读书笔记《机器学习》: 第四章:决策树
2017-08-30 09:59
197 查看
4.1 基本流程
4.2 划分选择
4.3 剪枝处理
4.4 连续与缺失值
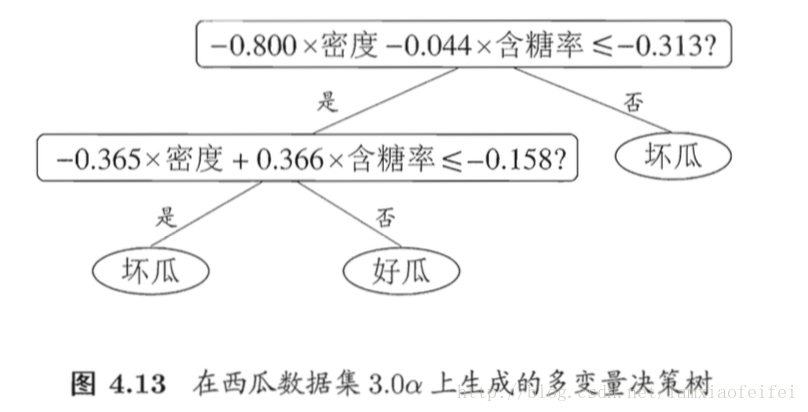
4.5 多变量决策树
决策树的生成是一个递归过程。其终止条件主要有三个:
1.当前节点所包含的样本全部属于同一类别,无法划分
2.当前属性集为空,或是所有样本在所有属性的取值相同,无法划分,直接把该节点的类别设定为所含样本做多的类别。
3.当前节点所包含的样本集合为空,不能划分,其类别直接设定为其父节点所含样本最多的类别。
总体原则:使得划分后分支节点的纯度越来越高。
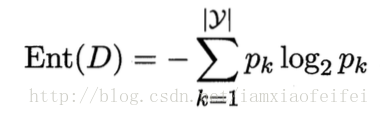
Ent(D)越小,纯度越高。
信息增益(information gain):
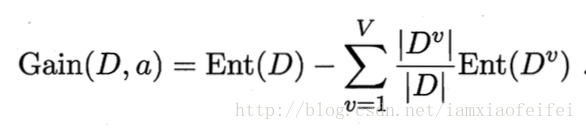
信息增益越大,则使用此特征划分获得的纯度提升越大。
ID3算法以信息增益为准则划分属性。
C4.5算法使用增益率(gain ratio)选择最优属性。
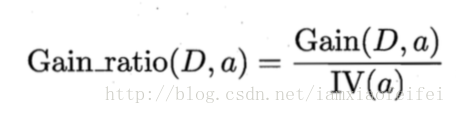
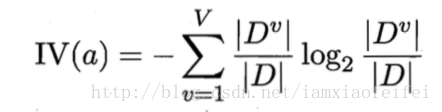
IV(a)称为特征a的固有值(intrinsic value),一般特征取值数目越多,IV越大。
但增益率对取值数目较少的特征有所偏好。实际上的C4.5先从划分属性中找出信息增益高出平均水平的特征,再从里面选择增益率最高的。

Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。基尼指数越小,纯度越高。
特征a的基尼指数:
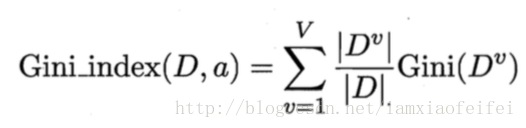
预剪枝:对每个节点划分前进行估计,如果当前节点划分不能带来决策树泛化性能的提升,则停止划分并将该节点设置为叶节点。
后剪枝:先生成一颗完整的决策树,然后自底向上对非叶节点考察,如果该节点对应的子树替换为叶节点能带来泛化性能的提升,则剪枝将该子树替换成叶节点。
如何判断泛化性能是否提升?
可以使用验证集。
后剪枝欠拟合风险小,但计算开销大。
C4.5算法使用二分法。
1.如何在特征缺失值得情况下选择最优划分属性?
使用没有缺失值的样本子集来评估(如计算信息增益)
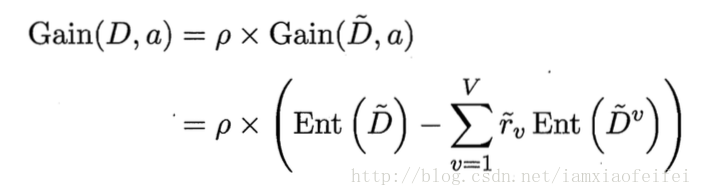
其实就是在信息增益(基于非缺失值计算的信息增益)的前面添加了一个比例系数(非缺失值所占的比例)。
2.给定划分特征,如果样本的这个特征值缺失,如何对它进行划分?
