线性回归与逻辑回归
2017-09-02 20:12
141 查看
1. 梯度下降法 (Gradient Descent)
梯度下降法是一种用来寻找函数最小值的算法。算法的思想非常简单:每次沿与当前梯度方向相反的方向走一小步,并不断重复这一过程。举例如下:
[例]使用梯度下降法,求z=0.3x2+0.4y2+2的最小值。
第一步:求解迭代格式。根据“每次沿与当前梯度方向相反的方向走一小步”的思想,可知x(k+1)=x(k)-0.6x(k), y(k+1)=y(k)-0.8y(k)
第二步:选择迭代的初始值。初始值一般可以随意选择,但恰当的初始值有助于提升收敛速度。本例中选择x(0)=1, y(0)=1
第三步:根据迭代格式和初始值进行迭代求解。迭代过程如下:
结论:可以发现,第6次迭代后,算法收敛。所求最小值为2。
梯度下降算法如何进行收敛判定呢?一个通用的方法是判断相邻两次迭代中,目标值变化量的绝对值是否足够小。具体到上述例题,就是判断|z(x(k+1),y(k+1))-z(x(k),y(k))|<eps是否成立。eps是一个足够小的正实数,可以根据所需要的精度进行选取,本例中eps=10-4。
需要注意的是,梯度下降法有可能陷入局部最优解。可以通过多次随机选取初始值以及增加冲量项等方法加以改善,本系列后续文章中可能涉及。
2. 线性回归 (Linear Regression)
线性回归是对自变量和因变量之间关系进行建模的回归分析,回归函数满足如下形式:

我们使用
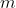
表示数据组数,使用
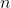
表示数据的维数;使用
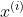
和

表示第

组数据的自变量和因变量,使用

表示第
组数据自变量的第
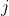
个分量。推导过程基于如下假设:

即每一组数据的误差项相互独立,且均服从均值为0,方差为
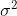
的正态分布。进而,我们可以得到似然函数:

对数似然函数:

化简,可得:

定义损失函数:

要使似然函数最大,只需使损失函数最小。我们使用损失函数的极小值代替最小值,只需对每一个

求偏导数:

最后,使用梯度下降法迭代求解:

其中,
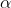
为学习率,是一个大于0的常数。学习率应当慎重选择,过大会导致算法不收敛,过小会导致收敛速度缓慢。在实际应用中,可以根据具体情况对学习率进行调节。有资料表明,当


时,上述算法收敛。由于

难以高效计算,因此往往使用

来代替。
3. 逻辑回归 (Logistic Regression)
当因变量只能在{0,1}中取值时,线性回归模型不再适合,因为极端数据的存在会使阀值的选择变得困难。我们可以使用逻辑回归对数据进行建模。回归函数满足如下形式:

其中:

sigmoid函数具有如下性质:

推导过程基于如下假设:(其实就是假设y(i)~Bernoulli(hθ(x(i))))



考虑到
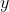
取值的特殊性,上述假设等价于以下形式:

进而得到似然函数:

对数似然函数:

化简,得:

定义损失函数:

要使似然函数最大,只需使损失函数最小。我们使用损失函数的极小值代替最小值,只需对每一个
求偏导数:

化简,得:
最后,使用梯度下降法迭代求解:
含义同上。
LR为什么使用Sigmoid函数?
Sigmoid函数实质上以分类为目的出现的。传统的回归直接给出具体值,而当某些情况想知道某件事的概率时,这个函数就有用了,其将数值限定在0~1之间,从而原有的数值转化为概率,sigmoid函数是推导出来的。设y = p(c1|x),1-y=p(c2|x),则可以用y 的对数比率logit(y)来得到判定的概率,logit(y)=ln(y/(1-y)).LR有sigmoid函数,与基本的线性回归不同就在于使用了一个S形函数,将原来的数值转换到0~1之间。
梯度下降法是一种用来寻找函数最小值的算法。算法的思想非常简单:每次沿与当前梯度方向相反的方向走一小步,并不断重复这一过程。举例如下:
[例]使用梯度下降法,求z=0.3x2+0.4y2+2的最小值。
第一步:求解迭代格式。根据“每次沿与当前梯度方向相反的方向走一小步”的思想,可知x(k+1)=x(k)-0.6x(k), y(k+1)=y(k)-0.8y(k)
第二步:选择迭代的初始值。初始值一般可以随意选择,但恰当的初始值有助于提升收敛速度。本例中选择x(0)=1, y(0)=1
第三步:根据迭代格式和初始值进行迭代求解。迭代过程如下:
| k | x(k) | y(k) | z(x(k),y(k)) |
| 0 | 1.00 | 1.00 | 2.7000 |
| 1 | 0.40 | 0.20 | 2.0640 |
| 2 | 0.16 | 0.04 | 2.0083 |
| 3 | 0.06 | 0.01 | 2.0013 |
| 4 | 0.03 | 0.00 | 2.0002 |
| 5 | 0.01 | 0.00 | 2.0000 |
| 6 | 0.00 | 0.00 | 2.0000 |
梯度下降算法如何进行收敛判定呢?一个通用的方法是判断相邻两次迭代中,目标值变化量的绝对值是否足够小。具体到上述例题,就是判断|z(x(k+1),y(k+1))-z(x(k),y(k))|<eps是否成立。eps是一个足够小的正实数,可以根据所需要的精度进行选取,本例中eps=10-4。
需要注意的是,梯度下降法有可能陷入局部最优解。可以通过多次随机选取初始值以及增加冲量项等方法加以改善,本系列后续文章中可能涉及。
2. 线性回归 (Linear Regression)
线性回归是对自变量和因变量之间关系进行建模的回归分析,回归函数满足如下形式:
我们使用
表示数据组数,使用
表示数据的维数;使用
和
表示第
组数据的自变量和因变量,使用
表示第
组数据自变量的第
个分量。推导过程基于如下假设:
即每一组数据的误差项相互独立,且均服从均值为0,方差为
的正态分布。进而,我们可以得到似然函数:
对数似然函数:
化简,可得:
定义损失函数:
要使似然函数最大,只需使损失函数最小。我们使用损失函数的极小值代替最小值,只需对每一个
求偏导数:
最后,使用梯度下降法迭代求解:
其中,
为学习率,是一个大于0的常数。学习率应当慎重选择,过大会导致算法不收敛,过小会导致收敛速度缓慢。在实际应用中,可以根据具体情况对学习率进行调节。有资料表明,当
时,上述算法收敛。由于
难以高效计算,因此往往使用
来代替。
3. 逻辑回归 (Logistic Regression)
当因变量只能在{0,1}中取值时,线性回归模型不再适合,因为极端数据的存在会使阀值的选择变得困难。我们可以使用逻辑回归对数据进行建模。回归函数满足如下形式:
其中:
sigmoid函数具有如下性质:
推导过程基于如下假设:(其实就是假设y(i)~Bernoulli(hθ(x(i))))
考虑到
取值的特殊性,上述假设等价于以下形式:
进而得到似然函数:
对数似然函数:
化简,得:
定义损失函数:
要使似然函数最大,只需使损失函数最小。我们使用损失函数的极小值代替最小值,只需对每一个
求偏导数:
化简,得:
最后,使用梯度下降法迭代求解:
含义同上。
LR为什么使用Sigmoid函数?
Sigmoid函数实质上以分类为目的出现的。传统的回归直接给出具体值,而当某些情况想知道某件事的概率时,这个函数就有用了,其将数值限定在0~1之间,从而原有的数值转化为概率,sigmoid函数是推导出来的。设y = p(c1|x),1-y=p(c2|x),则可以用y 的对数比率logit(y)来得到判定的概率,logit(y)=ln(y/(1-y)).LR有sigmoid函数,与基本的线性回归不同就在于使用了一个S形函数,将原来的数值转换到0~1之间。

相关文章推荐
- Matlab实现线性回归和逻辑回归: Linear Regression & Logistic Regression
- [置顶] 线性回归和逻辑回归
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 机器学习中的逻辑回归和线性回归的matlab程序实现
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 关于线性回归和逻辑回归一些深入的思考
- 线性回归和逻辑回归的直接区别
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 线性回归和逻辑回归
- 一元线性回归,多元线性回归、逻辑回归概念学习
- 线性回归、逻辑回归、损失函数
- [TensorFlow]入门学习笔记(4)-BasicModel 线性回归,逻辑回归和最近邻模型
- Spark ML机器学习算法svm,als,线性回归,逻辑回归简单试验
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- 线性回归与逻辑回归
- Coursera机器学习线性回归和逻辑回归相关概念记录
- 初学ML笔记N0.1——线性回归,分类与逻辑斯蒂回归,通用线性模型
- [回归问题] 逻辑回归,线性回归
- SparkMLlib---LinearRegression(线性回归)、LogisticRegression(逻辑回归)
- 机器学习算法总结--线性回归和逻辑回归