要学习到好的句子表示,那么你的句子表示肯定要有丰富的内涵,那些内涵是什么呢,就是能区别向邻句子的顺序关系、能根据前文预测下文、能正确判断句子之间的连接关系。你要是这些都做不到,凭什么说你的句子表示优秀呢。
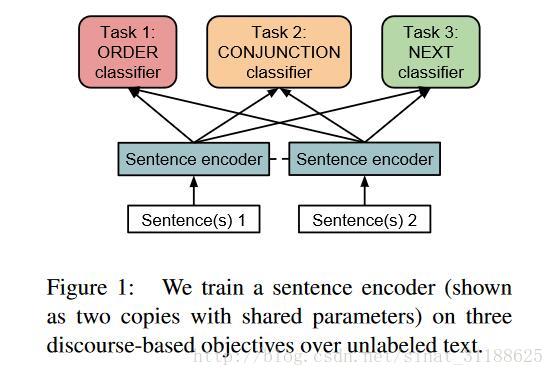
三个预训练任务分别是Task1~3。
可以看到作者在训练sentence encoder时,可以针对每个Task单独训练,也可以3个Task联合训练。
作者所使用的sentence encoder共有3个,分别是:
1. 1024D sum-of-word(CBOW);
2. 1024D GRU recurrent neural network (Cho et al., 2014);
3. 512D bidirectional GRU RNN (BiGRU).
sentence encoder的输出会成为后续的bilinear classifiers的输入,最后输出分类结果。
the Gutenberg project (Stroube, 2003);
Wikipedia
从上述三个数据集中,作者将所有包含8句句子以上的段落抽取出来,找到了40M examples for
ORDER, 1.4M for CONJUNCTION , and 4.1M for NEXT.
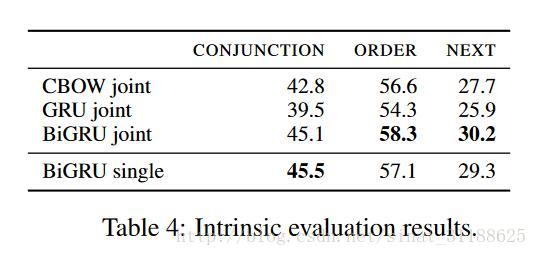
可以看到joint训练的效果应该说比单独训练要好,这几个任务之间可能还存在相通的地方,多学一点能触类旁通:)
经过预训练后的句子编码器和现有的模型进行比较
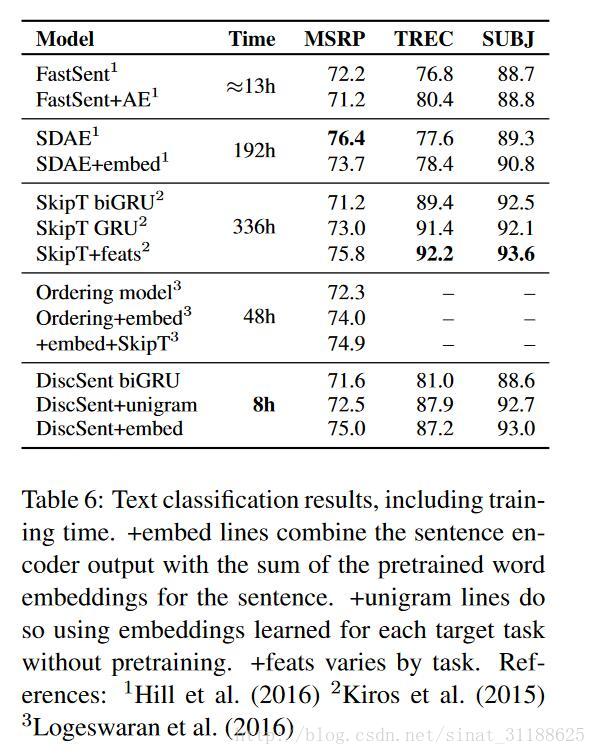
在这里作者把通过他的系统预训练过的句子编码器称之为DiscSent。
从结果中发现,经过预训练的句子编码器在几个公共语料库中的实际效果没有优于现有的模型,所以会的东西多也没有用吗?这时候我们注意到还有一列展示了模型的训练时间,作者发现,我会的东西多了,学起来就是比别人快,而且最后的效果也和最优秀的结果相差不多。
欢迎一起讨论~~~
2017年9月14日 上海。
引言
这篇文章的想法很有意思,为了学习到更好的句子表示,作者没有去设计新的模型来学习句子表示,而是设计了3个预训练目标来预训练已有的句子编码器(Sentence encoder),当模型经过这3个预训练后在针对目标任务进行训练。就好比,你要练一门神功,你最好要先练好基本功。作者发现模型学习到的句子表示虽然没有显著得优于当前最新结果,但是训练时间大大减少了。预训练任务
Binary Ordering of Sentences你的模型是用来学习句子表示的是吧?那么你的模型是不是也要能判断两句相邻句子的前后顺序?这就是第一个任务,训练模型能判断两句句子的顺序,作者称之为ORDER。
这个表展示了数据集中的4个句子对,如果两句句子排序正确,那么Label就是Y,否则就是N。当然我们不难发现,对于list关系,两个句子是并列的,谁前谁后很难判断。当然这种情况不是很多。
Next Sentence
以上是作者的理论基础吧,没有明白是什么意思。
这个预训练任务,希望句子编码器学习的句子表示能够具备根据段落中连续的3句话,判断出下一句是候选集合中的哪一句的能力。
文中的例子如上,给出Context中的3句话,要在Candidate中选出紧随其后的那一句(加粗的那句话)。
Conjunction Prediction
第三个任务是连接词预测。作者将语料库中所有第二句是以连接词开头的句子对抽取出来,隐藏了连接词。然后希望句子编码器学习的句子表示能让分类器正确的找到输入句子对之间的连接关系。
以上是作者提供的例子,作者将所有连接词都找了出来,然后进行了分类,分成了如下几类:
然后希望编码器学习的句子表示在输入分类器后能正确被分类。
总的来说,作者的想法就是,你要学习到好的句子表示,那么你的句子表示肯定要有丰富的内涵,那些内涵是什么呢,就是能区别向邻句子的顺序关系、能根据前文预测下文、能正确判断句子之间的连接关系。你要是这些都做不到,凭什么说你的句子表示优秀呢。
示意图
三个预训练任务分别是Task1~3。
可以看到作者在训练sentence encoder时,可以针对每个Task单独训练,也可以3个Task联合训练。
作者所使用的sentence encoder共有3个,分别是:
1. 1024D sum-of-word(CBOW);
2. 1024D GRU recurrent neural network (Cho et al., 2014);
3. 512D bidirectional GRU RNN (BiGRU).
sentence encoder的输出会成为后续的bilinear classifiers的输入,最后输出分类结果。
