MySQL 索引优化查询(一)
2017-08-30 11:30
651 查看
索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点。考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录。如果没有索引,查询将对整个表进行扫描,最坏的情况下,如果所有数据页都不在内存,需要读取10^4个页面,如果这10^4个页面在磁盘上随机分布,需要进行10^4次I/O,假设磁盘每次I/O时间为10ms(忽略数据传输时间),则总共需要100s(但实际上要好很多很多)。如果对之建立B-Tree索引,则只需要进行log100(10^6)=3次页面读取,最坏情况下耗时30ms。这就是索引带来的效果,很多时候,当你的应用程序进行SQL查询速度很慢时,应该想想是否可以建索引。进入正题:
索引与优化
1、选择索引的数据类型
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
(1)越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2)简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3)尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
1.1、选择标识符
选择合适的标识符是非常重要的。选择时不仅应该考虑存储类型,而且应该考虑MySQL是怎样进行运算和比较的。一旦选定数据类型,应该保证所有相关的表都使用相同的数据类型。
(1) 整型:通常是作为标识符的最好选择,因为可以更快的处理,而且可以设置为AUTO_INCREMENT。
(2) 字符串:尽量避免使用字符串作为标识符,它们消耗更好的空间,处理起来也较慢。而且,通常来说,字符串都是随机的,所以它们在索引中的位置也是随机的,这会导致页面分裂、随机访问磁盘,聚簇索引分裂(对于使用聚簇索引的存储引擎)。
2、索引入门
对于任何DBMS,索引都是进行优化的最主要的因素。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。例如:
假设存在组合索引it1c1c2(c1,c2),查询语句select * from t1 where c1=1 and c2=2能够使用该索引。查询语句select * from t1 where c1=1也能够使用该索引。但是,查询语句select * from t1 where c2=2不能够使用该索引,因为没有组合索引的引导列,即,要想使用c2列进行查找,必需出现c1等于某值。
2.1、索引的类型
索引是在存储引擎中实现的,而不是在服务器层中实现的。所以,每种存储引擎的索引都不一定完全相同,并不是所有的存储引擎都支持所有的索引类型。
2.1.1、B-Tree索引
假设有如下一个表:
其索引包含表中每一行的last_name、first_name和dob列。其结构大致如下:
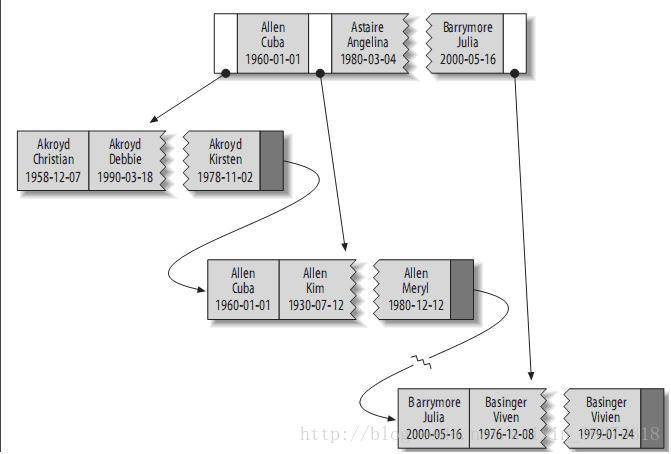
索引存储的值按索引列中的顺序排列。可以利用B-Tree索引进行全关键字、关键字范围和关键字前缀查询,当然,如果想使用索引,你必须保证按索引的最左边前缀(leftmost prefix of the index)来进行查询。
(1)匹配全值(Match the full value):对索引中的所有列都指定具体的值。例如,上图中索引可以帮助你查找出生于1960-01-01的Cuba Allen。
(2)匹配最左前缀(Match a leftmost prefix):你可以利用索引查找last name为Allen的人,仅仅使用索引中的第1列。
(3)匹配列前缀(Match a column prefix):例如,你可以利用索引查找last name以J开始的人,这仅仅使用索引中的第1列。
(4)匹配值的范围查询(Match a range of values):可以利用索引查找last name在Allen和Barrymore之间的人,仅仅使用索引中第1列。
(5)匹配部分精确而其它部分进行范围匹配(Match one part exactly and match a range on another part):可以利用索引查找last name为Allen,而first name以字母K开始的人。
(6)仅对索引进行查询(Index-only queries):如果查询的列都位于索引中,则不需要读取元组的值。
由于B-树中的节点都是顺序存储的,所以可以利用索引进行查找(找某些值),也可以对查询结果进行ORDER BY。当然,使用B-tree索引有以下一些限制:
(1) 查询必须从索引的最左边的列开始。关于这点已经提了很多遍了。例如你不能利用索引查找在某一天出生的人。
(2) 不能跳过某一索引列。例如,你不能利用索引查找last name为Smith且出生于某一天的人。
(3) 存储引擎不能使用索引中范围条件右边的列。例如,如果你的查询语句为WHERE last_name=”Smith” AND first_name LIKE ‘J%’ AND dob=’1976-12-23’,则该查询只会使用索引中的前两列,因为LIKE是范围查询。
2.1.2、Hash索引
MySQL中,只有Memory存储引擎显示支持hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B-Tree索引。Memory存储引擎支持非唯一hash索引,这在数据库领域是罕见的,如果多个值有相同的hash code,索引把它们的行指针用链表保存到同一个hash表项中。
