分析Linux内核创建一个新进程的过程
2017-08-30 15:28
211 查看
阅读理解task_struct数据结构
http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235
这个也就是我们操作系统所学的进程pcb,它的结构非常庞大,具体代码是从第1235行到第1664行。
这里选几个重要的结构说明
state进程状态(就绪态和运行状态都是TASK_RUNNING,它们的区别在于是否占有CPU)
pid进程id
stack进程的内核堆栈
flags进程标识符
tty_struct控制台描述
fs_struct 文件系统描述
files_struct打开的文件描述符
mm_struct内存管理的描述
signal_struct信号的描述
struct list_head tasks进程链表,是一个双向链表
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系。
分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构
Linux中创建进程一共有三个函数:
fork,创建子进程
vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。
clone,主要用于创建线程
这三个函数具体实现有所不同,但都是通过do_fork来实现进程的创建
fork函数,是众多系统调用之一,它与其他系统调用的大体过程一致,具体过程如下:
1.复制父进程的pcb——task_struct
err = arch_dup_task_struct(tsk, orig);
2.给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig);
3.修改复制过来的进程数据,比如pid,进程链表等等。
p = copy_process(clone_flags, stack_start, stack_size,child_tidptr, NULL, trace);
完成的工作
1.出错处理
2.dup_task_struct复制pcb,此时,子进程和父进程的描述符是完全相同的。
包括,数据结构值传递;创建内核堆栈,分配页面;
3.p=dup_task_struct进程指针p指向信创建的子进程
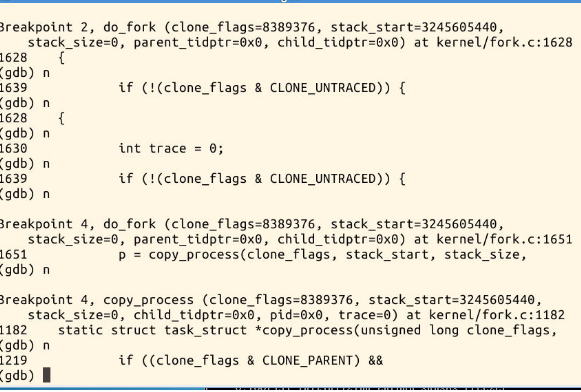
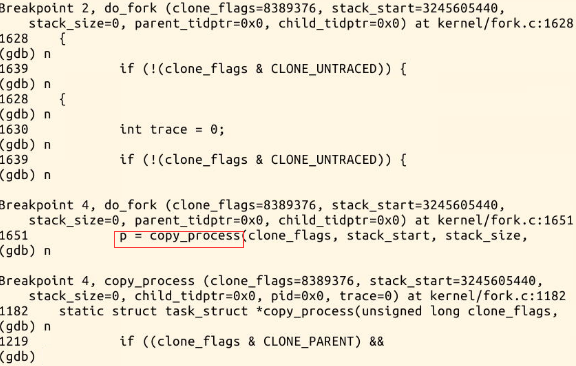
4.初始化子进程(初始化文件信息,初始化内存等,其中非常重要的:copy_thread初始化线程:找到子进程内核堆栈的地址,找到
父进程内核堆栈的地址,拷贝部分内核堆栈数据(即SAVE_ALL)和指定新进程的第一条指令地址),完成这个动作后,子进程已
经有了自己独立的ip,文件信息,内存信息,内核堆栈地址等,即已经拥有自己的进程空间
5.最后ret_from_fork,这个命令最后会跳到syscall_exit,此时系统调用结束,返回用户态。
使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone
,验证Linux系统创建一个新进程的理解,推荐在实验楼Linux虚拟机
环境下完成实验。
命令
rm menu/ -rf
git clone https://github.com/menging/menu.git cd menu
mv test_fork.c test.c
make roofts
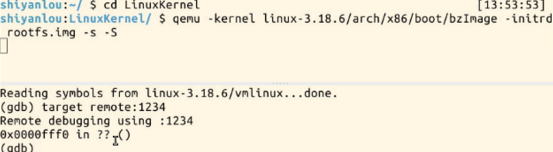
cd LinuxKernel
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.omg -s -S
gdb
file linux-3.18.6/vmlinux
target remote:1234
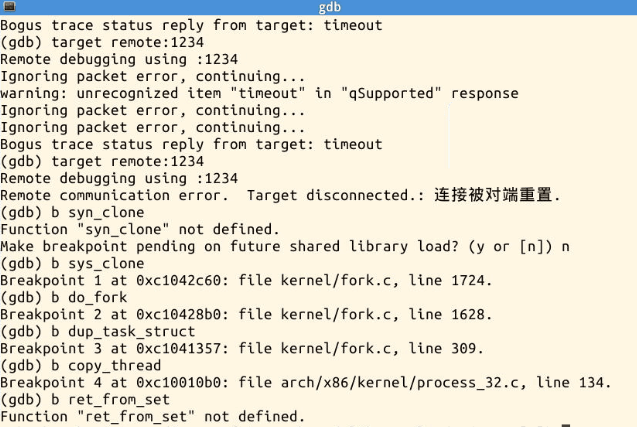
b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork

