[NLP论文阅读] The Fixed-Size Ordinally-Forgetting Encoding Method for Neural Network Language Models
2017-10-18 14:05
816 查看
论文原文:The Fixed-Size Ordinally-Forgetting Encoding Method for Neural Network Language Models
zt=α∗zt−1+et(1≤t≤T)
其中,zt表示从输入序列中由第一个单词w1直到第t个单词wt组成的子序列的FOFE编码(假设z0=0),α是forgeting factor(常数),et是单词wt对应的one-hot向量。
那么,zT就可以看作是对序列w1,w2,...,wT的一种向量表示。
举例来说,如果词表为
A=[1,0,0]
B=[0,1,0]
C=[0,0,1]
那么,通过计算可以得到
ABC=[α2,α,1]
ABCBC=[α4,α+α3,1+α2]
FOFE编码有2个比较好的性质:
1. 如果0<α≤0.5,那么FOFE对任意K和T都是唯一的。
2. 如果0.5<α<1,那么FOFE对于大多数K和T都是唯一的,只有有限个α的取值是例外。
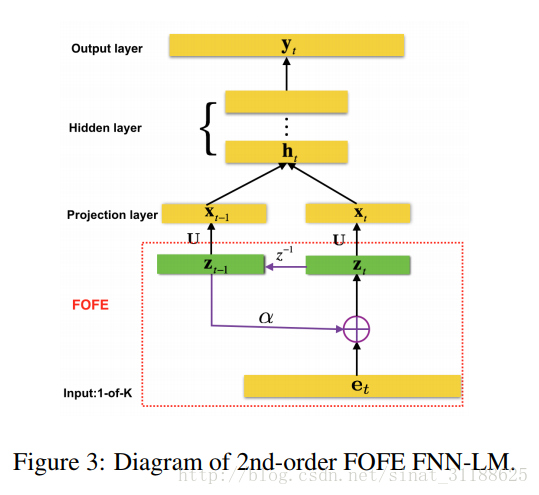
传统的神经概率语言模型(Bengio提出的)在输入层用的是one-hot向量,然后通过词向量矩阵映射成一个低维的实值向量(如果是n-gram模型,词向量维度为m,那么就将前n-1个单词对应的词向量首尾相连成一个m(n-1)维的向量),然后通过隐藏层的计算,在输出层形成输出。
在这篇文章中,作者的做的改动在输入层。作者将原本输出层的one-hot向量替换成了FOFE编码。使用FOFE编码前n-1个单词的过程中,会渐渐弱化出现较早的单词对最终编码的影响,这也就是说,作者认为距离目标词越近的单词已接近对目标词的影响更大。并且,使用FOFE编码可以减小在投影层的生成的向量的维度,如果是1阶的FOFE FNN-LMs,那么投影层的维度就是m(词向量的维度),但是这不会降低复杂度。
1. the Penn Treebank(PTB) corpus(约有1000000单词,词表大小为10000)
2. The Large Text Compression Benchmark(LTCB),在这个数据集作者使用了enwik9数据集,是enwiki-20060303-pages-articles.xml的头109字节数据,其中训练集153M, 验证集8.9M, 测试集8.9M, 词表大小为80000,不在词表中的单词用< UNK >标记。
通常评价一个语言模型的好坏使用的指标是迷惑度/困惑度/混乱度(preplexity),其基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,具体公式如下:
PP(W)=P(w1w2...wN)−1N
链式规则: PP(W)=∏Ni=11P(wi|w1...wi−1)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√N
如果是bigram: PP(W)=∏Ni=11P(wi|wi−1)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√N
preplexity越小,句子概率越大,语言模型越好。
作者设计了2种FOFE-FNNLM模型,分别是1st-order FOFE-FNNLM和2nd-order FOFE-FNNLM,前者在输入层使用zt作为输入,后者则使用zt和zt−1作为输入。
在实验中,α的取值为0.7。
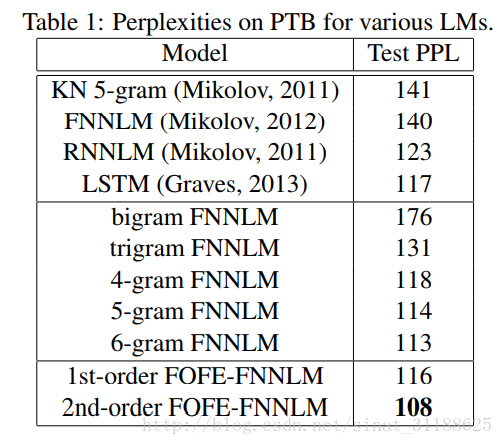
在PTB上的实验结果:
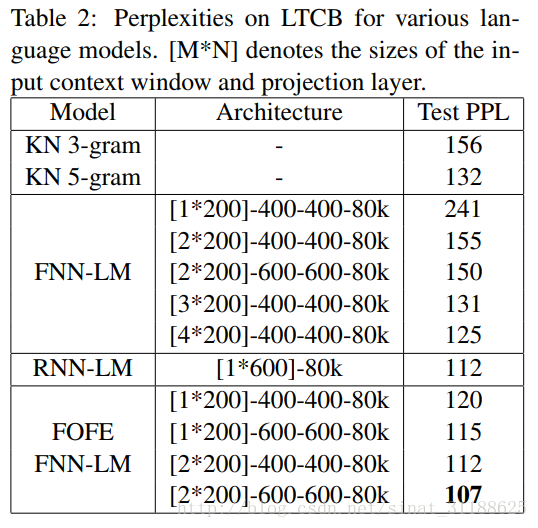
在LTCB上的实验结果:
Next, FOFE may be combined with neural networks (Zhang and Jiang, 2015; Zhang et. al., 2015b) for other NLP tasks, such as sentence modeling/matching, paraphrase detection, machine translation, question and answer and etc.
