使用Windows下的intellij IDEA 运行MapReduce程序远程调用Hadoop的hdfs(非Maven方法)
2017-09-07 00:00
816 查看
摘要: 模拟使用本地电脑登录机房hadoop环境
我使用的环境分别是:
本地:win10_64位+IDEA17.2.3
远程:虚拟机 UbuntuKylin16.10_64位+hadoop2.7.3
本地的intellij已经安装好,Jdk等配置好。
比如我用的是hadoop2.7.3版本,所以:
然后,重启IDEA才能生效!!!
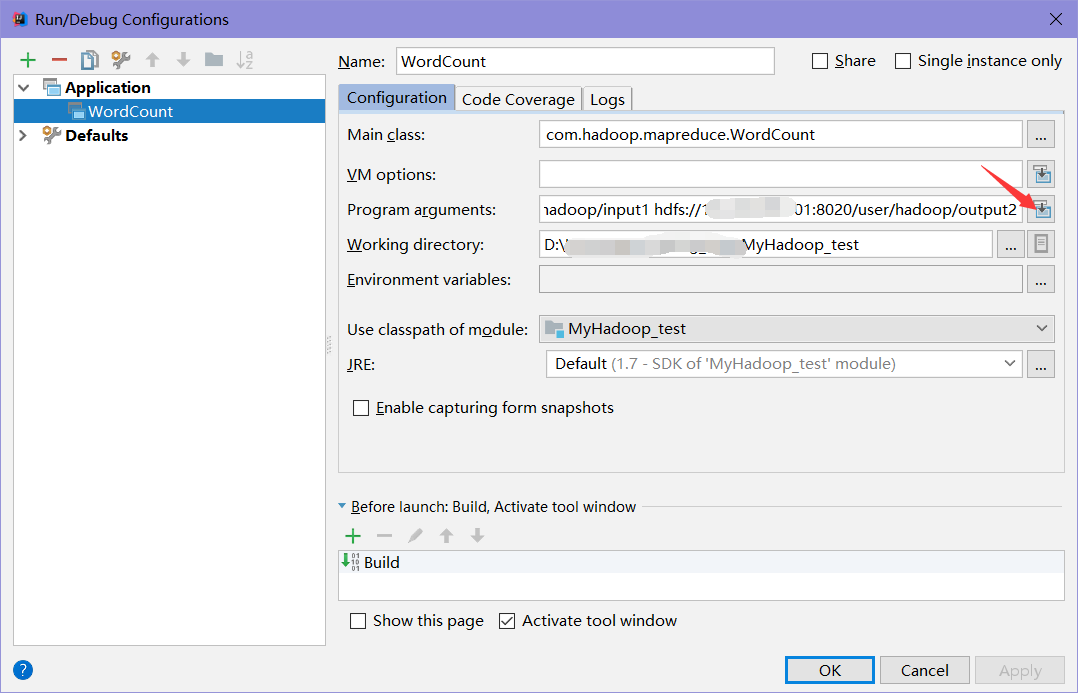
这里以WordCount为例,需要写两个参数,输入文件和输入文件
注意:输出目录必须是不存在的目录,否则hadoop报错!!!