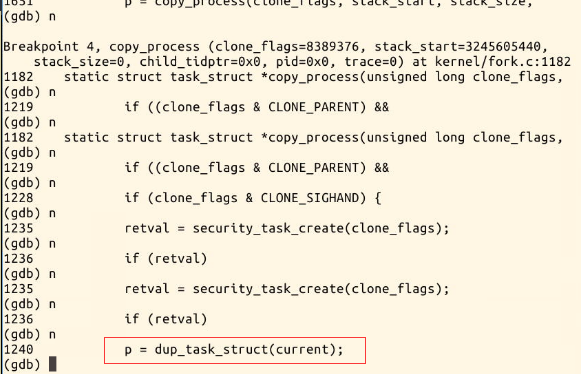
小结
1.新进程是从ret_from_fork开始执行的,因为执行到这里时,子进程已经拷贝并修改了父进程的进程空间。它是通过fork函数中的 copy_process中的copy_thread(找到父进程的内核堆栈,找到子进程的内核堆栈,拷贝父进程部分内核堆栈数据(即SAVE_ALL),
指定新进程的第一条指令地址),此时子进程已经有了自己独立的进程空间。
2.linux创建一个新进程
之前从mykernel大体知道,linux是人为创建0号进程,然后复制并修改0号进程产生1号进程等等。
学到现在,加深了许多细节的理解
首先,创建进程是通过系统调用来实现的,首先需要保护中断现场,进入中断向量,查找并执行系统调用fork:复制pcb,创建内核堆栈,分配页面,
修改pcb(包括文件信息,内存信息等等,其中特别重要的是,查找父进程和子进程的内存堆栈,复制父进程的部分内核堆栈到子进程,找到子进程的
第一条指令地址,这样以来,子进程就是一个独立的进程),最后ret_from_fork,这个命令最后会跳到syscall_exit,此时系统调用结束,中断结
束,恢复中断现场,返回用户态。
张何灿 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235
这个也就是我们操作系统所学的进程pcb,它的结构非常庞大,具体代码是从第1235行到第1664行。
这里选几个重要的结构说明
state进程状态(就绪态和运行状态都是TASK_RUNNING,它们的区别在于是否占有CPU)
pid进程id
stack进程的内核堆栈
flags进程标识符
tty_struct控制台描述
fs_struct 文件系统描述
files_struct打开的文件描述符
mm_struct内存管理的描述
signal_struct信号的描述
struct list_head tasks进程链表,是一个双向链表
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系。
分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构
Linux中创建进程一共有三个函数:
fork,创建子进程
vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。
clone,主要用于创建线程
YSCALL_DEFINE0(fork)
{return do_fork(SIGCHLD, 0,0,NULL,NULL);
}
#endif
SYSCALL_DEFINE0(vfork)
{return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0,NULL,NULL);
}S
YSCALL_DEFINE5(clone,unsignedlong, clone_flags, unsignedlong, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
{return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}这三个函数具体实现有所不同,但都是通过do_fork来实现进程的创建
fork函数,是众多系统调用之一,它与其他系统调用的大体过程一致,具体过程如下:
1.复制父进程的pcb——task_struct
err = arch_dup_task_struct(tsk, orig);
2.给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig);
3.修改复制过来的进程数据,比如pid,进程链表等等。
p = copy_process(clone_flags, stack_start, stack_size,child_tidptr, NULL, trace);
完成的工作
1.出错处理