数据
BookCorpus (Zhu et al., 2015);the Gutenberg project (Stroube, 2003);
Wikipedia
从上述三个数据集中,作者将所有包含8句句子以上的段落抽取出来,找到了40M examples for
ORDER, 1.4M for CONJUNCTION , and 4.1M for NEXT.
实验结果
三个任务联合训练以及单独训练的性能比较可以看到joint训练的效果应该说比单独训练要好,这几个任务之间可能还存在相通的地方,多学一点能触类旁通:)
经过预训练后的句子编码器和现有的模型进行比较
在这里作者把通过他的系统预训练过的句子编码器称之为DiscSent。
从结果中发现,经过预训练的句子编码器在几个公共语料库中的实际效果没有优于现有的模型,所以会的东西多也没有用吗?这时候我们注意到还有一列展示了模型的训练时间,作者发现,我会的东西多了,学起来就是比别人快,而且最后的效果也和最优秀的结果相差不多。
总结
虽然作者提出的方法在他们的实验中,没有取得state-of-the-art的结果,但是从数据上来看,确实大大加快了训练速度。可能训练速度可以通过买更好更多的设备来获得,所以快了那么点也没什么稀奇的。不过,我觉得作者的思想还是值得学习的。你要去和人家华山论剑,你起码要会内功,剑法吧。欢迎一起讨论~~~
2017年9月14日 上海。

相关文章推荐
- [NLP论文阅读]A simple but tough-to-beat baseline for sentence embedding
- 论文阅读理解 - Deep Learning of Binary Hash Codes for Fast Image Retrieval
- [NLP论文阅读]Siamese CBOW: OptimizingWord Embeddings for Sentence Representations
- [NLP论文阅读] Supervised Learning of Universal Sentence Representations from NLI data
- 论文阅读:Knowledge Based Segmentation for Fast 3D Dental Reconstruction from CBCT
- [NLP论文阅读] Learning Paraphrastic Sentence Embeddings from Back-Translated Bitext
- 论文阅读:BoVW-MI:TASK DRIVEN DICTIONARY LEARNING BASED ON MUTUAL INFORMATION FOR MEDICAL IMAGE CLASSIFIC
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
- 谷歌论文阅读:Building High-level Features Using Large Scale Unsupervised Learning
- Deep Learning for Content-Based Image Retrival:A Comprehensive Study 论文笔记
- 论文笔记之:DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- 《Context Aware Query Image Representation for Particular Object Retrieval》论文阅读
- 【论文阅读笔记】Deep Learning based Recommender System: A Survey and New Perspectives
- 论文阅读《Deep Learning for Identifying Metastatic Breast Cancer》
- 论文阅读之 A Convex Optimization Framework for Active Learning
- 生成对抗网络学习笔记3----论文unsupervised representation learning with deep convolutional generative adversarial
- 论文阅读-《Learning Deep Features for Discriminative Localization》
- 读论文-Asymmetric Actor Critic for Image-Based Robot Learning
- [论文阅读]Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks