分布式链路跟踪系统概设
2017-09-12 00:00
1526 查看
摘要: 目标:实现一套可以在生产环境上使用的全链路系统,方便问题查找
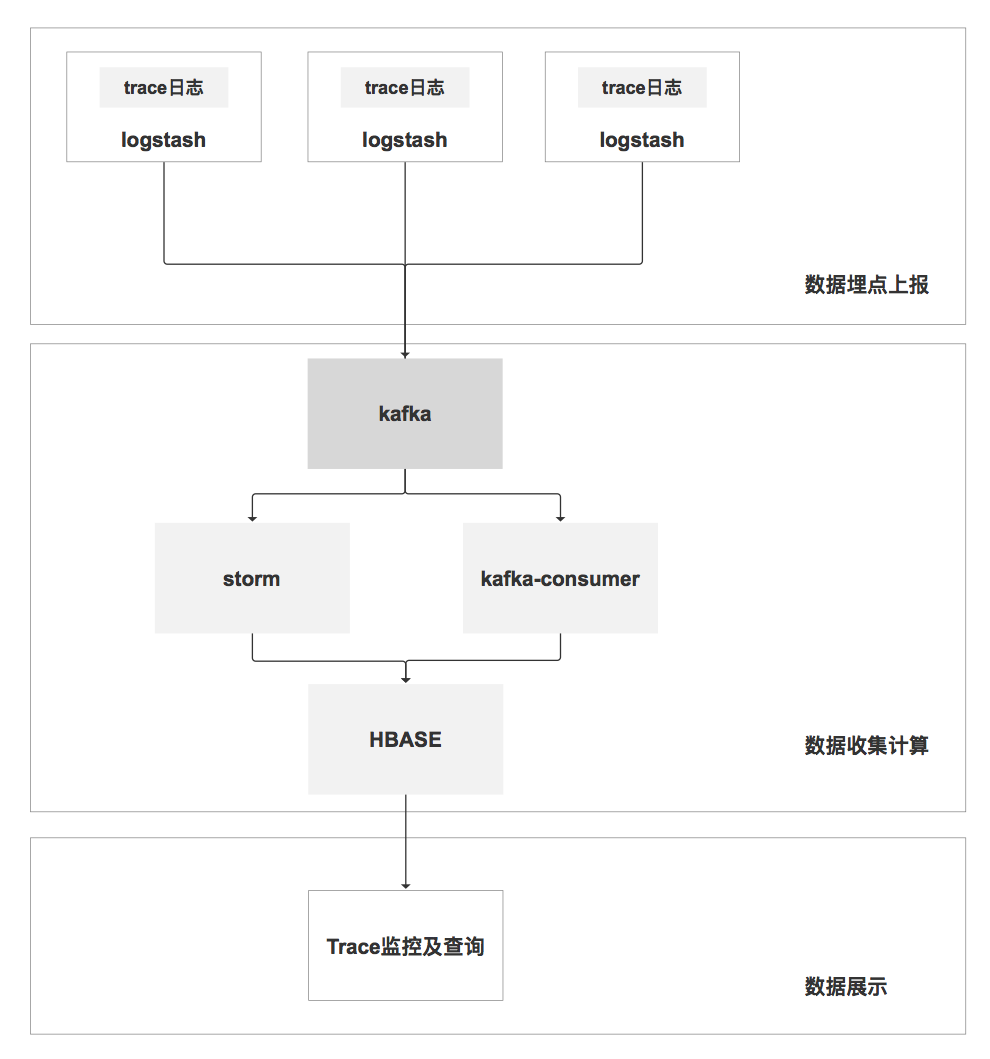
通过AGENT生成调用链trace日志。
通过logstash采集日志到kafka。
kafka负责提供数据给下游消费。
消费端解析trace信息,traceID作为rowkey,将信息插入hbase。
Trace-Id(每次请求的唯一标识,在请求的链路中传递)
Rpc-Id(调用链内部的唯一ID,还原调用顺序和调用间的嵌套关系,需要考虑的调用关系包括同步、并发、异步、一对多。)
Trace-Status(链路请求状态,整个链路传递,解决没被采样的异常跟踪丢失)
Trace-Sampled(调用链采样,因为QPS越高,需要生成的调用日志也就越高。因此,为了降低整体的输出数据量。默认全采集)
TraceId组成
毫秒时间(时间戳,13)
顺序数(4)
IPv4(8)
进程ID(4)
RpcId组成
默认顶级为0
所有RpcId,包含所有父级RpcId(0.1.1他的父级为0.1,0.1的父级为0)
系统整合
针对Http
利用Servlet的FIlter
接收请求时,从header中获取Trace-Id、Rpc-Id、Trace-Sampled,没有则创建Trace对象,并放入ThreadLocal中。
响应时,在header中设置Trace-Status,用来标识本次链路状态,解决没被采样的异常跟踪丢失
针对Dubbo
利用Dubbo的Filter机制
客户端发起请求时,创建新的Trace,将Trace-Id、Rpc-Id、Trace-Sampled放入invocation的attachments中,执行调用,响应后打印日志
服务端接收请求时,从invocation的attachments中获取Trace-Id、Rpc-Id、Trace-Sampled,执行调用,响应后打印日志
数据存储HBase
rowkey
traceId+endpoint(服务端、客户端)+rpcId
value
traceType(类型:http、dubbo、redis、MQ等)
traceName(具体访问的url、访问的接口方法)
appName(应用名称)
localIp(本机IP)
remoteIp(发起远程调用服务的IP)
status(trace的状态)
size(请求大小)
time(耗时)
message(信息:默认响应状态)
检索
使用RowPrefixFilter根据rowkey前缀匹配所有记录
架构示意图
架构组件选型
logstash->kafka->consumer->hbase通过AGENT生成调用链trace日志。
通过logstash采集日志到kafka。
kafka负责提供数据给下游消费。
消费端解析trace信息,traceID作为rowkey,将信息插入hbase。
实现思路
Trace头部定义Trace-Id(每次请求的唯一标识,在请求的链路中传递)
Rpc-Id(调用链内部的唯一ID,还原调用顺序和调用间的嵌套关系,需要考虑的调用关系包括同步、并发、异步、一对多。)
Trace-Status(链路请求状态,整个链路传递,解决没被采样的异常跟踪丢失)