像这样:
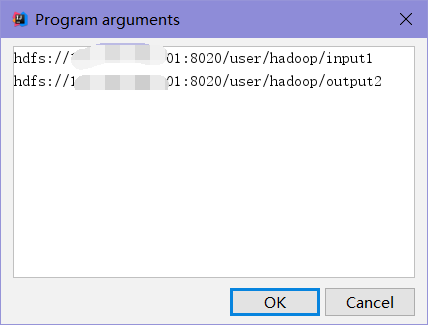
这里的输入输出写远程的hdfs,按格式。
1.确保你的hdfs监听的方式,在hadoop-x.x.x/etc/hadoop/core-site.xml中,fs.defaultFS的值hdfs://ip:port中的ip是不是127.0.0.1即localhost,如果是,则改为本地ip(或者添加/etc/hosts文件),port没有特别要求。。
2.为了保证没有权限问题在hdfs-site.xml文件中添加:
其实这样是不安全的,在企业中是不允许的,这里如果不考虑太多的话,可以这么改。
然后运行IDEA的代码就可以了。
IDEA的输出结果展示:
以上。
我使用的环境分别是:
本地:win10_64位+IDEA17.2.3
远程:虚拟机 UbuntuKylin16.10_64位+hadoop2.7.3
前提工作:
hadoop环境已经搭好,HDFS服务已经启动。本地的intellij已经安装好,Jdk等配置好。
第一步:intellij IDEA的项目配置
1.建Java项目,空白项目即可。
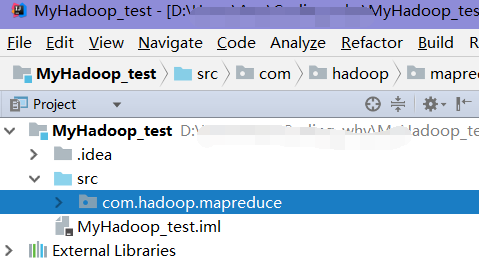
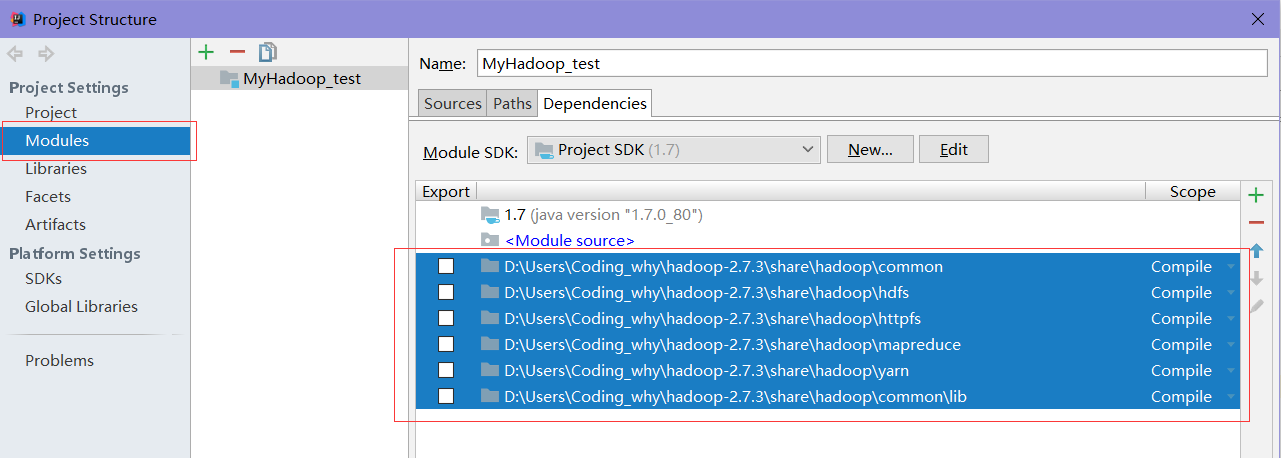
2.添加hadoop依赖包。
用启动hdfs的hadoop文件中的hadoop-x.x.x/share/hadoop/下的所有文件复制出来,这所有都是要添加的依赖包,特别要再把hadoop-x.x.x/share/hadoop/common/lib添加到依赖包。3.添加Windows下的必要文件
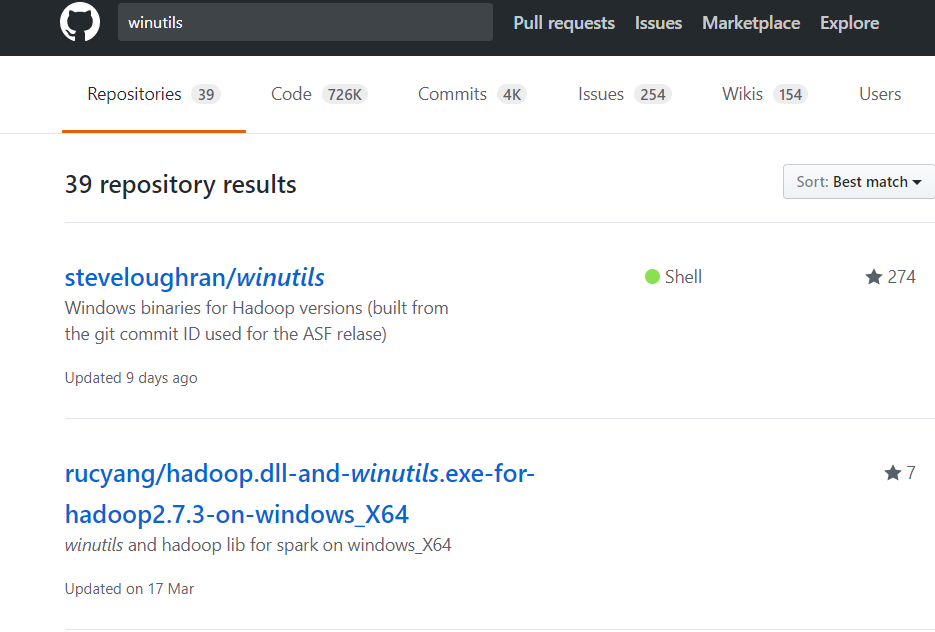
Windows下缺少winutils.exe和hadoop.dll文件,请在GitHub上搜索“winutils”,下载对应版本的文件。比如我用的是hadoop2.7.3版本,所以:
4.添加HADOOP_HOME并添加到path
将第3步下载的所有的文件放到HADOOP_HOME/bin下即可,并在path下追加%HADOOP_HOME%\bin然后,重启IDEA才能生效!!!
5.运行配置
这里以WordCount为例,需要写两个参数,输入文件和输入文件
注意:输出目录必须是不存在的目录,否则hadoop报错!!!
像这样:
这里的输入输出写远程的hdfs,按格式。
第二步:代码编写
很简单,这里拿hadoop源文件里给的wordcount例子来演示package com.hadoop.mapreduce;
/**
* Created by Aqc on 2017/9/6.
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
private static void deleteDir(Configuration conf, String dirPath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path targetPath = new Path(dirPath);
if (fs.exists(targetPath)) {
boolean delResult = fs.delete(targetPath, true);
if (delResult) {
System.out.println(targetPath + " has been deleted sucessfullly.");
} else {
System.out.println(targetPath + " deletion failed.");
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
/* conf.set("fs.defaultFS","hdfs://192.168.56.101:8020");
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//先删除output目录
deleteDir(conf, otherArgs[otherArgs.length - 1]);*/
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}第三步:连接远程hdfs,运行程序
首要:1.确保你的hdfs监听的方式,在hadoop-x.x.x/etc/hadoop/core-site.xml中,fs.defaultFS的值hdfs://ip:port中的ip是不是127.0.0.1即localhost,如果是,则改为本地ip(或者添加/etc/hosts文件),port没有特别要求。。
2.为了保证没有权限问题在hdfs-site.xml文件中添加:
<property> <name>dfs.permissions</name> <value>false</value> </property>
其实这样是不安全的,在企业中是不允许的,这里如果不考虑太多的话,可以这么改。
然后运行IDEA的代码就可以了。
IDEA的输出结果展示:
"D:\Program Files\Java\jdk1.7.0_80\bin\java" "-javaagent:D:\Program Files\IntelliJ IDEA 2017.2.3\lib\idea_rt.jar=53165:D:\Program Files\IntelliJ IDEA 2017.2.3\bin" -Dfile.encoding=UTF-8 -classpath "D:\Program Files\Java\jdk1.7.0_80\jre\lib\charsets.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\deploy.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\access-bridge-64.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\dnsns.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\jaccess.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\localedata.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\sunec.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\sunjce_provider.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\sunmscapi.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\zipfs.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\javaws.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\jce.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\jfr.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\jfxrt.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\jsse.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\management-agent.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\plugin.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\resources.jar;D:\Program Files\Java\jdk1.7.0_80\jre\lib\rt.jar;D:\Users\Aqc\Coding_why\MyHadoop_test\out\production\MyHadoop_test;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\hadoop-nfs-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\hadoop-common-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\hadoop-common-2.7.3-tests.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\hdfs\hadoop-hdfs-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\hdfs\hadoop-hdfs-nfs-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\hdfs\hadoop-hdfs-2.7.3-tests.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\httpfs;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-examples-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-hs-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-app-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-core-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-common-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-shuffle-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-jobclient-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-hs-plugins-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\mapreduce\hadoop-mapreduce-client-jobclient-2.7.3-tests.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-api-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-client-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-common-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-registry-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-tests-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-common-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-web-proxy-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-nodemanager-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-resourcemanager-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-sharedcachemanager-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-applications-distributedshell-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-server-applicationhistoryservice-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\yarn\hadoop-yarn-applications-unmanaged-am-launcher-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\xz-1.0.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\asm-3.2.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\avro-1.7.4.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\gson-2.2.4.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\junit-4.11.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jsch-0.1.42.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jsp-api-2.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\xmlenc-0.52.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\guava-11.0.2.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jets3t-0.9.0.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jettison-1.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jetty-6.1.26.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jsr305-3.0.0.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\log4j-1.2.17.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\paranamer-2.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\activation-1.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-io-2.4.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\httpcore-4.2.5.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jaxb-api-2.2.2.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\stax-api-1.0-2.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-cli-1.2.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-net-3.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jersey-core-1.9.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jersey-json-1.9.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\servlet-api-2.5.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\zookeeper-3.4.6.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-lang-2.6.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\httpclient-4.2.5.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\slf4j-api-1.7.10.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-codec-1.4.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\hadoop-auth-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\hamcrest-core-1.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jackson-xc-1.9.13.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jaxb-impl-2.2.3-1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jersey-server-1.9.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jetty-util-6.1.26.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\mockito-all-1.8.5.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\netty-3.6.2.Final.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\api-util-1.0.0-M20.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-math3-3.1.