假设创建如下一个表:
包含的数据如下:
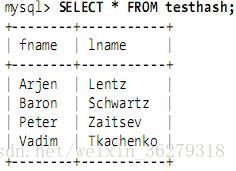
假设索引使用hash函数f( ),如下:
此时,索引的结构大概如下:

Slots是有序的,但是记录不是有序的。当你执行## 标题 ##
MySQL会计算’Peter’的hash值,然后通过它来查询索引的行指针。因为f(‘Peter’) = 8784,MySQL会在索引中查找8784,得到指向记录3的指针。
因为索引自己仅仅存储很短的值,所以,索引非常紧凑。Hash值不取决于列的数据类型,一个TINYINT列的索引与一个长字符串列的索引一样大。
Hash索引有以下一些限制:
(1)由于索引仅包含hash code和记录指针,所以,MySQL不能通过使用索引避免读取记录。但是访问内存中的记录是非常迅速的,不会对性造成太大的影响。
(2)不能使用hash索引排序。
(3)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(4)Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询。
2.1.3、空间(R-Tree)索引
MyISAM支持空间索引,主要用于地理空间数据类型,例如GEOMETRY。
2.1.4、全文(Full-text)索引
全文索引是MyISAM的一个特殊索引类型,主要用于全文检索。
3、高性能的索引策略
3.1、聚簇索引(Clustered Indexes)
聚簇索引保证关键字的值相近的元组存储的物理位置也相同(所以字符串类型不宜建立聚簇索引,特别是随机字符串,会使得系统进行大量的移动操作),且一个表只能有一个聚簇索引。因为由存储引擎实现索引,所以,并不是所有的引擎都支持聚簇索引。目前,只有solidDB和InnoDB支持。
聚簇索引的结构大致如下:
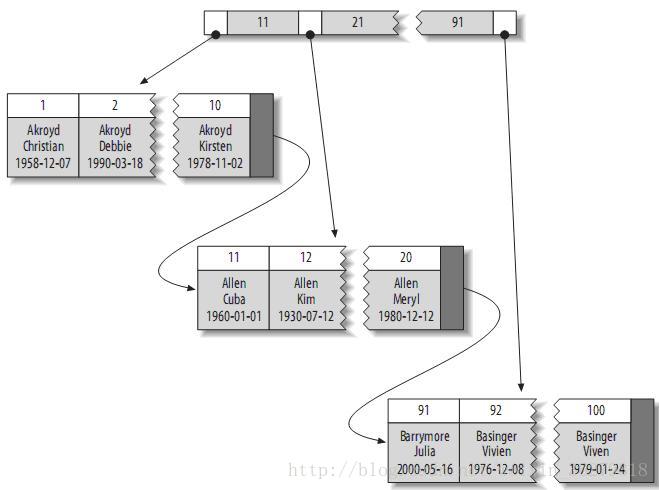
注:叶子页面包含完整的元组,而内节点页面仅包含索引的列(索引的列为整型)。一些DBMS允许用户指定聚簇索引,但是MySQL的存储引擎到目前为止都不支持。InnoDB对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。
索引与优化
1、选择索引的数据类型
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
(1)越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2)简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3)尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
1.1、选择标识符
选择合适的标识符是非常重要的。选择时不仅应该考虑存储类型,而且应该考虑MySQL是怎样进行运算和比较的。一旦选定数据类型,应该保证所有相关的表都使用相同的数据类型。
(1) 整型:通常是作为标识符的最好选择,因为可以更快的处理,而且可以设置为AUTO_INCREMENT。
(2) 字符串:尽量避免使用字符串作为标识符,它们消耗更好的空间,处理起来也较慢。而且,通常来说,字符串都是随机的,所以它们在索引中的位置也是随机的,这会导致页面分裂、随机访问磁盘,聚簇索引分裂(对于使用聚簇索引的存储引擎)。
2、索引入门
对于任何DBMS,索引都是进行优化的最主要的因素。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。例如:
假设存在组合索引it1c1c2(c1,c2),查询语句select * from t1 where c1=1 and c2=2能够使用该索引。查询语句select * from t1 where c1=1也能够使用该索引。但是,查询语句select * from t1 where c2=2不能够使用该索引,因为没有组合索引的引导列,即,要想使用c2列进行查找,必需出现c1等于某值。
2.1、索引的类型
索引是在存储引擎中实现的,而不是在服务器层中实现的。所以,每种存储引擎的索引都不一定完全相同,并不是所有的存储引擎都支持所有的索引类型。
2.1.1、B-Tree索引
假设有如下一个表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f') not null,
key(last_name, first_name, dob)
);其索引包含表中每一行的last_name、first_name和dob列。其结构大致如下:
索引存储的值按索引列中的顺序排列。可以利用B-Tree索引进行全关键字、关键字范围和关键字前缀查询,当然,如果想使用索引,你必须保证按索引的最左边前缀(leftmost prefix of the index)来进行查询。
(1)匹配全值(Match the full value):对索引中的所有列都指定具体的值。例如,上图中索引可以帮助你查找出生于1960-01-01的Cuba Allen。
(2)匹配最左前缀(Match a leftmost prefix):你可以利用索引查找last name为Allen的人,仅仅使用索引中的第1列。
(3)匹配列前缀(Match a column prefix):例如,你可以利用索引查找last name以J开始的人,这仅仅使用索引中的第1列。
