基于Tensorflow+Python实现降噪自动编码器(DAE)
2017-09-10 19:09
756 查看
It is our choices that show what we truly are, far more than our abilities.
决定我们一生的,不是我们的能力,而是我们的选择。
运行结果截图如下:
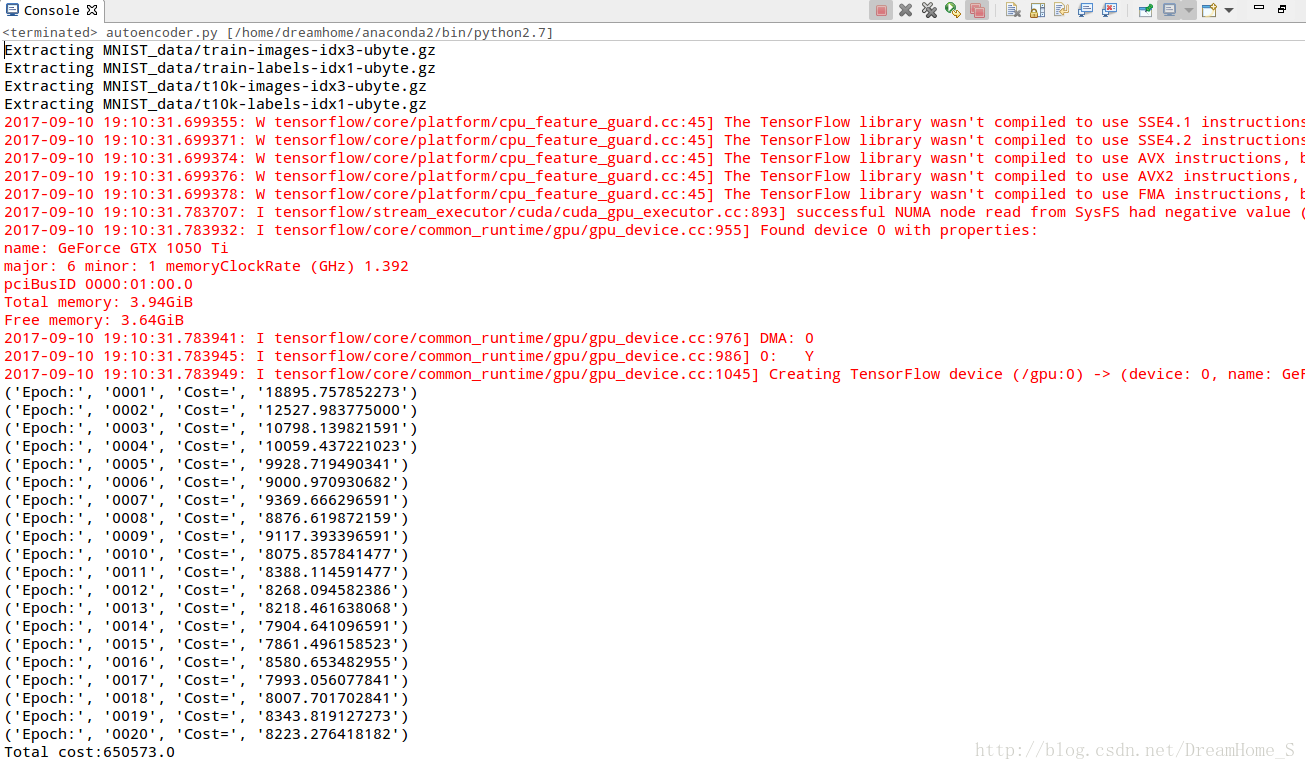
以上是本人对于此内容的理解,敬请广大读者随时不吝批评指正,感谢。
决定我们一生的,不是我们的能力,而是我们的选择。
基于Tensorflow+Python实现降噪自动编码器(DAE)
本代码原理参考书籍TensorFlow 实战# -*- coding: UTF-8 -*-
'''
Created on 2017年8月7日
@summary:利用tensorflow实现降噪自动编码器
@author: dreamhome
'''
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def xavier_init(n_input,n_output,constant=1):
"""
Xavier初始化器 让权重被初始化调整合理的分布 mean=0 std=2/(n_input+n_output)
:param n_input:输入节点数量
:param n_output:输出节点数量
"""
low=-constant * np.sqrt(6.0/(n_input+n_output))
high=constant * np.sqrt(6.0/(n_input+n_output))
return tf.random_uniform((n_input,n_output), minval=low, maxval=high,
dtype=tf.float32)
class AdditiveGaussianNoiseAutoencoder(object):
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(),scale=0.1):
"""
初始化函数
:param n_input:输入变量数
:param n_hidden:隐含层节点数
:param transfer_function:隐含层激活函数
:param optimizer:优化器默认为 Adam
:param scale:高斯噪声系数
"""
self.n_input=n_input
self.n_hidden=n_hidden
self.transfer=transfer_function
self.scale=tf.placeholder(dtype=tf.float32)
self.training_scale=scale
network_weights=self._initialize_weights()
self.weights=network_weights
self.x=tf.placeholder(tf.float32,[None,self.n_input])
#利用transform对结果进行激活函数处理
self.hidden=self.transfer(tf.add(tf.matmul(
self.x+scale*tf.random_normal((n_input,)),self.weights['w1'])
,self.weights['b1']))
#reconstruction层对经过隐含层的数据进行复原
self.reconstruction=tf.add(tf.matmul(
self.hidden,self.weights[
4000
'w2']),
self.weights['b2'])
#定义自编码器的损失函数 平方误差
self.cost=0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x),2.0))
self.optimizer=optimizer.minimize(self.cost)
init=tf.global_variables_initializer()
self.sess=tf.Session()
self.sess.run(init)
def _initialize_weights(self):
"""
参数初始化函数
"""
#利用字典存储参数
all_weights=dict()
all_weights['w1']=tf.Variable(xavier_init(self.n_input,self.n_hidden))
all_weights['b1']=tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32))
all_weights['w2']=tf.Variable(tf.zeros([self.n_hidden,self.n_input], dtype=tf.float32))
all_weights['b2']=tf.Variable(tf.zeros([self.n_input], dtype=tf.float32))
return all_weights
def partial_fit(self,X):
"""
函数利用一个batch的数据进行训练并且返回当前的损失cost
:param X: 输入数据X
"""
cost,opt=self.sess.run((self.cost,self.optimizer),
feed_dict={self.x:X,
self.scale:self.training_scale})
return cost
def calc_total_cost(self,X):
"""
函数在测试集上对模型进行评测时用到
"""
return self.sess.run(self.cost,
feed_dict={self.x:X,
self.scale:self.training_scale})
def transform(self,X):