从实验结果来看,作者提出的对序列进行编码的FOFE方法是有效的,并且和RNN相比,这个方法简单,训练速度更快,可以在句子建模中进行尝试。
2017.10.18 上海。
引言
这篇文章提出了一种学习不定长序列表示的方法,并将该方法用于前反馈神经网络的语言模型(feedforward neural network language models, FNN-LMs),得到了不错的实验数据。作者通过用FOFE编码的序列替换FNN-LMs中原有的输入层实现了对FNN语言模型的改进。Fixed-size Ordinally Forgetting Encoding
给定词表大小(vocabulary size)为K,FOFE使用one-hot编码来表示,每一个单词,即一个K维向量来表示单词。FOFE使用下列公式对不定长序列进行编码:zt=α∗zt−1+et(1≤t≤T)
其中,zt表示从输入序列中由第一个单词w1直到第t个单词wt组成的子序列的FOFE编码(假设z0=0),α是forgeting factor(常数),et是单词wt对应的one-hot向量。
那么,zT就可以看作是对序列w1,w2,...,wT的一种向量表示。
举例来说,如果词表为
A=[1,0,0]
B=[0,1,0]
C=[0,0,1]
那么,通过计算可以得到
ABC=[α2,α,1]
ABCBC=[α4,α+α3,1+α2]
FOFE编码有2个比较好的性质:
1. 如果0<α≤0.5,那么FOFE对任意K和T都是唯一的。
2. 如果0.5<α<1,那么FOFE对于大多数K和T都是唯一的,只有有限个α的取值是例外。
模型
传统的神经概率语言模型(Bengio提出的)在输入层用的是one-hot向量,然后通过词向量矩阵映射成一个低维的实值向量(如果是n-gram模型,词向量维度为m,那么就将前n-1个单词对应的词向量首尾相连成一个m(n-1)维的向量),然后通过隐藏层的计算,在输出层形成输出。
在这篇文章中,作者的做的改动在输入层。作者将原本输出层的one-hot向量替换成了FOFE编码。使用FOFE编码前n-1个单词的过程中,会渐渐弱化出现较早的单词对最终编码的影响,这也就是说,作者认为距离目标词越近的单词已接近对目标词的影响更大。并且,使用FOFE编码可以减小在投影层的生成的向量的维度,如果是1阶的FOFE FNN-LMs,那么投影层的维度就是m(词向量的维度),但是这不会降低复杂度。
实验
作者在2个数据集进行了对比实验。1. the Penn Treebank(PTB) corpus(约有1000000单词,词表大小为10000)
2. The Large Text Compression Benchmark(LTCB),在这个数据集作者使用了enwik9数据集,是enwiki-20060303-pages-articles.xml的头109字节数据,其中训练集153M, 验证集8.9M, 测试集8.9M, 词表大小为80000,不在词表中的单词用< UNK >标记。
通常评价一个语言模型的好坏使用的指标是迷惑度/困惑度/混乱度(preplexity),其基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,具体公式如下:
PP(W)=P(w1w2...wN)−1N
链式规则: PP(W)=∏Ni=11P(wi|w1...wi−1)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√N
如果是bigram: PP(W)=∏Ni=11P(wi|wi−1)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√N
preplexity越小,句子概率越大,语言模型越好。
作者设计了2种FOFE-FNNLM模型,分别是1st-order FOFE-FNNLM和2nd-order FOFE-FNNLM,前者在输入层使用zt作为输入,后者则使用zt和zt−1作为输入。
在实验中,α的取值为0.7。
在PTB上的实验结果:
在LTCB上的实验结果:
总结
作者在Conclusions中写道:Next, FOFE may be combined with neural networks (Zhang and Jiang, 2015; Zhang et. al., 2015b) for other NLP tasks, such as sentence modeling/matching, paraphrase detection, machine translation, question and answer and etc.
从实验结果来看,作者提出的对序列进行编码的FOFE方法是有效的,并且和RNN相比,这个方法简单,训练速度更快,可以在句子建模中进行尝试。
2017.10.18 上海。

相关文章推荐
- 论文笔记-An Analysis of Deep Neural Network Models for Practical Applications
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
- [NLP论文阅读]A Neural Knowledge Language Model(一)
- 论文笔记——ThiNet: A Filter Level Pruning Method for Deep Neural Network Compreesion
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
- 【每周一文】A Primer On Neural Network Models for NLP
- 论文阅读:Sparsifying Neural Network Connections for Face Recognition
- 【Deep Learning学习笔记】NEURAL NETWORK BASED LANGUAGE MODELS FOR HIGHLY INFLECTIVE LANGUAGES_google2009
- A Diversity-Promoting Objective Function for Neural Conversation Models 论文阅读零散笔记
- A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读笔记
- [NLP论文阅读] Word Embedding based on Fixed-Size Ordinally Forgetting Encoding
- 论文阅读笔记:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- MSCNN 论文解析(A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- NLP论文研读之路:A Neural Probabilistic Language Model
- [文献阅读]A Convolutional Neural Network Cascade for Face Detection
- 论文阅读:A Critical Review of Recurrent Neural Networks for Sequence Learning
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 【论文阅读】 输入法相关论文二 LONG SHORT TERM MEMORY NEURAL NETWORK
- NLP论文笔记1:Neural Architectures for Named Entity Recognition
- 《3D Convolutional Neural Networks for Human Action Recognition》论文阅读笔记