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\java-xmlbuilder-0.4.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\protobuf-java-2.5.0.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\snappy-java-1.0.4.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-digester-1.8.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\curator-client-2.7.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jackson-jaxrs-1.9.13.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\slf4j-log4j12-1.7.10.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-logging-1.1.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\curator-recipes-2.7.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\api-asn1-api-1.0.0-M20.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-compress-1.4.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-httpclient-3.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\apacheds-i18n-2.0.0-M15.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-beanutils-1.7.0.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\curator-framework-2.7.1.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jackson-core-asl-1.9.13.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\hadoop-annotations-2.7.3.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-collections-3.2.2.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-configuration-1.6.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\jackson-mapper-asl-1.9.13.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\commons-beanutils-core-1.8.0.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\htrace-core-3.1.0-incubating.jar;D:\Users\Coding_why\hadoop-2.7.3\share\hadoop\common\lib\apacheds-kerberos-codec-2.0.0-M15.jar" com.hadoop.mapreduce.WordCount hdfs://192.168.56.101:8020/user/hadoop/input1 hdfs://192.168.56.101:8020/user/hadoop/output2 2017-09-07 21:08:29,673 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1173)) - session.id is deprecated. Instead, use dfs.metrics.session-id 2017-09-07 21:08:29,676 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId= 2017-09-07 21:08:29,902 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(64)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2017-09-07 21:08:29,942 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(171)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 2017-09-07 21:08:30,003 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(283)) - Total input paths to process : 2 2017-09-07 21:08:30,049 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(198)) - number of splits:2 2017-09-07 21:08:30,181 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(287)) - Submitting tokens for job: job_local2028239795_0001 2017-09-07 21:08:30,353 INFO [main] mapreduce.Job (Job.java:submit(1294)) - The url to track the job: http://localhost:8080/ 2017-09-07 21:08:30,354 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1339)) - Running job: job_local2028239795_0001 2017-09-07 21:08:30,355 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(471)) - OutputCommitter set in config null 2017-09-07 21:08:30,360 INFO [Thread-5] output.FileOutputCommitter (FileOutputCommitter.java:<init>(108)) - File Output Committer Algorithm version is 1 2017-09-07 21:08:30,363 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(489)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 2017-09-07 21:08:30,431 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for map tasks 2017-09-07 21:08:30,432 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(224)) - Starting task: attempt_local2028239795_0001_m_000000_0 2017-09-07 21:08:30,452 INFO [LocalJobRunner Map Task Executor #0] output.FileOutputCommitter (FileOutputCommitter.java:<init>(108)) - File Output Committer Algorithm version is 1 2017-09-07 21:08:30,458 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(192)) - ProcfsBasedProcessTree currently is supported only on Linux. 