将样本以不同的概率划入到不同的子节点中。
不再寻找最优划分特征,而是为每一个非叶节点建立一个线性分类器。
4.2 划分选择
4.3 剪枝处理
4.4 连续与缺失值
4.5 多变量决策树
4.1 基本流程
决策树的流程遵循简单且直观的分而治之的策略。决策树的生成是一个递归过程。其终止条件主要有三个:
1.当前节点所包含的样本全部属于同一类别,无法划分
2.当前属性集为空,或是所有样本在所有属性的取值相同,无法划分,直接把该节点的类别设定为所含样本做多的类别。
3.当前节点所包含的样本集合为空,不能划分,其类别直接设定为其父节点所含样本最多的类别。
4.2 划分选择
如何选择最优划分特征是决策树学习的关键。总体原则:使得划分后分支节点的纯度越来越高。
4.2.1 信息增益
信息熵(information entropy):度量纯度的最常用的一种治标。Ent(D)越小,纯度越高。
信息增益(information gain):
信息增益越大,则使用此特征划分获得的纯度提升越大。
ID3算法以信息增益为准则划分属性。
4.2.2 增益率
信息增益(ID3)对取值较多的特征有所偏好。C4.5算法使用增益率(gain ratio)选择最优属性。
IV(a)称为特征a的固有值(intrinsic value),一般特征取值数目越多,IV越大。
但增益率对取值数目较少的特征有所偏好。实际上的C4.5先从划分属性中找出信息增益高出平均水平的特征,再从里面选择增益率最高的。
4.2.3 基尼指数
CART决策树使用基尼指数(Gini index)划分属性,选择划分后基尼指数最小的那个属性。Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。基尼指数越小,纯度越高。
特征a的基尼指数:
4.3 剪枝处理
剪枝包括预剪枝(prepruning)和后剪枝(postpruning)。预剪枝:对每个节点划分前进行估计,如果当前节点划分不能带来决策树泛化性能的提升,则停止划分并将该节点设置为叶节点。
后剪枝:先生成一颗完整的决策树,然后自底向上对非叶节点考察,如果该节点对应的子树替换为叶节点能带来泛化性能的提升,则剪枝将该子树替换成叶节点。
如何判断泛化性能是否提升?
可以使用验证集。
后剪枝欠拟合风险小,但计算开销大。
4.4 连续与缺失值
4.4.1 特征取值是连续的如何处理?
连续属性离散化技术C4.5算法使用二分法。
4.4.2 缺失值如何处理?
主要有两个问题:1.如何在特征缺失值得情况下选择最优划分属性?
使用没有缺失值的样本子集来评估(如计算信息增益)
其实就是在信息增益(基于非缺失值计算的信息增益)的前面添加了一个比例系数(非缺失值所占的比例)。
2.给定划分特征,如果样本的这个特征值缺失,如何对它进行划分?
将样本以不同的概率划入到不同的子节点中。
4.5 多变量决策树
多变量决策树(也称斜决策树)能实现斜划分,甚至更复杂划分。不再针对单个特征,而是针对特征的线性组合。不再寻找最优划分特征,而是为每一个非叶节点建立一个线性分类器。

相关文章推荐
- 《机器学习》读书笔记 6 第4章 决策树
- 小白学习机器学习---第四章:决策树
- 机器学习(周志华) 参考答案 第四章 决策树 4.10
- 《机器学习:算法原理与编程实践》的读书笔记:SMO部分最难,大部分代码基于Scikit-Learn,决策树其实用处不大
- 小白学习机器学习---第四章:决策树(2)
- 机器学习实战第三章——决策树,读书笔记
- 周志华 《机器学习》之 第四章(决策树)概念总结
- 机器学习实战---读书笔记: 第3章 决策树
- 机器学习(周志华)_第四章 决策树
- 机器学习实战——决策树(读书笔记)
- 机器学习(周志华) 参考答案 第四章 决策树 4.5
- 机器学习(周志华)读书笔记-(四)决策树
- 机器学习(周志华) 参考答案 第四章 决策树 4.4
- 【读书笔记】机器学习实战-决策树(1)
- 【读书笔记】机器学习实战-决策树(2)
- 第四章 决策树——机器学习(周志华)课后答案
- 《统计学习方法》读书笔记-----决策树:ID3,C4.5生成算法和剪枝
- 《C#入门经典(第6版)》读书笔记4_第四章:流程控制
- 《统计学习方法》读书笔记-----决策树:CART算法
- 用Python开始机器学习(2:决策树分类算法)