基于RESTful API的TCC补偿模式 分布式事务
2017-09-05 18:09
288 查看
前言
本例基于Atomikos提出的微服务分布式事务的解决方案, 该方案建立在更加轻量级的HTTP协议之上, 原文如下TCC for transaction management across
microservices
根据Try Confirm Cancel补偿模式, 有关于Spring Cloud的实战如下
https://github.com/prontera/solar
示例场景
一个简单的TCC应用如下: 图中蓝色方框Booking Process代表订票系统, 该系统分别对swiss和easyjet发起预留机票资源的请求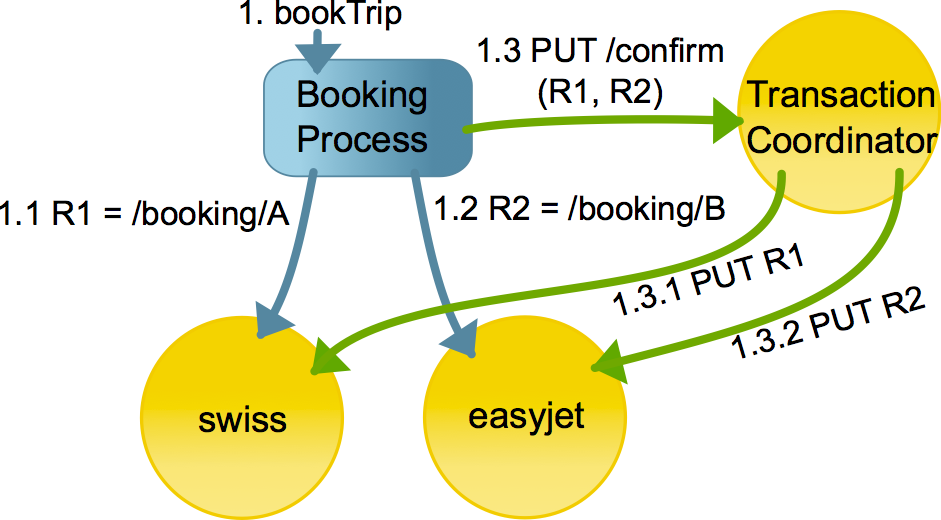
在步骤1.1对"swiss"发起Try预留请求. 服务提供方"swiss"将会等待Confirm操作, 如果超时那么就将会被自动撤销(Cancel)并释放资源. 确认资源的入口就是URI R1的HTTP PUT请求.
在步骤1.2中, 使用URI R2对"easyjet"作出如第一点中一样的预留资源操作
在步骤1.3中, Booking Process现在可以通过协调器(Coordinator)服务发起对上述两个预留资源的确认(Confirm)操作. 并且, 资源协调服务会处理相关服务的确认或者补偿操作.
如果在第3步之前有任何异常, 那么所有预留资源将会被Cancel或者等待超时然后被自动撤销. 如果是在第3步Confirm之后才出现异常, 那么所有的资源都不会受到影响. 在第3步中发生的异常都会由Coordinator服务处理, 包括因为宕机或者是网络抖动所引起的恢复重试. 对REST服务提供了事务保证.
角色
这套API由3个角色组成: 参与者角色, 协调者角色和应用程序.参与者是特指那些实现了TCC柔性事务的应用程序, 就正如本示例中的"swiss"和"easyjet"
协调者角色是特指那些管理一组相关参与者的服务调用, 如Confirm, Cancel操作, 在本示例中是"Transaction Coordinator"
应用程序, 这里我称之为请求方, 除了需要使用协调器外无其他要求, 如本示例中的"Booking Process"
TCC服务提供方: 参与者API
参与者职责
参与者负责管理特定的业务资源. 默认情况下业务预留资源在一定时间后会超时, 除非该预留资源被协调器所确认.
自动超时和撤回
每一个参与者的实现必须有自动Cancel超时资源的功能. 除非参与者接收到确认消息, 否则没有资源是不会过期的.
资源操作的入口
每个参与者的实现必须返回一个用于调用Confirm的链接. 这些链接可以包含Confirm的URI, 自动过期时间等元数据. 下面是一个简单例子{
"participantLink":
{"uri":"http://www.example.com/part/123",
"expires":"2014-01-11T10:15:54Z"
}
}实际上例子中的JSON只是建议格式, 真实使用的时候完全取决于双方的通信格式.
PUT to Confirm
在上述参与者返回的用于确认的链接中, 必须支持PUT方法以用于确认. 由于网络抖动等情况, 该操作必须具备幂等性.PUT /part/123 HTTP/1.1 Host: www.example.com Accept: application/tcc
注意请求头中MIME类型, 暗示了客户端的语义期望(可根据实际情况选择是否实现该MediaType). Confirm操作通常由协调者调用.
