Android开发之使用PULL解析和生成XML
2017-08-24 18:17
696 查看
Android开发之使用PULL解析和生成XML
请尊重他人的劳动成果,转载请注明出处:Android开发之使用PULL解析和生成XML
Pull解析器的运行方式与SAX解析器相似。它提供了类似的事件,如开始元素和结束元素事件。使用parser.next()可以进入下一个元素并触发相应事件。事件将作为数值代码被发送,因此可以使用一个switch对感兴趣的事件进行选择,然后进行相应处理。当元素开始解析时,调用parser.nextText()方法可以获取下一个Text类型元素的值。
(2)简单易用:Pull解析器只有一个重要的方法next(),它被用来检索下一个事件。而它的事件也仅仅只有5个。
Ø START DOCUMENT;
Ø START_TAG;
Ø TEXT;
Ø END_TAG;
Ø END_DOCUMENT。
(3)多功能性:通用的XML解析器和多种实现,并具有可扩展性。
(4)最小的需求:为了与JavaME兼容和在小型设备上运作而设计,并允许创建占用非常小的内存的XMLPULL解析器。
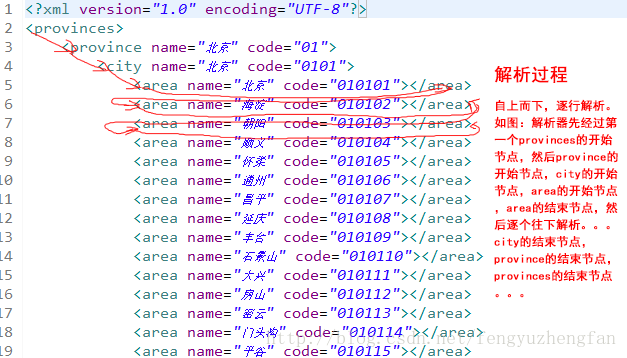
看到这里,读者应该明白,为什么Pull解析器会被集成Android里了吧。并且Pull解析器,也可以用在JavaEE等非Android项目中,不一定只拘泥于Android的开发。下面我们通过一个示例来理解一下Pull解析的过程吧。
[java] view plain copy print?public static List<Person> getPersons(InputStream inStream) throws Exception{
Person person = null;
List<Person> persons = null;
XmlPullParser pullParser = Xml.newPullParser();
pullParser.setInput(inStream, ”UTF-8”);
4000
int event = pullParser.getEventType();//触发第一个事件
while(event!=XmlPullParser.END_DOCUMENT){
switch (event) {
case XmlPullParser.START_DOCUMENT:
persons = new ArrayList<Person>();
break;
case XmlPullParser.START_TAG:
if(“person”.equals(pullParser.getName())){
int id = new Integer(pullParser.getAttributeValue(0));
person = new Person();
person.setId(id);
}
if(person!=null){
if(“name”.equals(pullParser.getName())){
person.setName(pullParser.nextText());
}
if(“age”.equals(pullParser.getName())){
person.setAge(new Short(pullParser.nextText()));
}
}
break;
case XmlPullParser.END_TAG:
if(“person”.equals(pullParser.getName())){
persons.add(person);
person = null;
}
break;
}
event = pullParser.next();
}
return persons;
}
代码说明:
1)int event =pullParser.getEventType();是Pull解析器的第一个事件。读者可以看到,这个方法的返回值是int类型的,这就是前面所提到的Pull解析器返回的是一个数字,类似于一个信号。那么这些信号都代表什么意思呢?