2017-09-07 21:08:30,766 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(612)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@285eaab5 2017-09-07 21:08:30,770 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(756)) - Processing split: hdfs://192.168.56.101:8020/user/hadoop/input1/file0:0+20 2017-09-07 21:08:30,817 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1205)) - (EQUATOR) 0 kvi 26214396(104857584) 2017-09-07 21:08:30,818 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(998)) - mapreduce.task.io.sort.mb: 100 2017-09-07 21:08:30,818 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(999)) - soft limit at 83886080 2017-09-07 21:08:30,818 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(1000)) - bufstart = 0; bufvoid = 104857600 2017-09-07 21:08:30,818 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(1001)) - kvstart = 26214396; length = 6553600 2017-09-07 21:08:30,822 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(403)) - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2017-09-07 21:08:31,095 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 2017-09-07 21:08:31,101 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1460)) - Starting flush of map output 2017-09-07 21:08:31,102 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1482)) - Spilling map output 2017-09-07 21:08:31,102 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1483)) - bufstart = 0; bufend = 36; bufvoid = 104857600 2017-09-07 21:08:31,102 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1485)) - kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600 2017-09-07 21:08:31,122 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:sortAndSpill(1667)) - Finished spill 0 2017-09-07 21:08:31,135 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(1038)) - Task:attempt_local2028239795_0001_m_000000_0 is done. And is in the process of committing 2017-09-07 21:08:31,145 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - map 2017-09-07 21:08:31,145 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1158)) - Task 'attempt_local2028239795_0001_m_000000_0' done. 2017-09-07 21:08:31,145 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(249)) - Finishing task: attempt_local2028239795_0001_m_000000_0 2017-09-07 21:08:31,145 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(224)) - Starting task: attempt_local2028239795_0001_m_000001_0 2017-09-07 21:08:31,146 INFO [LocalJobRunner Map Task Executor #0] output.FileOutputCommitter (FileOutputCommitter.java:<init>(108)) - File Output Committer Algorithm version is 1 2017-09-07 21:08:31,147 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(192)) - ProcfsBasedProcessTree currently is supported only on Linux. 2017-09-07 21:08:31,210 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(612)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@50a4a6f0 2017-09-07 21:08:31,212 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(756)) - Processing split: hdfs://192.168.56.101:8020/user/hadoop/input1/file1:0+17 2017-09-07 21:08:31,245 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1205)) - (EQUATOR) 0 kvi 26214396(104857584) 2017-09-07 21:08:31,246 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(998)) - mapreduce.task.io.sort.mb: 100 2017-09-07 21:08:31,246 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(999)) - soft limit at 83886080 2017-09-07 21:08:31,246 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(1000)) - bufstart = 0; bufvoid = 104857600 2017-09-07 21:08:31,246 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(1001)) - kvstart = 26214396; length = 6553600 2017-09-07 21:08:31,247 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(403)) - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2017-09-07 21:08:31,252 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 2017-09-07 21:08:31,252 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1460)) - Starting flush of map output 2017-09-07 21:08:31,252 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1482)) - Spilling map output 2017-09-07 21:08:31,252 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1483)) - bufstart = 0; bufend = 29; bufvoid = 104857600 2017-09-07 21:08:31,252 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1485)) - kvstart = 26214396(104857584); kvend = 26214388(104857552); length = 9/6553600 2017-09-07 21:08:31,261 