【文本挖掘学习交流】用Python带你走进神秘的“谍纸天眼”...
2017-08-30 18:32
260 查看
近期热播的电视剧《楚乔传》即将迎来收尾,观众在网络中的讨论声一直高涨不减,尤其是对里面“谍纸天眼”的热情丝毫不亚于当年的“洪荒之力”。“谍纸天眼”的主要职能就是为国家(皇帝)进行情报搜集、分析处理,并执行一些秘密任务。分布在天下各个角落的谍者将搜集的军事、门阀、官员和民情等各类情报送到谍纸楼进行分析处理并存档,然后再将结果交给上层管理者或等其需要的时候随时调取查阅,可以说是一个强大的数据分析处理系统。作为一名文本挖掘的爱好者,就想在与大家分享一些文本挖掘知识的基础上,用Python从剧情文本中探索更多有关谍纸天眼的秘密......若有不足之处还望大家批评指正。
一 剧情文本采集
进行分析之前首先需要获取剧情的文本,因为剧中改编较多,为了尽量接近大家所熟悉的剧情,故没有直接爬取小说来进行分析,而是从百度百科上爬取每一集的剧情,针对已更新的剧情文本进行分析。利用python的urllib2和BeautifulSoup包可以很快的爬下剧情文本,保存为chuqiaozhuan.txt文档,顺便将出现的人物名字也一起爬下来,后面进行预处理和分析中涉及到的分词、实体属性对齐和社交网络分析等都将会用到。代码和文本如下图所示:
代码1:
爬取的文本:
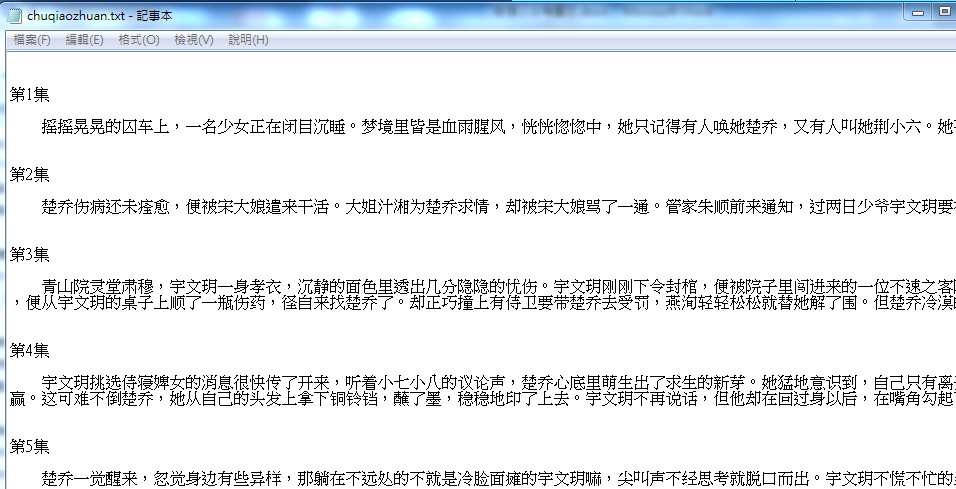
二 文本预处理
将剧情爬下来后需要对文本进行预处理,主要包括分句、分词、去掉一些特殊符号和停用词、实体对齐和属性对齐等。如同一个人可能在剧中有不同的名字,这时候就需要进行统一。为了尽量正确的切分一些固定名称,需要导入自定义词典,主要包含一些人名、地名和组织名称等。此外,在提取文本特征时需要去掉一些停用词,以提高分析的准确度。经过一系列处理后得到比较干净的文本分词结果,然后就可以在此基础上进行深入的分析。