Pull解析器已经定义了这五个常量,而且对于事件,仅仅只有这5个,如下:
• XmlPullParser.START_DOCUMENT
(开始解析,只执行一次);
• XmlPullParser.START_TAG
(开始元素);
• XmlPullParser.TEXT
(解析文本);
• XmlPullParser
END_TAG (结束元素);
• XmlPullParser
END_DOCUMENT (结束解析,只执行一次)。
2 )“parser.getEventType()”触发了第一个事件,根据XML的语法,也就是从它开始了解析文档。那么,怎么样触发下一个事件呢?要通过Parser中最重要的方法:
parser.next();
注意:该方法是有返回值的,在Pull触发下—个事件的同时,也获得该事件的“信号”。通过获得的信号进行switch操作。
3)“parsergetAttribiiteValue()”获得相应属性的值。它有两种形式,可以通过属性的索引,也可以通过(命名空间,属性名)进行索引。
XmlSerializer serializer = Xml.newSerializer();
serializer.setOutput(outStream, ”UTF-8”);
serializer.startDocument(”UTF-8”, true);
serializer.startTag(null, “persons”);
for(Person person : persons){
serializer.startTag(null, “person”);
serializer.attribute(null, “id”, person.getId().toString());
serializer.startTag(null, “name”);
serializer.text(person.getName());
serializer.endTag(null, “name”);
serializer.startTag(null, “age”);
serializer.text(person.getAge().toString());
serializer.endTag(null, “age”);
serializer.endTag(null, “person”);
}
serializer.endTag(null, “persons”);
serializer.endDocument();
outStream.flush();
outStream.close();
}
说明:
(1 ) “XmlSerializCTserializer= Xml.newSerializer()”定义了一个接口来实现
XML信息的串行化。那串行化又是什么呢?其也叫做对象的序列化,并不仅仅是简单地把对象保存在存储器上,它还可以使我们以二进制方式通过网络传输对象,使对象变得可以像基本数据一样传递。之后可以通过反串行化从这些连续的字节(byte)数据重新构建一个与原始对象状态相同的对象。
(2)定义一个方法,第一个参数是要生成XML文件的内容,第二个参教是一个写入器。 Write
(写入器)接口要比输出流更加灵活。它可以向更多的媒介进行榆出,比如向硬盘、内存、网络等进行输出。“new”一个持久化的XML对象。在这里,应该明白为什么要持久化,说白了就是一种写入硬盘的行为。
serializer.setOutput(writer);
设置了输出的方向。它接收两种类型的输出,分别是输出流和写入器。这点用到了刚才向读者介绍的writer写入器。
(3)XML中标签的成对出现,有开始,必有结束。所以在写入一个satrtTag()时,笔者习惯紧跟着写入与之相对应的endTag()。这样不至于在复杂的生成结构时,弄错了XML生成结构。
方法说明:第一个參数是XML的命名空间,第二个是标签名,endTag()相同。
请尊重他人的劳动成果,转载请注明出处:Android开发之使用PULL解析和生成XML
一、使用PULL解析XML
1.PULL简介
我曾在《浅谈XMl解析的几种方式》一文中介绍了使用DOM方式,SAX方式,Jdom方式,以及dom4j的方式来解析XML。除了可以使用以上方式来解析XML文件外,也可以使用android系统内置的Pull解析器来解析XML文件。Pull解析器的运行方式与SAX解析器相似。它提供了类似的事件,如开始元素和结束元素事件。使用parser.next()可以进入下一个元素并触发相应事件。事件将作为数值代码被发送,因此可以使用一个switch对感兴趣的事件进行选择,然后进行相应处理。当元素开始解析时,调用parser.nextText()方法可以获取下一个Text类型元素的值。
2. 特点
(1)简单的结构:一个接口,一个例外,一个工厂组成了 Pull解析器。(2)简单易用:Pull解析器只有一个重要的方法next(),它被用来检索下一个事件。而它的事件也仅仅只有5个。
Ø START DOCUMENT;
Ø START_TAG;
Ø TEXT;
Ø END_TAG;
Ø END_DOCUMENT。
(3)多功能性:通用的XML解析器和多种实现,并具有可扩展性。
(4)最小的需求:为了与JavaME兼容和在小型设备上运作而设计,并允许创建占用非常小的内存的XMLPULL解析器。
3. 工作原理
