初识ZooKeeper
2017-09-07 17:39
429 查看

Welcome to Apache ZooKeeper™
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
What is ZooKeeper?
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of servicesare used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable(不可避免的). Because of the difficulty of implementing these kinds of services,
applications initially usually skimp(克扣) on them ,which make them brittle(易碎的)in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
ZooKeeper: Because Coordinating Distributed Systems is a Zoo
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and groupservices - in a simple interface so you don't have to write them from scratch(抓,扒). You can use it off-the-shelf(现成的) to implement consensus(合意), group management, leader election,
and presence protocols. And you can build on it for your own, specific needs.
ZooKeeper: A Distributed Coordination Service for Distributed Applications
ZooKeeper is a distributed, open-source coordination(协同) service for distributed applications. It exposes a simple set of primitives(原生的) that distributed applications can build upon to implementhigher level services for synchronization, configuration maintenance, and groups and naming. It is designed to be easy to program to, and uses a data model styled after the familiar directory tree structure of file systems. It runs in Java and has bindings
for both Java and C.
Coordination services are notoriously(众所周知的) hard to get right. They are especially prone(倾斜) to errors such as race conditions and deadlock. The motivation(诱因) behind ZooKeeper is to
relieve(缓解) distributed applications the responsibility of implementing coordination services from scratch.
Design Goals
ZooKeeper is simple. ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchal(层级) namespace which is organized similarly to a standard file system. The name space
consists(组成) of data registers - called znodes, in ZooKeeper parlance(说法,用法) - and these are similar to files and directories. Unlike a typical file system, which is designed for storage, ZooKeeper data is kept in-memory, which means ZooKeeper can acheive
high throughput(吞吐量) and low latency(延迟) numbers.
The ZooKeeper implementation puts a premium(附加
f195
|保险) on high performance, highly available, strictly ordered
access.
The performance aspects of ZooKeeper means it can be used in large, distributed systems.
The reliability aspects keep it from being a single point of failure.
The strict ordering means that sophisticated synchronization primitives can be implemented at the client.
ZooKeeper is replicated.
Like the distributed processes it
coordinates, ZooKeeper itself is intended to be replicated over a sets of hosts called an ensemble(全体|总效果).
| ZooKeeper Service |
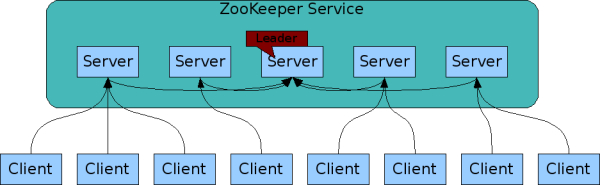 |
As long as a majority of the servers are available, the ZooKeeper service will be available.
Clients
connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server.
ZooKeeper
is ordered.
ZooKeeper
stamps(标记) each update with a number that reflects the order of all ZooKeeper transactions. Subsequent(随后) operations can use the order to implement higher-level abstractions, such as synchronization primitives.
ZooKeeper
is fast.
It is especially fast in "read-dominant(占优势的)" workloads(工作量|工作负荷). ZooKeeper applications run on thousands of machines, and it performs best where reads are more common than writes,
at ratios of around 10:1.
Data model and the hierarchical(分层的) namespace
The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper's name space isidentified by a path.
| ZooKeeper's Hierarchical Namespace |
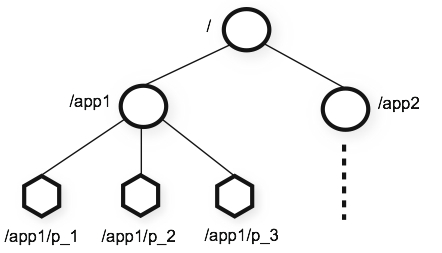 |
Nodes and ephemeral(临时|短暂) nodes
Unlike is standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory. (ZooKeeper was designed to store coordination data: status information,configuration, location information, etc., so the data stored at each node is usually small, in the byte to kilobyte range.) We use the term znode to make it clear that we are talking about ZooKeeper data nodes.