代码2:

预处理结果:

三 人物出现频次和社交网络关系
先来看一下剧中出场次数较多的关键人物有哪些,根据之前爬下来的名字列表,统计其在文本中出现的次数,通过matplotlib包画出出现次数最多的10个关键人物如图所示,可以发现楚乔出现次数最多,共1060次,其次宇文玥出现了589次,再次是燕洵出现了565次。在剧中大家可能会觉得燕洵才应该是该剧的男主角,因为整部剧都在围绕着他复仇路线来展开,而宇文玥只是出来打酱油的。但从出场频次来看,编剧还是倾向于给宇文玥更多的情节。
代码3:
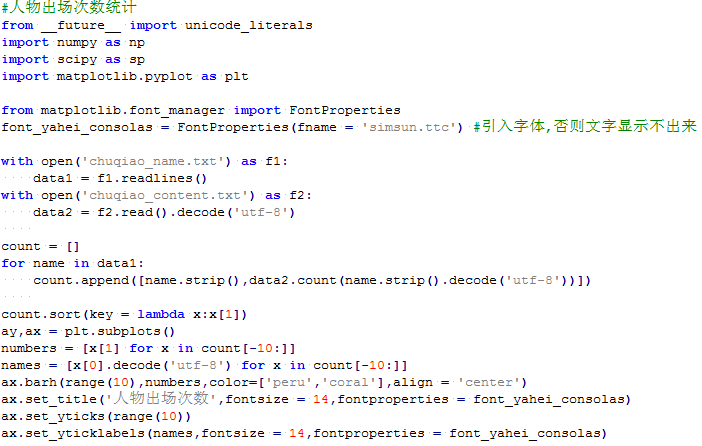
人物出场频次:

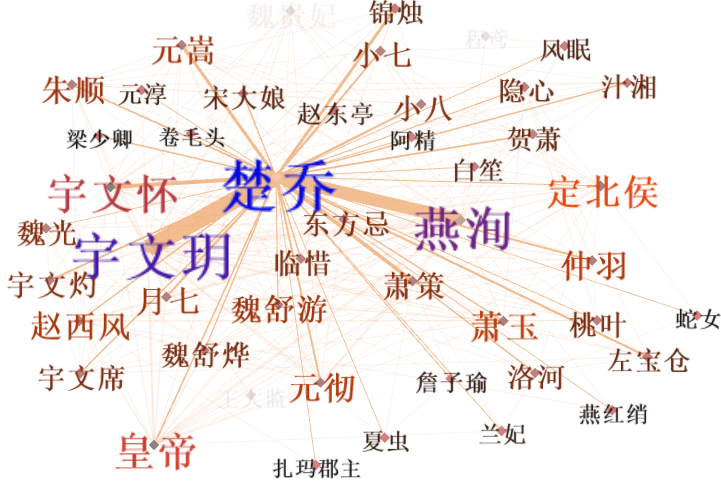
再来看看剧中人物的社交关系情况,采用以句为单位来进行分析(有时候也以段落为单位来识别人物关系,但采集的文本每集只有一个段落,所以不适用),即如果两个人同时出现在一句话中,那说明他们之间肯定有某种联系。因此可以得到他们的社交网络关系。通过求得的共现矩阵,画出下面的社交网络关系图,图中边的粗细代表关系的密切程度,边越粗表示两人的关系越密切,而节点的大小可以表示为该人的社交人脉强弱情况。
社交情况:
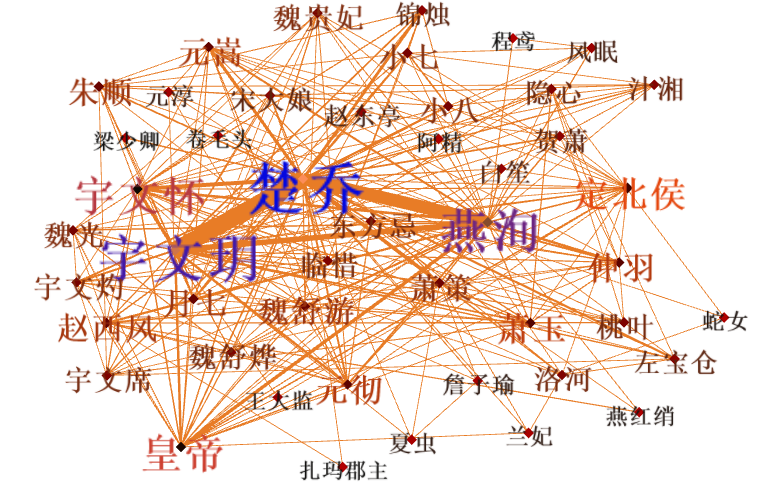
主角的社交情况:
四 走进“谍纸天眼”
1.基于TF-IDF提取关键词
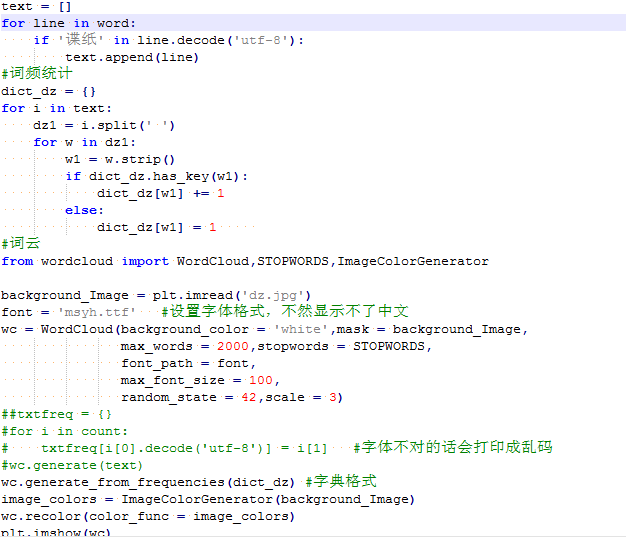
接下来重点探索一下小编比较感兴趣的“谍纸天眼”,先通过关键字抓取出相关剧情,然后使用python的wordcloud包生成词云,wordcloud可以导入图片自定义词云的形状,非常方便,但是需要注意中文编码和字体的问题,否则生成的词云会显示成乱码。从词云中可以看到,词频较高的词有宇文玥、宇文怀、皇帝和大梁等。