解析XML内容的方式与SAX是相似的,同样包括开始元素和结束元素事件,使用parser.next()可以进入下一个元素并触发相应事件。但是它们不同的是,SAX的事件驱动是回调相应方法,需要提供回调的方法,而后在SAX内部自动调用相应的方法。而Pull解析器并没有强制要求提供触发的方法。因为它触发的事件并不是一个方法,而是一个数字。至于触发的事件要不要处理,由程序员自己决定。看到这里,读者应该明白,为什么Pull解析器会被集成Android里了吧。并且Pull解析器,也可以用在JavaEE等非Android项目中,不一定只拘泥于Android的开发。下面我们通过一个示例来理解一下Pull解析的过程吧。
[java] view plain copy print?public static List<Person> getPersons(InputStream inStream) throws Exception{
Person person = null;
List<Person> persons = null;
XmlPullParser pullParser = Xml.newPullParser();
pullParser.setInput(inStream, ”UTF-8”);
4000
int event = pullParser.getEventType();//触发第一个事件
while(event!=XmlPullParser.END_DOCUMENT){
switch (event) {
case XmlPullParser.START_DOCUMENT:
persons = new ArrayList<Person>();
break;
case XmlPullParser.START_TAG:
if(“person”.equals(pullParser.getName())){
int id = new Integer(pullParser.getAttributeValue(0));
person = new Person();
person.setId(id);
}
if(person!=null){
if(“name”.equals(pullParser.getName())){
person.setName(pullParser.nextText());
}
if(“age”.equals(pullParser.getName())){
person.setAge(new Short(pullParser.nextText()));
}
}
break;
case XmlPullParser.END_TAG:
if(“person”.equals(pullParser.getName())){
persons.add(person);
person = null;
}
break;
}
event = pullParser.next();
}
return persons;
}
public static List<Person> getPersons(InputStream inStream) throws Exception{
Person person = null;
List<Person> persons = null;
XmlPullParser pullParser = Xml.newPullParser();
pullParser.setInput(inStream, "UTF-8");
int event = pullParser.getEventType();//触发第一个事件
while(event!=XmlPullParser.END_DOCUMENT){
switch (event) {
case XmlPullParser.START_DOCUMENT:
persons = new ArrayList<Person>();
break;
case XmlPullParser.START_TAG:
if("person".equals(pullParser.getName())){
int id = new Integer(pullParser.getAttributeValue(0));
person = new Person();
person.setId(id);
}
if(person!=null){
if("name".equals(pullParser.getName())){
person.setName(pullParser.nextText());
}
if("age".equals(pullParser.getName())){
person.setAge(new Short(pullParser.nextText()));
}
}
break;
case XmlPullParser.END_TAG:
if("person".equals(pullParser.getName())){
persons.add(person);
person = null;
}
break;
}
event = pullParser.next();
}
return persons;
}代码说明:
1)int event =pullParser.getEventType();是Pull解析器的第一个事件。读者可以看到,这个方法的返回值是int类型的,这就是前面所提到的Pull解析器返回的是一个数字,类似于一个信号。那么这些信号都代表什么意思呢?
