python3爬虫简单小实例1.0
2017-08-27 12:14
183 查看
相关用法:
find_all:find_all
find_next:find_next
strip() 方法用于移除字符串头尾指定的字符(默认为空格)。
目的:获取书名和价格
爬取网站地址:https://www.packtpub.com/all

书名在
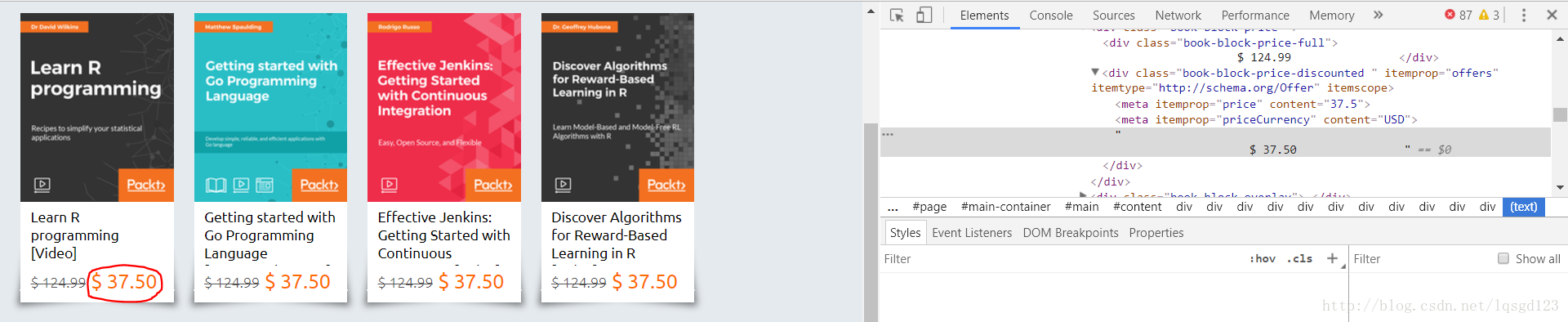
书的价格独立于如何标签之外,无法直接通过
代码:
结果:

find_all:find_all
find_next:find_next
strip() 方法用于移除字符串头尾指定的字符(默认为空格)。
目的:获取书名和价格
爬取网站地址:https://www.packtpub.com/all
一、书名
书名在
<div class="book-block-title" itemprop="name">的标签中,使用find_all找到所有匹配结果出现的地方,通过
<tag>.string找到标签内的字符串。
二、价格
书的价格独立于如何标签之外,无法直接通过
<tag>.string找到标签内的字符串,需要用到正则表达式。
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 26 17:28:21 2017
@author: 81294
"""
import urllib
import datetime
from bs4 import BeautifulSoup
import re
starttime = datetime.datetime.now()
url = "https://www.packtpub.com/all"
page = urllib.request.urlopen(url)
soup_packtpage = BeautifulSoup(page,'html.parser')
page.close()
endtime = datetime.datetime.now()
print(endtime - starttime)
starttime = datetime.datetime.now()
all_book_title = soup_packtpage.find_all("div", class_="book-block-title")
all_book_price = soup_packtpage.find_all("div", class_="book-block-price-discounted ")
a = []
b = []
all_book_prices = re.compile(u"\s+.\s+\d+.\d+")
for book_title in all_book_title:
c = book_title.string.strip()
a.append(c)
for book_price in all_book_price:
book_prices = book_price.find_next(text=all_book_prices)
d= book_prices.strip().replace(' ' ,'')
b.append(d)
for book in range(len(a)):
print("The price of " '《' '{0}' '》' " is " '{1}' .format(a[book],b[book]))
endtime = datetime.datetime.now()
print(endtime - starttime)结果:

相关文章推荐
- python3爬虫简单小实例2.0
- python 简单备份文件脚本v1.0的实例
- Python简单介绍,单向链表实例
- python 编写简单网页服务器的实例
- python+pygame简单画板实现代码实例
- python的bs的简单实例爬取58同城手机信息
- python妹子图简单爬虫实例
- Python3简单实例计算同花的概率代码
- python 实现红包随机生成算法的简单实例
- 工位上的Python――一个简单的UDP广播实例
- Golang与python线程详解及简单实例
- 简单Python3爬虫程序(1)简单架构:队列、集合、正则
- Python入门之requests库的安装与简单使用实例
- python之多线程简单实例
- Python Tkinter简单布局实例教程
- 使用Python编写简单的端口扫描器的实例分享
- Python实现的简单hangman游戏实例
- Python3中简单的文件操作及两个简单小实例分享
- 一个简单的Python3爬虫获取两城市间铁路距离程序
- python使用线程封装的一个简单定时器类实例