代码5:
词云图:

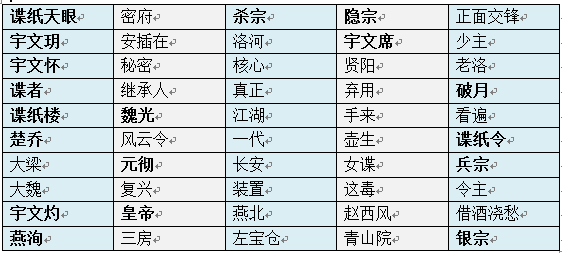
但出现频数多的词并不能代表是文本中的关键词,故使用TF-IDF进行关键词提取。TF-IDF权重通过计算词频和逆向文件频率来计算,这里直接利用jieba分词工具进行提取,列出50个关键词如下表所示,可以发现与谍纸天眼相关的人物主要是宇文家族,此外,还有一些比较特别的词,如谍者、谍纸楼、谍纸令、杀宗、隐宗、兵宗、银宗等,通过这些关键词我们可以比较清楚的知道有关谍纸天眼的大部分信息。例如,谍纸天眼的掌管着很可能是宇文家族,其组成部分包含杀宗、隐宗、兵宗和银宗,各部分执行不同的任务。如果想看到每个词具体的TF-IDF权重也可以利用scikit-learn包进行计算,然后再根据权重的大小进行重要性排序。
代码6:

关键字:
2.运用word2vec挖掘语义相似关系
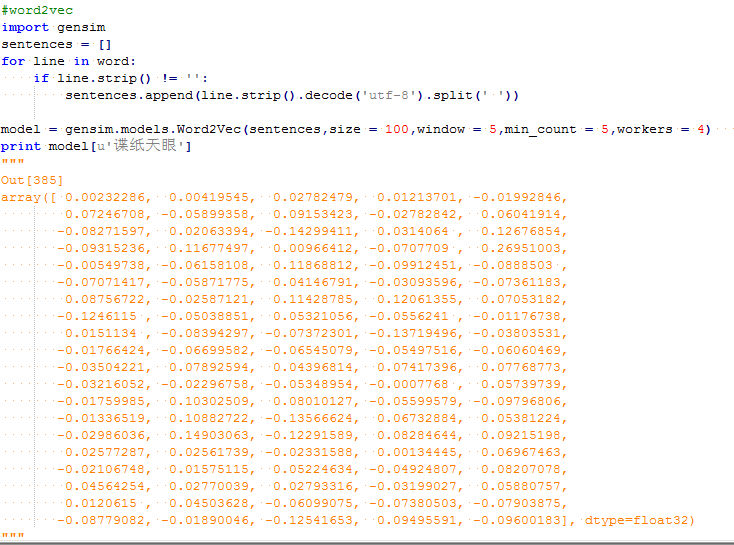
文本分析中也经常会用到word2vec将文本转化为词向量的形式后来挖掘词语语义上的相似关系。导入gensim库后,将文本转化为模型输入的形式后进行训练,然后就可以得到每个词的向量形式。例如打印出“谍纸天眼”的向量如输出结果所示。
代码7:
根据词向量,可以比较各词的相似度,或者寻找对应关系,如:


可以看出文本中“谍纸天眼”与“宇文玥”的相似度为0.9994,而在给定“大魏”与“宇文玥”的关系后,可以发现与燕北有类似关系的词主要有燕洵等。虽然乱进了少量无特别含义的词,但并无太大影响。此外,还可以根据训练出来的词向量进行k-means聚类等等,感兴趣的朋友可以进一步的尝试。

如需下载本文代码的.py文件,请查看原文,谢谢!