Trace-Sampled(调用链采样,因为QPS越高,需要生成的调用日志也就越高。因此,为了降低整体的输出数据量。默认全采集)
TraceId组成
毫秒时间(时间戳,13)
顺序数(4)
IPv4(8)
进程ID(4)
RpcId组成
默认顶级为0
所有RpcId,包含所有父级RpcId(0.1.1他的父级为0.1,0.1的父级为0)
系统整合
针对Http
利用Servlet的FIlter
接收请求时,从header中获取Trace-Id、Rpc-Id、Trace-Sampled,没有则创建Trace对象,并放入ThreadLocal中。
响应时,在header中设置Trace-Status,用来标识本次链路状态,解决没被采样的异常跟踪丢失
针对Dubbo
利用Dubbo的Filter机制
客户端发起请求时,创建新的Trace,将Trace-Id、Rpc-Id、Trace-Sampled放入invocation的attachments中,执行调用,响应后打印日志
服务端接收请求时,从invocation的attachments中获取Trace-Id、Rpc-Id、Trace-Sampled,执行调用,响应后打印日志
数据存储HBase
rowkey
traceId+endpoint(服务端、客户端)+rpcId
value
traceType(类型:http、dubbo、redis、MQ等)
traceName(具体访问的url、访问的接口方法)
appName(应用名称)
localIp(本机IP)
remoteIp(发起远程调用服务的IP)
status(trace的状态)
size(请求大小)
time(耗时)
message(信息:默认响应状态)
检索
使用RowPrefixFilter根据rowkey前缀匹配所有记录

相关文章推荐
- 各大厂分布式链路跟踪系统架构对比
- 分布式链路跟踪系统
- Java分布式跟踪系统Zipkin(一):初识Zipkin
- Dapper,大规模分布式系统的跟踪系统
- Dapper,大规模分布式系统的跟踪系统
- Dapper--Google生产环境下的分布式跟踪系统
- 系统设计之----分布式跟踪系统
- 分布式跟踪系统(一):Zipkin的背景和设计
- 分布式会话跟踪系统架构设计与实践
- Twitter zipkin 分布式跟踪系统的设计与实现
- Google Dapper-大规模分布式系统的基础跟踪设施
- Java分布式跟踪系统Zipkin(二):Brave源码分析-Tracer和Span
- 微服务之分布式跟踪系统(springboot+zipkin)
- Twitter zipkin 分布式跟踪系统的设计与实现
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
- Java分布式跟踪系统Zipkin(三):Brave源码分析-Tracing
- Google Dapper,大规模分布式系统的跟踪系统
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
- 分布式跟踪系统(一):Zipkin的背景和设计
- 日志系统实战(三)-分布式跟踪的Net实现