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:sortAndSpill(1667)) - Finished spill 0 2017-09-07 21:08:31,270 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(1038)) - Task:attempt_local2028239795_0001_m_000001_0 is done. And is in the process of committing 2017-09-07 21:08:31,273 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - map 2017-09-07 21:08:31,273 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1158)) - Task 'attempt_local2028239795_0001_m_000001_0' done. 2017-09-07 21:08:31,273 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(249)) - Finishing task: attempt_local2028239795_0001_m_000001_0 2017-09-07 21:08:31,273 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - map task executor complete. 2017-09-07 21:08:31,276 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for reduce tasks 2017-09-07 21:08:31,276 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(302)) - Starting task: attempt_local2028239795_0001_r_000000_0 2017-09-07 21:08:31,285 INFO [pool-6-thread-1] output.FileOutputCommitter (FileOutputCommitter.java:<init>(108)) - File Output Committer Algorithm version is 1 2017-09-07 21:08:31,286 INFO [pool-6-thread-1] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(192)) - ProcfsBasedProcessTree currently is supported only on Linux. 2017-09-07 21:08:31,360 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1360)) - Job job_local2028239795_0001 running in uber mode : false 2017-09-07 21:08:31,361 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 100% reduce 0% 2017-09-07 21:08:31,377 INFO [pool-6-thread-1] mapred.Task (Task.java:initialize(612)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@1af25560 2017-09-07 21:08:31,381 INFO [pool-6-thread-1] mapred.ReduceTask (ReduceTask.java:run(362)) - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@26f5d2fd 2017-09-07 21:08:31,395 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:<init>(197)) - MergerManager: memoryLimit=1303589632, maxSingleShuffleLimit=325897408, mergeThreshold=860369216, ioSortFactor=10, memToMemMergeOutputsThreshold=10 2017-09-07 21:08:31,397 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(61)) - attempt_local2028239795_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 2017-09-07 21:08:31,428 INFO [localfetcher#1] reduce.LocalFetcher (LocalFetcher.java:copyMapOutput(144)) - localfetcher#1 about to shuffle output of map attempt_local2028239795_0001_m_000000_0 decomp: 46 len: 50 to MEMORY 2017-09-07 21:08:31,432 INFO [localfetcher#1] reduce.InMemoryMapOutput (InMemoryMapOutput.java:shuffle(100)) - Read 46 bytes from map-output for attempt_local2028239795_0001_m_000000_0 2017-09-07 21:08:31,434 INFO [localfetcher#1] reduce.MergeManagerImpl (MergeManagerImpl.java:closeInMemoryFile(315)) - closeInMemoryFile -> map-output of size: 46, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->46 2017-09-07 21:08:31,439 INFO [localfetcher#1] reduce.LocalFetcher (LocalFetcher.java:copyMapOutput(144)) - localfetcher#1 about to shuffle output of map attempt_local2028239795_0001_m_000001_0 decomp: 37 len: 41 to MEMORY 2017-09-07 21:08:31,440 INFO [localfetcher#1] reduce.InMemoryMapOutput (InMemoryMapOutput.java:shuffle(100)) - Read 37 bytes from map-output for attempt_local2028239795_0001_m_000001_0 2017-09-07 21:08:31,440 INFO [localfetcher#1] reduce.MergeManagerImpl (MergeManagerImpl.java:closeInMemoryFile(315)) - closeInMemoryFile -> map-output of size: 37, inMemoryMapOutputs.size() -> 2, commitMemory -> 46, usedMemory ->83 2017-09-07 21:08:31,441 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(76)) - EventFetcher is interrupted.. Returning 2017-09-07 21:08:31,441 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 2 / 2 copied. 