尽管参与者提供的API有指定的MIME类型, 但是这个类型仅仅用于指明语义, 实际上并不需要request body与response body.
如果一切正常, 那么参与者的响应如下
HTTP/1.1 204 No Content
如果Confirm请求送达参与者后发现预留资源早就被Cancel或者已经超时被回滚, 那么参与者的API必须返回404错误
HTTP/1.1 404 Not Found
DELETE to Cancel: 可选实现
每个参与者URI或许会有实现DELETE方法去显式地接受撤销请求. 由于网络抖动等情况, 该操作必须具备幂等性.DELETE /part/123 HTTP/1.1 Host: www.example.com Accept: application/tcc
如果补偿成功则返回
HTTP/1.1 204 No Content
因为参与者有实现自动撤销超时资源的职责, 那么如果在显式地调用Cancel的时候有其他错误发生, 那么这些错误都可以被忽略而且不影响整体的分布式事务
在内部事务已经超时或者已经被参与者自身补偿之后, 那么他可以直接返回404
HTTP/1.1 404 Not Found
因为DELETE请求是一个可选操作, 有些参与者可能没有实现这个功能, 在这个情况下可以返回405
HTTP/1.1 405 Method Not Allowed
GET方法故障诊断: 可选实现
参与方服务可以实现GET方法来用于故障的诊断. 但是这个超出了REST TCC的简约协议的意图, 所以这个功能就由实际情况来决定是否实现
协调器API: 面向请求方的开发者
协调器服务是由我们实现, 并交由请求方的开发人员使用. 因为这里从使用RESTful接口的设计角度来说明, 而不讨论协调器的内部实现.
协调器职责
对所有参与者发起Confirm请求无论是协调器发生的错误还是调用参与者所产生的错误, 协调器都必须有自动恢复重试功能, 尤其是在确认的阶段.
能判断有问题的Confirm操作的原因
方便地进行Cancel操作
PUT to Confirm
请求方对协调器发出PUT请求来确认当前的分布式事务. 这些事务就是参与者之前返回给请求方的确认链接PUT /coordinator/confirm HTTP/1.1
Host: www.taas.com
Content-Type: application/tcc+json
{
"participantLinks": [
{
"uri": "http://www.example.com/part1",
"expires": "2014-01-11T10:15:54Z"
},
{
"uri": "http://www.example.com/part2",
"expires": "2014-01-11T10:15:54+01:00"
}
]
}然后协调器会对参与者逐个发起Confirm请求, 如果一切顺利那么将会返回如下结果
HTTP/1.1 204 No Content
如果发起Confirm请求的时间太晚, 那么意味着所有被动方都已经进行了超时补偿
HTTP/1.1 404 Not Found
最最最糟糕的情况就是有些参与者确认了, 但是有些就没有. 这种情况就应该要返回409, 这种情况在Atomikos中定义为启发式异常
HTTP/1.1 409 Conflict
当然, 这种情况应该尽量地避免发生, 要求Confirm与Cancel实现幂等性, 出现差错时协调器可多次对参与者重试以尽量降低启发性异常发生的几率. 万一409真的发生了, 则应该由请求方主动进行检查或者由协调器返回给请求方详细的执行信息, 例如对每个参与者发起故障诊断的GET请求,
记录故障信息并进行人工干预.
PUT to Cancel
一个撤销请求跟确认请求类似, 都是使用PUT请求, 唯一的区别是URI的不同PUT /coordinator/cancel HTTP/1.1
Host: www.taas.com
Content-Type: application/tcc+json
{
"participantLinks": [
{
"uri": "http://www.example.com/part1",
"expires": "2014-01-11T10:15:54Z"
},
{
"uri": "http://www.example.com/part2",
"expires": "2014-01-11T10:15:54Z"
}
]
}唯一可预见的响应就是
HTTP/1.1 204 No Content
因为当预留资源没有被确认时最后都会被释放, 所以参与者返回其他错误也不会影响最终一致性

相关文章推荐
- 基于RESTful API的TCC补偿模式 分布式事务
- 基于RESTful API的TCC补偿模式 分布式事务
- 基于RESTful API的TCC补偿模式 分布式事务
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究 转载
- 分布式事务之——tcc-transaction分布式TCC型事务框架搭建与实战案例(基于Dubbo/Dubbox)
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究[转]
- 分布式事务之——tcc-transaction分布式TCC型事务框架搭建与实战案例(基于Dubbo/Dubbox)
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 如何选择分布式事务形态(TCC,SAGA,2PC,基于消息最终一致性等等)
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究[转]
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究[转]