使用 Python 读写 csv 文件
2017-09-10 23:13
615 查看
非关系型数据库中,以文档型的数据库 MongoDB 最为著名。还有一个很好的全文检索引擎 Elasticsearch,基本上也可以当做一个文档型的数据库来使用。
创建 csv 文件
读取 csv 文件
将读取的内容转换为字典

说明:1、这里“a”表示,打开文件的方式为“追加”;
2、打开这个 csv 文件可以看到,字符串没有用 “” 号括起来;
想为字符串增加双引号,可以这样写:
将
替换成
csv 文件可以使用的存储模式,请参考下面的这张表:
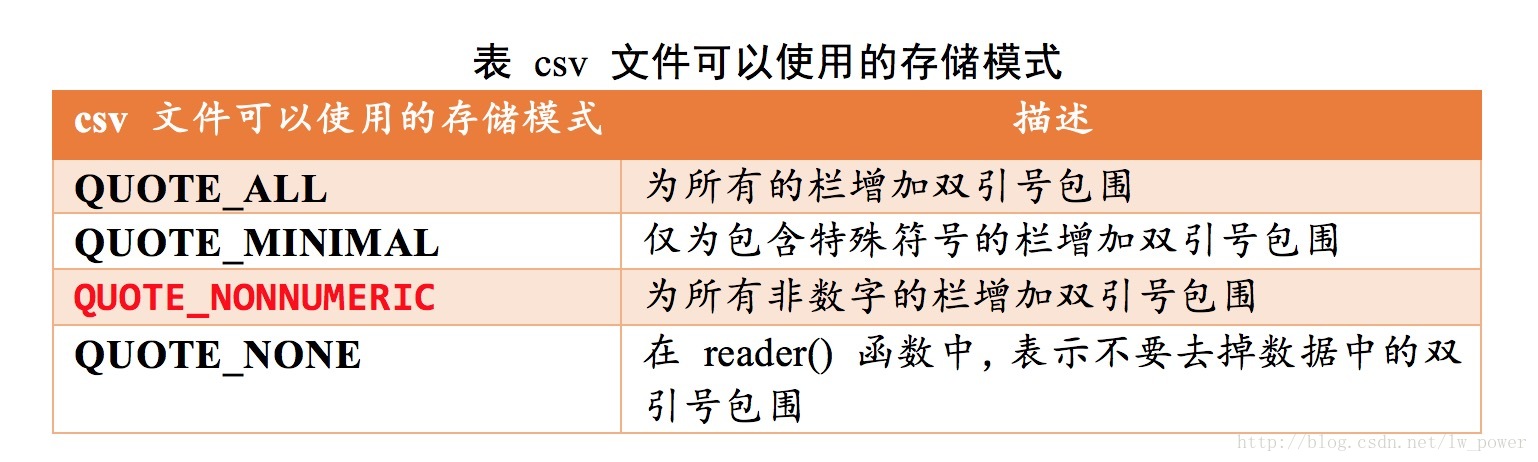
表 csv 文件可以使用的存储模式
打印结果:
观察可以发现:
1、原始的行数据按照逗号分隔被切分成了列表
2、Name 列中的双引号也被去掉了
在 Python 编程中,我们从来都不提倡“重复造轮子”。
假设要读取的文件内容是这样的:
我们就需要处理方言,默认情况下,分割符号是“,”,我们想把分隔符号改成“|”,这件事情就叫做 csv 的方言。
使用的方法,我们可以在创建 csv 文件的时候,“注册”一下,这个操作相当于“设置”。
方言指定了解析或写一个数据文件时使用的所有记号。
完整代码:
当然,在我们 insert 到 csv 文件的时候,也可以这么做:
总结:不论是在写 csv 文件还是在读 csv 文件的时候,一定要做两件事情:
(1)
(2)
带方言的 csv 文件读法:
读取的结果是,第一行的永远作为了 key。
或者我们可以这样说,
注意:如果在写入文件的时候,两行之间会空出一行来,则需要修改如下:
创建 csv 文件
读取 csv 文件
将读取的内容转换为字典
创建 csv 文件:
import csv
with open("./csv_tutotial.csv", "a") as fw:
writer = csv.writer(fw)
writer.writerow(["c1", "c2", "c3"])
for x in range(10):
writer.writerow([x, chr(ord('a') + x), 'aaa'])说明:1、这里“a”表示,打开文件的方式为“追加”;
2、打开这个 csv 文件可以看到,字符串没有用 “” 号括起来;
想为字符串增加双引号,可以这样写:
将
writer = csv.writer(fw)
替换成
writer = csv.writer(fw, quoting=csv.QUOTE_NONNUMERIC)
csv 文件可以使用的存储模式,请参考下面的这张表:
表 csv 文件可以使用的存储模式
| csv 文件可以使用的存储模式 | 描述 |
|---|---|
| QUOTE_ALL | 为所有的栏增加双引号包围 |
| QUOTE_MINIMAL | 仅为包含特殊符号的栏增加双引号包围 |
| QUOTE_NONNUMERIC | 为所有非数字的栏增加双引号包围 |
| QUOTE_NONE | 在 reader() 函数中,表示不要去掉数据中的双引号包围 |
读取 csv 文件
读取 csv 文件:from __future__ import print_function
import csv
with open("./csv_tutotial.csv", "r") as fr:
# 这个方法返回的是迭代类型
rows = csv.reader(fr)
for row in rows:
print(row)打印结果:
['c1', 'c2', 'c3'] ['0', 'a', 'aaa'] ['1', 'b', 'aaa'] ['2', 'c', 'aaa'] ['3', 'd', 'aaa'] ['4', 'e', 'aaa'] ['5', 'f', 'aaa'] ['6', 'g', 'aaa'] ['7', 'h', 'aaa'] ['8', 'i', 'aaa'] ['9', 'j', 'aaa']
观察可以发现:
1、原始的行数据按照逗号分隔被切分成了列表
2、Name 列中的双引号也被去掉了
在 Python 编程中,我们从来都不提倡“重复造轮子”。
假设要读取的文件内容是这样的:
c1|c2|c3 0|a|aaa 1|b|aaa 2|c|aaa 3|d|aaa 4|e|aaa 5|f|aaa 6|g|aaa 7|h|aaa 8|i|aaa 9|j|aaa
我们就需要处理方言,默认情况下,分割符号是“,”,我们想把分隔符号改成“|”,这件事情就叫做 csv 的方言。
使用的方法,我们可以在创建 csv 文件的时候,“注册”一下,这个操作相当于“设置”。
方言指定了解析或写一个数据文件时使用的所有记号。
csv.register_dialect("pipes", delimiter='|')完整代码:
import csv
csv.register_dialect("pipes", delimiter="|")
with open("./csv_tutotial.csv", "r") as fr:
rows = csv.reader(fr, dialect="pipes")
for row in rows:
print(row)当然,在我们 insert 到 csv 文件的时候,也可以这么做:
import csv
csv.register_dialect("pipes", delimiter="|")
with open("./csv_tutotial.csv", "w") as fr:
writer = csv.writer(fr, dialect="pipes")
writer.writerow(['id', 'name', 'age'])
for x in range(10):
writer.writerow([x, chr(ord('a') + x), int(x) + 20])总结:不论是在写 csv 文件还是在读 csv 文件的时候,一定要做两件事情:
(1)
csv.register_dialect("pipes", delimiter="|")(2)
writer = csv.writer(fr, dialect="pipes")
将读取的内容转换为字典
将读取的内容转换为字典,使用的 csv 的DictReader()方法。
import csv
with open("./csv_tutotial.csv", 'r') as fr:
rows = csv.DictReader(fr)
for row in rows:
print(row)带方言的 csv 文件读法:
import csv
csv.register_dialect("pipes", delimiter="|")
with open("./csv_tutotial.csv", "r") as fr:
rows = csv.DictReader(fr, dialect="pipes")
for row in rows:
print(row['id'], row.get('name'), row['age'])读取的结果是,第一行的永远作为了 key。
或者我们可以这样说,
csv.DictReader()方法读出来的数据,默认以第 1 行作为标记。
注意:如果在写入文件的时候,两行之间会空出一行来,则需要修改如下:
with open("./csv_tutotial.csv", "w",newline='') as fr:

相关文章推荐
- 使用python读写CSV文件的三种方法
- python3使用csv模块读写csv文件
- python3使用csv模块读写csv文件
- python使用csv模块读写csv文件
- python读写csv文件
- Python CSV文件处理/读写
- Python_使用csv模块解析csv文件(处理Excel表格)
- Python_使用csv模块解析csv文件
- Python使用cx_Oracle模块将oracle中数据导出到csv文件的方法
- Python读写csv文件
- php使用fputcsv()函数csv文件读写数据的方法
- Python3使用csv模块csv.writer().writerow()保存csv文件,产生空行的问题
- 使用Python进行二进制文件读写
- Python中使用不同编码读写txt文件详解
- Java中使用opencsv读写csv文件示例
- Python读写csv文件
- 使用Python读写XML文件
- 使用Python进行二进制文件读写(转)
- Python读写csv文件
- [Python]使用csv dialect 读写数据