Pull解析器已经定义了这五个常量,而且对于事件,仅仅只有这5个,如下:
• XmlPullParser.START_DOCUMENT
(开始解析,只执行一次);
• XmlPullParser.START_TAG
(开始元素);
• XmlPullParser.TEXT
(解析文本);
• XmlPullParser
END_TAG (结束元素);
• XmlPullParser
END_DOCUMENT (结束解析,只执行一次)。
2 )“parser.getEventType()”触发了第一个事件,根据XML的语法,也就是从它开始了解析文档。那么,怎么样触发下一个事件呢?要通过Parser中最重要的方法:
parser.next();
注意:该方法是有返回值的,在Pull触发下—个事件的同时,也获得该事件的“信号”。通过获得的信号进行switch操作。
3)“parsergetAttribiiteValue()”获得相应属性的值。它有两种形式,可以通过属性的索引,也可以通过(命名空间,属性名)进行索引。
二、使用PULL生成XML
[java] view plain copy print?public static void save(List<Person> persons, OutputStream outStream) throws Exception{XmlSerializer serializer = Xml.newSerializer();
serializer.setOutput(outStream, ”UTF-8”);
serializer.startDocument(”UTF-8”, true);
serializer.startTag(null, “persons”);
for(Person person : persons){
serializer.startTag(null, “person”);
serializer.attribute(null, “id”, person.getId().toString());
serializer.startTag(null, “name”);
serializer.text(person.getName());
serializer.endTag(null, “name”);
serializer.startTag(null, “age”);
serializer.text(person.getAge().toString());
serializer.endTag(null, “age”);
serializer.endTag(null, “person”);
}
serializer.endTag(null, “persons”);
serializer.endDocument();
outStream.flush();
outStream.close();
}
public static void save(List<Person> persons, OutputStream outStream) throws Exception{
XmlSerializer serializer = Xml.newSerializer();
serializer.setOutput(outStream, "UTF-8");
serializer.startDocument("UTF-8", true);
serializer.startTag(null, "persons");
for(Person person : persons){
serializer.startTag(null, "person");
serializer.attribute(null, "id", person.getId().toString());
serializer.startTag(null, "name");
serializer.text(person.getName());
serializer.endTag(null, "name");
serializer.startTag(null, "age");
serializer.text(person.getAge().toString());
serializer.endTag(null, "age");
serializer.endTag(null, "person");
}
serializer.endTag(null, "persons");
serializer.endDocument();
outStream.flush();
outStream.close();
}说明:
(1 ) “XmlSerializCTserializer= Xml.newSerializer()”定义了一个接口来实现
XML信息的串行化。那串行化又是什么呢?其也叫做对象的序列化,并不仅仅是简单地把对象保存在存储器上,它还可以使我们以二进制方式通过网络传输对象,使对象变得可以像基本数据一样传递。之后可以通过反串行化从这些连续的字节(byte)数据重新构建一个与原始对象状态相同的对象。
(2)定义一个方法,第一个参数是要生成XML文件的内容,第二个参教是一个写入器。 Write
(写入器)接口要比输出流更加灵活。它可以向更多的媒介进行榆出,比如向硬盘、内存、网络等进行输出。“new”一个持久化的XML对象。在这里,应该明白为什么要持久化,说白了就是一种写入硬盘的行为。
serializer.setOutput(writer);
设置了输出的方向。它接收两种类型的输出,分别是输出流和写入器。这点用到了刚才向读者介绍的writer写入器。
(3)XML中标签的成对出现,有开始,必有结束。所以在写入一个satrtTag()时,笔者习惯紧跟着写入与之相对应的endTag()。这样不至于在复杂的生成结构时,弄错了XML生成结构。
方法说明:第一个參数是XML的命名空间,第二个是标签名,endTag()相同。
三:
Android开发
相关文章推荐
- Android开发之使用PULL解析和生成XML
- Android使用PULL解析和生成XML文件
- Android进阶——使用Pull解析和生成轻量级数据XML
- Android开发学习---使用XmlPullParser解析xml文件
- Android开发之Pull解析读取和生成XML文件
- android之PULL解析XML(使用SSH框架服务端生成XML)
- 【Android网络开发の3】XML之PULL方式 解析和生成XML文件
- android学习——使用SAX、DOM 和 PULL 解析xml文件,及使用pull生成xml文件
- Android开发之使用pull解析XML文件
- android学习——使用SAX、DOM 和 PULL 解析xml文件,及使用pull生成xml文件
- android sax dom pull 解析xml 和生成xml
- Android中的XML解析与生成——Pull解析xml、实现xml文件的生成
- Android开发进阶(六)--原始XML文件的使用以及PULL解析小例
- android中pull解析xml和生成xml
- 【Android网络开发の2】XML之SAX方式 解析和生成XML文件
- Android学习指南之三十一:Android中使用SAX和pull方式解析XML
- 【Android网络开发の1】XML之DOM方式 解析和生成XML文件 推荐
- Android成长之路-使用Pull生成XML
- android xml解析 XmlPullParser的使用
- Android成长之路-使用Pull解析XML