2.dup_task_struct复制pcb,此时,子进程和父进程的描述符是完全相同的。
包括,数据结构值传递;创建内核堆栈,分配页面;
3.p=dup_task_struct进程指针p指向信创建的子进程
4.初始化子进程(初始化文件信息,初始化内存等,其中非常重要的:copy_thread初始化线程:找到子进程内核堆栈的地址,找到
父进程内核堆栈的地址,拷贝部分内核堆栈数据(即SAVE_ALL)和指定新进程的第一条指令地址),完成这个动作后,子进程已
经有了自己独立的ip,文件信息,内存信息,内核堆栈地址等,即已经拥有自己的进程空间
5.最后ret_from_fork,这个命令最后会跳到syscall_exit,此时系统调用结束,返回用户态。
使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone
,验证Linux系统创建一个新进程的理解,推荐在实验楼Linux虚拟机
环境下完成实验。
命令
rm menu/ -rf
git clone https://github.com/menging/menu.git cd menu
mv test_fork.c test.c
make roofts
cd LinuxKernel
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.omg -s -S
gdb
file linux-3.18.6/vmlinux
target remote:1234
b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
小结
1.新进程是从ret_from_fork开始执行的,因为执行到这里时,子进程已经拷贝并修改了父进程的进程空间。它是通过fork函数中的 copy_process中的copy_thread(找到父进程的内核堆栈,找到子进程的内核堆栈,拷贝父进程部分内核堆栈数据(即SAVE_ALL),
指定新进程的第一条指令地址),此时子进程已经有了自己独立的进程空间。
2.linux创建一个新进程
之前从mykernel大体知道,linux是人为创建0号进程,然后复制并修改0号进程产生1号进程等等。
学到现在,加深了许多细节的理解
首先,创建进程是通过系统调用来实现的,首先需要保护中断现场,进入中断向量,查找并执行系统调用fork:复制pcb,创建内核堆栈,分配页面,
修改pcb(包括文件信息,内存信息等等,其中特别重要的是,查找父进程和子进程的内存堆栈,复制父进程的部分内核堆栈到子进程,找到子进程的
第一条指令地址,这样以来,子进程就是一个独立的进程),最后ret_from_fork,这个命令最后会跳到syscall_exit,此时系统调用结束,中断结
束,恢复中断现场,返回用户态。
张何灿 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000

相关文章推荐
- 分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程
- Linux内核创建一个进程的过程分析
- 分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程
- 《Linux操作系统分析》之分析Linux内核创建一个新进程的过程
- 实验六:分析Linux内核创建一个新进程的过程
- Linux内核分析6:分析Linux内核创建一个新进程的过程
- 实验六:分析Linux内核创建一个新进程的过程
- 作业六:分析Linux内核创建一个新进程的过程
- 第六周——分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程
- Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
- Linux内核设计第六周学习总结 分析Linux内核创建一个新进程的过程
- linux内核分析第六周-分析Linux内核创建一个新进程的过程
- [转载] 分析Linux内核创建一个新进程的过程
- 分析Linux内核创建一个新进程的过程