文章来源:http://mp.weixin.qq.com/s/VfntJcP_VolTs7iJopiBxQ
投诉
鸣谢:感谢阅读!
近期热播的电视剧《楚乔传》即将迎来收尾,观众在网络中的讨论声一直高涨不减,尤其是对里面“谍纸天眼”的热情丝毫不亚于当年的“洪荒之力”。“谍纸天眼”的主要职能就是为国家(皇帝)进行情报搜集、分析处理,并执行一些秘密任务。分布在天下各个角落的谍者将搜集的军事、门阀、官员和民情等各类情报送到谍纸楼进行分析处理并存档,然后再将结果交给上层管理者或等其需要的时候随时调取查阅,可以说是一个强大的数据分析处理系统。作为一名文本挖掘的爱好者,就想在与大家分享一些文本挖掘知识的基础上,用Python从剧情文本中探索更多有关谍纸天眼的秘密......若有不足之处还望大家批评指正。
一 剧情文本采集
进行分析之前首先需要获取剧情的文本,因为剧中改编较多,为了尽量接近大家所熟悉的剧情,故没有直接爬取小说来进行分析,而是从百度百科上爬取每一集的剧情,针对已更新的剧情文本进行分析。利用python的urllib2和BeautifulSoup包可以很快的爬下剧情文本,保存为chuqiaozhuan.txt文档,顺便将出现的人物名字也一起爬下来,后面进行预处理和分析中涉及到的分词、实体属性对齐和社交网络分析等都将会用到。代码和文本如下图所示:
代码1:
爬取的文本:
二 文本预处理
将剧情爬下来后需要对文本进行预处理,主要包括分句、分词、去掉一些特殊符号和停用词、实体对齐和属性对齐等。如同一个人可能在剧中有不同的名字,这时候就需要进行统一。为了尽量正确的切分一些固定名称,需要导入自定义词典,主要包含一些人名、地名和组织名称等。此外,在提取文本特征时需要去掉一些停用词,以提高分析的准确度。经过一系列处理后得到比较干净的文本分词结果,然后就可以在此基础上进行深入的分析。
代码2:
预处理结果:
三 人物出现频次和社交网络关系
先来看一下剧中出场次数较多的关键人物有哪些,根据之前爬下来的名字列表,统计其在文本中出现的次数,通过matplotlib包画出出现次数最多的10个关键人物如图所示,可以发现楚乔出现次数最多,共1060次,其次宇文玥出现了589次,再次是燕洵出现了565次。在剧中大家可能会觉得燕洵才应该是该剧的男主角,因为整部剧都在围绕着他复仇路线来展开,而宇文玥只是出来打酱油的。但从出场频次来看,编剧还是倾向于给宇文玥更多的情节。
代码3:
人物出场频次:
再来看看剧中人物的社交关系情况,采用以句为单位来进行分析(有时候也以段落为单位来识别人物关系,但采集的文本每集只有一个段落,所以不适用),即如果两个人同时出现在一句话中,那说明他们之间肯定有某种联系。因此可以得到他们的社交网络关系。通过求得的共现矩阵,画出下面的社交网络关系图,图中边的粗细代表关系的密切程度,边越粗表示两人的关系越密切,而节点的大小可以表示为该人的社交人脉强弱情况。
社交情况:
主角的社交情况:
四 走进“谍纸天眼”
1.基于TF-IDF提取关键词
接下来重点探索一下小编比较感兴趣的“谍纸天眼”,先通过关键字抓取出相关剧情,然后使用python的wordcloud包生成词云,wordcloud可以导入图片自定义词云的形状,非常方便,但是需要注意中文编码和字体的问题,否则生成的词云会显示成乱码。从词云中可以看到,词频较高的词有宇文玥、宇文怀、皇帝和大梁等。
代码5:
词云图:
但出现频数多的词并不能代表是文本中的关键词,故使用TF-IDF进行关键词提取。TF-IDF权重通过计算词频和逆向文件频率来计算,这里直接利用jieba分词工具进行提取,列出50个关键词如下表所示,可以发现与谍纸天眼相关的人物主要是宇文家族,此外,还有一些比较特别的词,如谍者、谍纸楼、谍纸令、杀宗、隐宗、兵宗、银宗等,通过这些关键词我们可以比较清楚的知道有关谍纸天眼的大部分信息。例如,谍纸天眼的掌管着很可能是宇文家族,其组成部分包含杀宗、隐宗、兵宗和银宗,各部分执行不同的任务。如果想看到每个词具体的TF-IDF权重也可以利用scikit-learn包进行计算,然后再根据权重的大小进行重要性排序。
代码6:
关键字:
2.运用word2vec挖掘语义相似关系
文本分析中也经常会用到word2vec将文本转化为词向量的形式后来挖掘词语语义上的相似关系。导入gensim库后,将文本转化为模型输入的形式后进行训练,然后就可以得到每个词的向量形式。例如打印出“谍纸天眼”的向量如输出结果所示。
代码7:
根据词向量,可以比较各词的相似度,或者寻找对应关系,如:
可以看出文本中“谍纸天眼”与“宇文玥”的相似度为0.9994,而在给定“大魏”与“宇文玥”的关系后,可以发现与燕北有类似关系的词主要有燕洵等。虽然乱进了少量无特别含义的词,但并无太大影响。此外,还可以根据训练出来的词向量进行k-means聚类等等,感兴趣的朋友可以进一步的尝试。
如需下载本文代码的.py文件,请查看原文,谢谢!
文章来源:http://mp.weixin.qq.com/s/VfntJcP_VolTs7iJopiBxQ
投诉
鸣谢:感谢阅读!

相关文章推荐
- python数据分析与挖掘学习笔记(3)_小说文本数据挖掘part1
- python-框架-网页爬虫-文本处理-科学计算-可视化-机器学习-数据挖掘-深度学习
- 【Python-ML】电影评论数据集文本挖掘 -在线学习
- [置顶] 【python 走进NLP】 NLP 使用jieba分词处理文本
- python数据分析与挖掘学习笔记(3)_小说文本数据挖掘part2
- python学习教程(十二),一个文本界面下网络聊天室
- 基于Python爬虫的大众点评商家评论的文本挖掘
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器库
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
- 上传一个校内网刷人气程序(python+wxpython),供大家学习交流
- python_基础学习_03_正则替换文本(re.sub)
- python数据分析与挖掘学习笔记(7)-交通路标自动识别实战与神经网络算法
- python+gensim︱jieba分词、词袋doc2bow、TFIDF文本挖掘
- 文本挖掘与分析第五周学习笔记3--意见挖掘和情感分析
- 如何利用深度学习写诗歌(使用Python进行文本生成)
- Python 数据挖掘学习 一 结巴分词
- 想用R和Python做文本挖掘又不知如何下手?方法来了!
- python cookbook第三版学习笔记四:文本以及字符串令牌解析
- Python 文本挖掘:使用gensim进行文本相似度计算 http://rzcoding.blog.163.com/blog/static/2222810172013101895642665/