2017-09-07 21:08:31,442 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(687)) - finalMerge called with 2 in-memory map-outputs and 0 on-disk map-outputs 2017-09-07 21:08:31,454 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(606)) - Merging 2 sorted segments 2017-09-07 21:08:31,454 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(705)) - Down to the last merge-pass, with 2 segments left of total size: 69 bytes 2017-09-07 21:08:31,459 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(754)) - Merged 2 segments, 83 bytes to disk to satisfy reduce memory limit 2017-09-07 21:08:31,460 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(784)) - Merging 1 files, 85 bytes from disk 2017-09-07 21:08:31,461 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(799)) - Merging 0 segments, 0 bytes from memory into reduce 2017-09-07 21:08:31,461 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(606)) - Merging 1 sorted segments 2017-09-07 21:08:31,462 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(705)) - Down to the last merge-pass, with 1 segments left of total size: 74 bytes 2017-09-07 21:08:31,462 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 2 / 2 copied. 2017-09-07 21:08:31,494 INFO [pool-6-thread-1] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1173)) - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 2017-09-07 21:08:31,600 INFO [pool-6-thread-1] mapred.Task (Task.java:done(1038)) - Task:attempt_local2028239795_0001_r_000000_0 is done. And is in the process of committing 2017-09-07 21:08:31,605 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 2 / 2 copied. 2017-09-07 21:08:31,605 INFO [pool-6-thread-1] mapred.Task (Task.java:commit(1199)) - Task attempt_local2028239795_0001_r_000000_0 is allowed to commit now 2017-09-07 21:08:31,631 INFO [pool-6-thread-1] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(535)) - Saved output of task 'attempt_local2028239795_0001_r_000000_0' to hdfs://192.168.56.101:8020/user/hadoop/output2/_temporary/0/task_local2028239795_0001_r_000000 2017-09-07 21:08:31,632 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - reduce > reduce 2017-09-07 21:08:31,632 INFO [pool-6-thread-1] mapred.Task (Task.java:sendDone(1158)) - Task 'attempt_local2028239795_0001_r_000000_0' done. 2017-09-07 21:08:31,632 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(325)) - Finishing task: attempt_local2028239795_0001_r_000000_0 2017-09-07 21:08:31,632 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - reduce task executor complete. 2017-09-07 21:08:32,363 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 100% reduce 100% 2017-09-07 21:08:32,363 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1378)) - Job job_local2028239795_0001 completed successfully 2017-09-07 21:08:32,376 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1385)) - Counters: 35 File System Counters FILE: Number of bytes read=1675 FILE: Number of bytes written=843672 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=94 HDFS: Number of bytes written=45 HDFS: Number of read operations=22 HDFS: Number of large read operations=0 HDFS: Number of write operations=5 Map-Reduce Framework Map input records=2 Map output records=7 Map output bytes=65 Map output materialized bytes=91 Input split bytes=232 Combine input records=7 Combine output records=7 Reduce input groups=6 Reduce shuffle bytes=91 Reduce input records=7 Reduce output records=6 Spilled Records=14 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=0 Total committed heap usage (bytes)=1005060096 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=37 File Output Format Counters Bytes Written=45 Process finished with exit code 0
以上。

相关文章推荐
- Windows平台开发Mapreduce程序远程调用运行在Hadoop集群—Yarn调度引擎异常
- Windows下使用eclipse编译打包运行自己的MapReduce程序 Hadoop2.6.0
- windows下不需要插件使用MyEclipse运行hadoop2.6.0 MapReduce程序。
- Hadoop: Intellij结合Maven本地运行和调试MapReduce程序 (无需搭载Hadoop和HDFS环境)
- windows下使用Eclipse编译运行MapReduce程序 Hadoop2.6.0/Ubuntu
- 使用委托异步调用方法让程序并行运行
- Win系统下用Eclipse中运行远程hadoop MapReduce程序出现Permission denied错误
- Windows 强制指定程序使用 普通权限(invoker调用者权限)运行的方法
- 在windows上用eclipse远程运行hadoop上的wordcount程序出现的问题,求解决
- Ubuntu系统下的Hadoop集群(4)_使用Eclipse编译运行MapReduce程序
- 使用Eclipse编译运行MapReduce程序 Hadoop2.4.1
- Hadoop — 使用Eclipse编译运行MapReduce程序(Hadoop2.6.0)
- 如何在windows上使用eclipse远程连接hadoop进行程序开发
- hadoop 从客户端的hdfs测试程序连到linux 上的hadoop(hdfs)要调用的方法
- 使用Eclipse编译运行MapReduce程序 Hadoop2.7.1/Ubuntu
- ubuntu14.04环境下hadoop2.7.0配置+在windows下远程eclipse和hdfs的调用
- 使用Eclipse编译运行MapReduce程序 Hadoop2.6.0/Ubuntu
- 如何在windows上使用eclipse远程连接hadoop进行程序开发
- 运行hadoop MapReduce程序常见错误及解决方法整理
- Ubuntu系统下的Hadoop集群(2)_使用命令行编译打包运行自己的MapReduce程序