"""
返回自编码器隐含层的结果,提供一个接口来获取抽象后的特征
"""
return self.sess.run(self.hidden,feed_dict={self.x:X,
self.scale:self.training_scale})
def generate(self,hidden=None):
"""
将高阶特征复原为原始数据
"""
if hidden is None:
hidden=np.random.normal(size=self.weights["b1"])
return self.sess.run(self.reconstruction,
feed_dict={self.hidden:hidden})
def reconstruct(self,X):
"""
函数整体运行一遍复原过程 包括高阶特征提取和通过高阶特征复原数据
"""
return self.sess.run(self.reconstruct,feed_dict={self.x:X,
self.scale:self.training_scale})
def getWeights(self):
"""
获取隐含层的权重w1
"""
return self.sess.run(self.weights['w1'])
def getBiases(self):
"""
获取隐含层偏置系数b1
"""
return self.sess.run(self.weights['b1'])
def standard_scale(X_train,X_test):
"""
对训练集和测试集的数据进行标准化处理
"""
preprocessor =prep.StandardScaler().fit(X_train)
X_train=preprocessor.transform(X_train)
X_test=preprocessor.transform(X_test)
return X_train,X_test
def get_random_block_from_data(data,batch_size):
"""
函数随机从数据集中获取block
"""
start_index=np.random.randint(0,len(data)-batch_size)
return data[start_index:(start_index+batch_size)]
if __name__ == '__main__':
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
X_train,X_test=standard_scale(mnist.train.images, mnist.test.images)
n_samples=int(mnist.train.num_examples)
training_epochs=1
batch_size=128
display_step=1
autoencoder=AdditiveGaussianNoiseAutoencoder(n_input=784,
n_hidden=200,
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
scale=0.01)
for epoch in range(training_epochs):
avg_cost=0.0
total_batch=int(n_samples/batch_size)
for i in range(total_batch):
batch_xs=get_random_block_from_data(X_train, batch_size)
cost=autoencoder.partial_fit(batch_xs)
avg_cost+=cost/n_samples*batch_size
if epoch%display_step==0:
print("Epoch:",'%04d'%(epoch+1),
"Cost=","{:.9f}".format(avg_cost))
print("Total cost:"+str(autoencoder.calc_total_cost(X_test)))运行结果截图如下:
以上是本人对于此内容的理解,敬请广大读者随时不吝批评指正,感谢。

相关文章推荐
- tensorflow tutorials(十):用tensorflow实现降噪自编码器(Denoising Auto-Encoder)
- 基于python脚本,实现Unity全平台的自动打包
- python tensorflow 使用minist数据集实现手写数字识别
- 基于theano的降噪自动编码器(Denoising Autoencoders--DA)
- Tensorflow+gensim实现文章自动审核功能
- 1TensorFlow实现自编码器-1.3 TensorFlow实现降噪自动编码器--计算图美化
- 基于Python实现自动慢查询分析,邮件自动发送
- 通过Python+TensorFlow实现人脸识别(一)
- Tensorflow学习笔记(二)实现降噪自动编码器--设计计算图
- Python之——实现自动抢火车票(基于Python3.6+splinter)
- tensorflow tutorials(五):用tensorflow实现自编码器(Auto-Encoder)
- Python+Socket实现基于TCP协议的客户与服务端中文自动回复聊天功能示例
- 基于esky实现python应用的自动升级
- 神经网络之Inception模型的实现(Python+TensorFlow)
- 基于python实现jenkins自动发布代码平台
- 神经网络之VGGNet模型的实现(Python+TensorFlow)
- 1TensorFlow实现自编码器-1.2TensorFlow实现降噪自动编码器设计计算图
- 基于Python3.6+splinter实现自动抢火车票
- 神经网络之ResNet模型的实现(Python+TensorFlow)