[翻译]高并发框架 LMAX Disruptor 介绍
2017-09-14 10:31
232 查看
原文地址:Concurrency with LMAX Disruptor – An Introduction
首先
要为以后难以在工作中用到 Disruptor 而感到沮丧。因为据介绍来看,它号称"能够在一个线程里每秒处理6百万订单" 。我所在的平台撑不起这个量,同时也限于学历跟从业背景难以去这类大公司供职。
其次
追逐性能,常常来说你给老板省了多少硬件,老板是看不到的。
建议一开始还是不要设计得性能太过优秀,不然老板看不到你的价值。
最后
Disruptor 是一个在并发编程中避免资源竞争的容器,用于协调生产者与消费者之间的关系,同时有着领域驱动模型 CQRS框架那种基于命令的影子。
应用这个框架编写代码将会较为繁复,模块与模块之前的通信全由一个又一个Event类来协调。
相对于大多数喜欢一个方法到底的开发同学来说会比较麻烦,毕竟需要定义更多类。
我们还将介绍 Disruptor 库的基本用法。
如此高效的性能优化,是通过更高效的利用底层硬件的设计实现。
举个栗子,
通常采用锁来解决资源竞争(write contention)问题,但与此同时又会陷入内核级别的上下文切换。当这种情况发生时,处理器所缓存的数据可能丢失。(译者注:当线程A、B分别在CPU上不同的两个内核上运行时,线程A正要更新变量Y。不幸的是,这个变量也同时正要被线程B所更新。如果核心A获得了所有权,缓存子系统将会使核心B中对应的缓存行失效。当核心B获得了所有权然后执行更新操作,核心A就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。)
为了达到更好的线程可伸缩性,就必须确保不会有两个写线程操作同一个变量(多个读线程是没有问题的,如同处理器间调用高速链接获取缓存)。队列,它败在了独立写入原则(one-writer principle)。
如果两个不同的线程写入队列中两个不同的值,那么每个内核都会使另外一个线程的缓存行失效(数据在主内存与高速缓存之间的传输是做的固定大小的块传输,称之为缓存行。译者注:伪共享和缓存行)。尽管两个线程写入两个不同的变量,也同样会引起它们间的资源竞争。这叫做伪共享,因为每次访问队列头(head),队列尾(tail)也同样会被加载到缓存行,反之亦然。
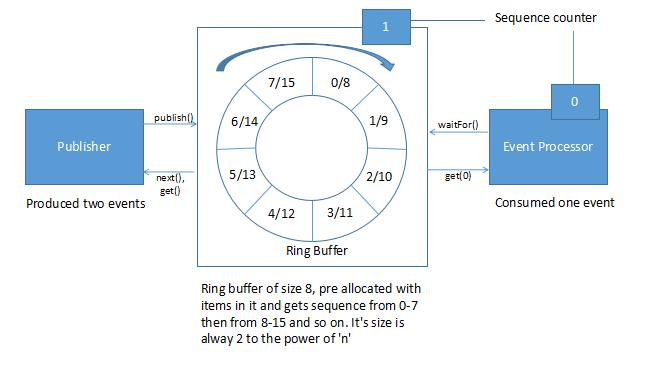
Disruptor 有一个基于数组的循环数据结构(环装缓冲区)。这个循环数据结构,它是个拥有下个可用元素引用的数组。预先分配了对象内存空间。生产者与消费者通过这个循环数据结构进行读写操作,并不会有锁或资源竞争。
在Disruptor 中,所有事件(events)以组播的方式被发布给所有消费者,以便下游队列通过并行的方式进行消费。因为消费者的并行消费,需要协调消费者间的依赖关系(依赖关系图)。
生产者和消费者中有个序列计数器,指示缓冲区中当前正在被它所处理的元素。所有生产者或消费者都只可以修改它自己的序列计数器,但同时可以读取其他的序列计数器。
最新版本的依赖关系可以在这里找到。
这个 EventFactory 会让 Disruptor分配事件。
在我们的示例中,消费者只是打印打印日志。
在这个 Disruptor 的构造方法中,依次定义了以下参数:
Event Factory – 负责生成用于填充环装缓冲区的事件对象;
The size of Ring Buffer – 定义环装缓冲区的大小。它必须是2的幂,否则会在初始化时抛出异常。因为重点在于使用逻辑二进制运算符有着更好的性能;(例如:mod运算)
Thread Factory – 事件处理线程创建工厂;
Producer Type – 指定是否有单个或者多个生产者;
Waiting strategy – 定义如何处理无法跟上生产者步伐的慢消费者;
连接消费者处理程序:
Disruptor可以提供多个消费者来处理生产者生成的数据。在上面的例子中,我们只使用了一个消费者处理事件。
利用 RingBuffer 发布事件:
在此,生产者依次生产、发布事件。值得注意的是 Disruptor 与2阶段提交协议类似。它先获取一个新序列号(sequenceId),再通过(sequenceId)获取事件,然后制作事件,最后发布。下次获得sequenceId + 1。
示例代码可以在GitHub项目中找到。这是一个基于Maven的项目,所以它很容易导入和运行。
伪共享(False Sharing)
伪共享和缓存行
开始觉得不断的技术探索,仿佛只是对于前途的过多焦虑,让自己更多的沉浸于忙碌,从而更多的抬头看路。
看到很多人接下来的路,只是混混资历跟业务。然后慢慢的加薪拿股权,就算是人工智能其实也没有什么明朗的技术变现路线。
技术再好,也需要自我营销与宣传。止步眼前,心中颇多不甘。
译者序
前些天在并发编程网,看到了关于 Disruptor 的介绍。感觉此框架惊为天人,值得学习学习。在把并发编程网上面介绍逐一浏览之后发觉,缺少了对于 Disruptor 基础应用的介绍。于是就有了翻译海外基础介绍的想法。首先