Znodes maintain a stat structure that includes version numbers for data changes, ACL changes, and timestamps, to allow cache validations and coordinated updates. Each time a znode's data
changes, the version number increases. For instance, whenever a client retrieves(检索) data it also receives the version of the data.
The data stored at each znode in a namespace is read and written atomically. Reads get all the data bytes associated with a znode and a write replaces all the data. Each node has an Access
Control List (ACL) that restricts who can do what.
ZooKeeper also has the notion(概念) of ephemeral nodes. These znodes exists as long as the session that created the znode is active. When the session ends the znode is deleted. Ephemeral
nodes are useful when you want to implement...
Conditional updates(条件更新) and watches (资源并发修改问题)
ZooKeeper supports the concept of watches.Clients can set a watch on a znodes. A watch will be triggered and removed when the znode changes. When a watch is triggered the client receives a packet saying that the znode has changed. And if the connection between the client and one of the Zoo Keeper
servers is broken, the client will receive a local notification.
Guarantees
ZooKeeper is very fast and very simple. Since its goal, though, is to be a basis for the construction of more complicated services, such as synchronization, it provides a set of guarantees. These are:Sequential Consistency(有序 连贯) - Updates from a client will be applied in the order that they were sent.
Atomicity - Updates either succeed or fail. No partial results.
Single System Image - A client will see the same view of the service regardless of the server that it connects to.
Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.
Simple API
One of the design goals of ZooKeeper is provide a very simple programming interface. As a result, it supports only these operations:create
creates a node at a location in the tree
delete
deletes a node
exists
tests if a node exists at a location
get data
reads the data from a node
set data
writes data to a node
get children
retrieves a list of children of a node
sync
waits for data to be propagated
For a more in-depth discussion on these, and how they can be used to implement higher level operations, please refer to 。。。
Implementation
ZooKeeper Components shows the high-level components of the ZooKeeper service. With the exception of the requestprocessor, each of the servers that make up the ZooKeeper service replicates its own copy of each of components.
| ZooKeeper Components |
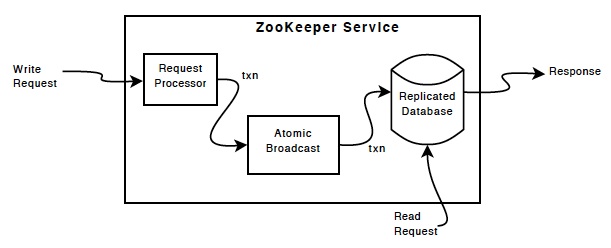 |
to the in-memory database.
Every ZooKeeper server services clients. Clients connect to exactly(确切的) one server to submit requests. Read requests are serviced from the local replica of each server database. Requests
that change the state of the service, write requests, are processed by an agreement protocol.
As part of the agreement protocol all write requests from clients are forwarded to a single server, called the leader.
The rest of the ZooKeeper servers, called followers, receive message proposals from the leader and
agree upon message delivery. The messaging layer(消息层) takes care of replacing leaders on failures and syncing followers with leaders.
(写操作只写leader,然后进行消息分发,失败则回滚leader,成功则同步followers)
ZooKeeper uses a custom atomic(原子的) messaging protocol. Since the messaging layer is atomic, ZooKeeper can guarantee that the local replicas never diverge(分歧). When the leader receives
a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures(夺取|俘获) this new state.

相关文章推荐
- 初识zookeeper(一)之zookeeper的安装及配置
- Zookeeper学习笔记-1-初识
- 初识zookeeper(二)之与Dubbo-admin关联
- 初识ZooKeeper
- zookeeper初识之原理
- Zookeeper笔记(一)初识Zookeeper
- ZooKeeper 初识
- 【ZooKeeper 基础篇】初识
- 初识Lily, Lily=Hadoop+Zookeeper+HBase+Solr
- 初识zookeeper
- 初识zookeeper
- 初识zookeeper和Dubbo
- 初识ZooKeeper与集群搭建实例
- 初识ZooKeeper
- ZooKeeper_2_初识ZooKeeper
- 初识ZooKeeper
- 初识zookeeper(1)之zookeeper的安装及配置
- ZooKeeper学习笔记:初识zookeeper
- 初识zookeeper之安装搭建(windos10环境)
- zookeeper 初识