(4)匹配值的范围查询(Match a range of values):可以利用索引查找last name在Allen和Barrymore之间的人,仅仅使用索引中第1列。
(5)匹配部分精确而其它部分进行范围匹配(Match one part exactly and match a range on another part):可以利用索引查找last name为Allen,而first name以字母K开始的人。
(6)仅对索引进行查询(Index-only queries):如果查询的列都位于索引中,则不需要读取元组的值。
由于B-树中的节点都是顺序存储的,所以可以利用索引进行查找(找某些值),也可以对查询结果进行ORDER BY。当然,使用B-tree索引有以下一些限制:
(1) 查询必须从索引的最左边的列开始。关于这点已经提了很多遍了。例如你不能利用索引查找在某一天出生的人。
(2) 不能跳过某一索引列。例如,你不能利用索引查找last name为Smith且出生于某一天的人。
(3) 存储引擎不能使用索引中范围条件右边的列。例如,如果你的查询语句为WHERE last_name=”Smith” AND first_name LIKE ‘J%’ AND dob=’1976-12-23’,则该查询只会使用索引中的前两列,因为LIKE是范围查询。
2.1.2、Hash索引
MySQL中,只有Memory存储引擎显示支持hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B-Tree索引。Memory存储引擎支持非唯一hash索引,这在数据库领域是罕见的,如果多个值有相同的hash code,索引把它们的行指针用链表保存到同一个hash表项中。
假设创建如下一个表:
CREATE TABLE testhash ( fname VARCHAR(50) NOT NULL, lname VARCHAR(50) NOT NULL, KEY USING HASH(fname) ) ENGINE=MEMORY;
包含的数据如下:
假设索引使用hash函数f( ),如下:
f('Arjen') = 2323
f('Baron') = 7437
f('Peter') = 8784
f('Vadim') = 2458此时,索引的结构大概如下:
Slots是有序的,但是记录不是有序的。当你执行## 标题 ##
mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQL会计算’Peter’的hash值,然后通过它来查询索引的行指针。因为f(‘Peter’) = 8784,MySQL会在索引中查找8784,得到指向记录3的指针。
因为索引自己仅仅存储很短的值,所以,索引非常紧凑。Hash值不取决于列的数据类型,一个TINYINT列的索引与一个长字符串列的索引一样大。
Hash索引有以下一些限制:
(1)由于索引仅包含hash code和记录指针,所以,MySQL不能通过使用索引避免读取记录。但是访问内存中的记录是非常迅速的,不会对性造成太大的影响。
(2)不能使用hash索引排序。
(3)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(4)Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询。
2.1.3、空间(R-Tree)索引
MyISAM支持空间索引,主要用于地理空间数据类型,例如GEOMETRY。
2.1.4、全文(Full-text)索引
全文索引是MyISAM的一个特殊索引类型,主要用于全文检索。
3、高性能的索引策略
3.1、聚簇索引(Clustered Indexes)
聚簇索引保证关键字的值相近的元组存储的物理位置也相同(所以字符串类型不宜建立聚簇索引,特别是随机字符串,会使得系统进行大量的移动操作),且一个表只能有一个聚簇索引。因为由存储引擎实现索引,所以,并不是所有的引擎都支持聚簇索引。目前,只有solidDB和InnoDB支持。
聚簇索引的结构大致如下:
注:叶子页面包含完整的元组,而内节点页面仅包含索引的列(索引的列为整型)。一些DBMS允许用户指定聚簇索引,但是MySQL的存储引擎到目前为止都不支持。InnoDB对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。

相关文章推荐
- mysql性能优化-慢查询分析、优化索引和配置
- mysql千万级数据量根据索引优化查询速度
- MySQL 查询 索引 优化
- MySQL索引原理及慢查询优化
- MySQL索引原理及慢查询优化(重要)
- mysql查询索引优化
- 提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
- mysql性能优化-慢查询分析、优化索引和配置
- mysql索引和查询优化
- MySQL索引原理与慢查询优化
- 提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
- mysql 索引原理及慢查询优化
- mysql性能优化-慢查询分析、优化索引和配置
- MySQL索引及查询优化总结 专题
- mysql查询、索引、配置优化
- MySQL 性能优化 : 索引和查询优化
- 通过建立索引优化MySQL查询速度
- mysql性能优化二慢查询分析、优化索引和配置
- MySQL索引原理及慢查询优化
- mysql性能优化-慢查询分析、优化索引和配置