要为以后难以在工作中用到 Disruptor 而感到沮丧。因为据介绍来看,它号称"能够在一个线程里每秒处理6百万订单" 。我所在的平台撑不起这个量,同时也限于学历跟从业背景难以去这类大公司供职。
其次
追逐性能,常常来说你给老板省了多少硬件,老板是看不到的。
建议一开始还是不要设计得性能太过优秀,不然老板看不到你的价值。
最后
Disruptor 是一个在并发编程中避免资源竞争的容器,用于协调生产者与消费者之间的关系,同时有着领域驱动模型 CQRS框架那种基于命令的影子。
应用这个框架编写代码将会较为繁复,模块与模块之前的通信全由一个又一个Event类来协调。
相对于大多数喜欢一个方法到底的开发同学来说会比较麻烦,毕竟需要定义更多类。
1. 概览
本篇文章目的在于介绍 LMAX Disruptor,探讨它是如何帮助我们实现软件低延迟、高并发特性。我们还将介绍 Disruptor 库的基本用法。
2. Disruptor 是什么?
Disruptor 是由 LMAX 编写的开源Java库。它是个并发编程框架,用于处理大量事务,而且低延迟(然而并不会像常规并发代码那样复杂)。
如此高效的性能优化,是通过更高效的利用底层硬件的设计实现。
2.1. 机械情怀
让我们从机械情怀的核心概念开始 - 这就是了解底层硬件如何以最屌的方式运行。举个栗子,
| 到CPU的延迟 | CPU时钟 | 耗时 |
|---|---|---|
| 主内存 | 很多(Multiple) | ~60-80 ns |
| L3 缓存 | ~40-45 周期 | ~15 ns |
| L2 缓存 | ~10 周期 | ~3 ns |
| L1 缓存 | ~3-4 周期 | ~1 ns |
| 寄存器 | 1 周期 | ~15 ns |
2.2. 为什么不用队列
生产者和消费者之间常常速率不一致,队列通常总是为"空"或"满"。因此队列头(head)、队列尾(tail)和队列大小(size)有着资源竞争(write contention)。生产和消费很少达到和谐的状态。通常采用锁来解决资源竞争(write contention)问题,但与此同时又会陷入内核级别的上下文切换。当这种情况发生时,处理器所缓存的数据可能丢失。(译者注:当线程A、B分别在CPU上不同的两个内核上运行时,线程A正要更新变量Y。不幸的是,这个变量也同时正要被线程B所更新。如果核心A获得了所有权,缓存子系统将会使核心B中对应的缓存行失效。当核心B获得了所有权然后执行更新操作,核心A就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。)
为了达到更好的线程可伸缩性,就必须确保不会有两个写线程操作同一个变量(多个读线程是没有问题的,如同处理器间调用高速链接获取缓存)。队列,它败在了独立写入原则(one-writer principle)。
如果两个不同的线程写入队列中两个不同的值,那么每个内核都会使另外一个线程的缓存行失效(数据在主内存与高速缓存之间的传输是做的固定大小的块传输,称之为缓存行。译者注:伪共享和缓存行)。尽管两个线程写入两个不同的变量,也同样会引起它们间的资源竞争。这叫做伪共享,因为每次访问队列头(head),队列尾(tail)也同样会被加载到缓存行,反之亦然。
2.3. Disruptor是如何工作的?
Disruptor 有一个基于数组的循环数据结构(环装缓冲区)。这个循环数据结构,它是个拥有下个可用元素引用的数组。预先分配了对象内存空间。生产者与消费者通过这个循环数据结构进行读写操作,并不会有锁或资源竞争。
在Disruptor 中,所有事件(events)以组播的方式被发布给所有消费者,以便下游队列通过并行的方式进行消费。因为消费者的并行消费,需要协调消费者间的依赖关系(依赖关系图)。
生产者和消费者中有个序列计数器,指示缓冲区中当前正在被它所处理的元素。所有生产者或消费者都只可以修改它自己的序列计数器,但同时可以读取其他的序列计数器。
3. 使用Disruptor 库
3.1. Maven 依赖
让我们把Disruptor 库的依赖关系添加到 pom.xml中。<dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>3.3.6</version> </dependency>
最新版本的依赖关系可以在这里找到。
3.2. 定义 Event 类
让我们来定义一个携带数据的 Event:public static class ValueEvent {
private int value;
public final static EventFactory EVENT_FACTORY
= () -> new ValueEvent();
// standard getters and setters
}这个 EventFactory 会让 Disruptor分配事件。
3.3. 消费者(Consumer)
消费者从环装缓冲区读取数据。让我们来定义个处理事件的消费者:public class SingleEventPrintConsumer {
...
public EventHandler<ValueEvent>[] getEventHandler() {
EventHandler<ValueEvent> eventHandler
= (event, sequence, endOfBatch)
-> print(event.getValue(), sequence);
return new EventHandler[] { eventHandler };
}
private void print(int id, long sequenceId) {
logger.info("Id is " + id
+ " sequence id that was used is " + sequenceId);
}
}在我们的示例中,消费者只是打印打印日志。
3.4. 构造 Disruptor
构造 Disruptor:ThreadFactory threadFactory = DaemonThreadFactory.INSTANCE; WaitStrategy waitStrategy = new BusySpinWaitStrategy(); Disruptor<ValueEvent> disruptor = new Disruptor<>( ValueEvent.EVENT_FACTORY, 16, threadFactory, ProducerType.SINGLE, waitStrategy);
在这个 Disruptor 的构造方法中,依次定义了以下参数:
Event Factory – 负责生成用于填充环装缓冲区的事件对象;
The size of Ring Buffer – 定义环装缓冲区的大小。它必须是2的幂,否则会在初始化时抛出异常。因为重点在于使用逻辑二进制运算符有着更好的性能;(例如:mod运算)
Thread Factory – 事件处理线程创建工厂;
Producer Type – 指定是否有单个或者多个生产者;
Waiting strategy – 定义如何处理无法跟上生产者步伐的慢消费者;
连接消费者处理程序:
disruptor.handleEventsWith(getEventHandler());
Disruptor可以提供多个消费者来处理生产者生成的数据。在上面的例子中,我们只使用了一个消费者处理事件。
3.5. 启动 Disruptor
RingBuffer<ValueEvent> ringBuffer = disruptor.start();
3.6 构造和发布事件(Event)
生产者将参数按顺序放置到环形缓冲区中。(译者注:3.4所述Event Factory已经作为参数,构造Disruptor对象)生产者必须获取到到下个可用元素,以避免覆盖尚未消耗的元素。利用 RingBuffer 发布事件:
for (int eventCount = 0; eventCount < 32; eventCount++) {
long sequenceId = ringBuffer.next();
ValueEvent valueEvent = ringBuffer.get(sequenceId);
valueEvent.setValue(eventCount);
ringBuffer.publish(sequenceId);
}在此,生产者依次生产、发布事件。值得注意的是 Disruptor 与2阶段提交协议类似。它先获取一个新序列号(sequenceId),再通过(sequenceId)获取事件,然后制作事件,最后发布。下次获得sequenceId + 1。
4. 总结
在本教程中,我们已经阐述了 Disruptor是什么,它是如何实现低延迟的并发处理。回顾了机械情怀的理念,以及如何利用它实现低延迟。最后展示了一个使用 Disruptor 库的例子。示例代码可以在GitHub项目中找到。这是一个基于Maven的项目,所以它很容易导入和运行。
引用:
DDD CQRS架构和传统架构的优缺点比较伪共享(False Sharing)
伪共享和缓存行
ps:
此次翻译拖了快两个月,纠结、消沉、迷离、回归。开始觉得不断的技术探索,仿佛只是对于前途的过多焦虑,让自己更多的沉浸于忙碌,从而更多的抬头看路。
看到很多人接下来的路,只是混混资历跟业务。然后慢慢的加薪拿股权,就算是人工智能其实也没有什么明朗的技术变现路线。
技术再好,也需要自我营销与宣传。止步眼前,心中颇多不甘。

相关文章推荐
- 【高并发框架】Disruptor之基础介绍
- 高性能并发框架 Disruptor 介绍 实现生产者消费者模型
- 并发框架LMAX Disruptor资料总汇
- Disruptor(无锁并发框架)-发布
- Disruptor(无锁并发框架)-发布
- Java Executor并发框架(一)整体介绍
- Java 并发框架 Disruptor 源码分析:RingBuffer
- 聊聊并发(八)——Fork/Join框架介绍
- Disruptor(无锁并发框架)-发布
- 无锁并发框架Disruptor
- Disruptor并发框架
- 聊聊并发(八)——Fork/Join框架介绍
- 聊聊并发(八)——Fork/Join框架介绍
- 架构师入门笔记七 并发框架Disruptor快速入门
- Java教程]并发框架Disruptor浅析
- Java Executor并发框架(一)整体介绍
- 并发框架Disruptor译文
- Java并发系列7-Disruptor无锁缓存框架
- 并发框架Disruptor译文
- Disruptor(无锁并发框架)-发布