基于阿里云数加MaxCompute的企业大数据仓库架构建设思路
2017-08-24 14:22
1041 查看
点击查看全文
数加大数据直播系列课程,主要以基于阿里云数加MaxCompute的企业大数据仓库架构建设思路为主题,分享阿里巴巴的大数据是怎么演变以及怎样利用大数据技术构建企业级大数据平台。
本次分享嘉宾是来自阿里云大数据的技术专家祎休!
背景与总体思路
数据仓库是一个面向主题的、集成的、非易失的、反映历史变化的数据集合,用于支持管理决策。其结构图如下所示:
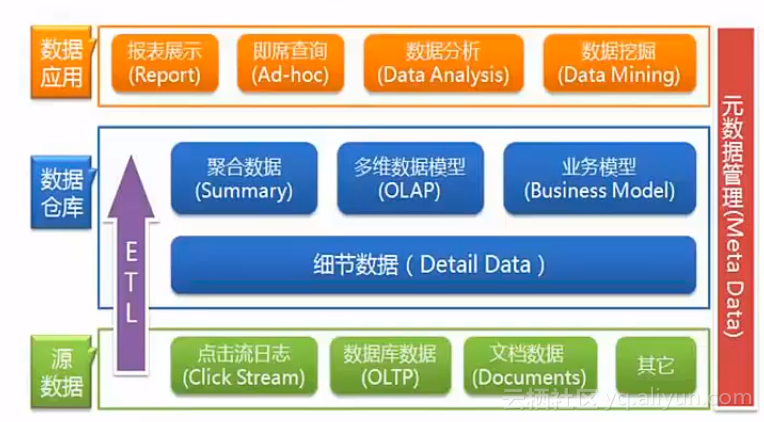
随着大数据、云计算等技术的应用和普及,互联网环境下数据处理呈现出新的特征:业务变化快;数据来源多;系统耦合多;应用深度深。业务变化加快导致数据来源增多,以前的数据大多来自于应用系统数据库,基本为结构化数据,比如Oracle、MySQL等数据。现在的互联网环境下有了更多的数据,比如网站的点击日志、视频数据、语音数据,这些数据都需要通过统一的计算来反映企业的经营状况。在互联网环境下,系统耦合也相对比较多,最重要的是要注重如何在这样的环境下加深数据整合、提升应用深度。从应用深度上来说,之前更多专注于报表分析,在大数据环境下则更多地进行算法分析,通过建立数据模型去预测和研判未来趋势。所以在这种境况下,对于系统的需求也更高:
要求结果数据尽可能快的获取;
实时性需求增多;
访问、获取途径多样便捷;
安全要求高。
在高需求下,传统仓库必然面临着挑战:数据量增长过快导致运行效率下降;数据集成代价大;无法处理多样性的数据;数据挖掘等深度分析能力欠缺。基于这些特征,用户该如何构建大数据仓库?在阿里云的数据仓库构建过程中,总结出了以下四个衡量标准:
稳定——数据产出稳定并有保障,维护系统的稳定性;
可信——数据干净,数据质量足够高,带来更高效的应用服务;
丰富——数据涵盖的业务面足够广泛;
透明——数据的构成体系要足够透明,使得用户放心。
一个完备的大数据仓库应该具备海量的数据存储及处理能力、多样的编程接口和计算框架、丰富的数据采集通道、多种安全防护措施及监控等特征,所以在架构构建时需要遵循一定的设计准则:
自上而下+自下而上地设计,数据驱动和应用驱动整合;
在技术选型上注重高容错性,保证系统稳定;
数据质量监控贯穿整个数据处理流程;
不怕数据冗余,充分利用存储交换易用,减少复杂度和计算量。
架构及模型设计
点击查看全文

数加大数据直播系列课程,主要以基于阿里云数加MaxCompute的企业大数据仓库架构建设思路为主题,分享阿里巴巴的大数据是怎么演变以及怎样利用大数据技术构建企业级大数据平台。
本次分享嘉宾是来自阿里云大数据的技术专家祎休!
背景与总体思路
数据仓库是一个面向主题的、集成的、非易失的、反映历史变化的数据集合,用于支持管理决策。其结构图如下所示:
随着大数据、云计算等技术的应用和普及,互联网环境下数据处理呈现出新的特征:业务变化快;数据来源多;系统耦合多;应用深度深。业务变化加快导致数据来源增多,以前的数据大多来自于应用系统数据库,基本为结构化数据,比如Oracle、MySQL等数据。现在的互联网环境下有了更多的数据,比如网站的点击日志、视频数据、语音数据,这些数据都需要通过统一的计算来反映企业的经营状况。在互联网环境下,系统耦合也相对比较多,最重要的是要注重如何在这样的环境下加深数据整合、提升应用深度。从应用深度上来说,之前更多专注于报表分析,在大数据环境下则更多地进行算法分析,通过建立数据模型去预测和研判未来趋势。所以在这种境况下,对于系统的需求也更高:
要求结果数据尽可能快的获取;
实时性需求增多;
访问、获取途径多样便捷;
安全要求高。
在高需求下,传统仓库必然面临着挑战:数据量增长过快导致运行效率下降;数据集成代价大;无法处理多样性的数据;数据挖掘等深度分析能力欠缺。基于这些特征,用户该如何构建大数据仓库?在阿里云的数据仓库构建过程中,总结出了以下四个衡量标准:
稳定——数据产出稳定并有保障,维护系统的稳定性;
可信——数据干净,数据质量足够高,带来更高效的应用服务;
丰富——数据涵盖的业务面足够广泛;
透明——数据的构成体系要足够透明,使得用户放心。
一个完备的大数据仓库应该具备海量的数据存储及处理能力、多样的编程接口和计算框架、丰富的数据采集通道、多种安全防护措施及监控等特征,所以在架构构建时需要遵循一定的设计准则:
自上而下+自下而上地设计,数据驱动和应用驱动整合;
在技术选型上注重高容错性,保证系统稳定;
数据质量监控贯穿整个数据处理流程;
不怕数据冗余,充分利用存储交换易用,减少复杂度和计算量。
架构及模型设计
点击查看全文

相关文章推荐
- 基于阿里云数加MaxCompute的企业大数据仓库架构建设思路
- 基于阿里云数加MaxCompute的企业大数据仓库架构建设思路
- 基于阿里云数加MaxCompute的企业大数据仓库架构建设思路
- 基于阿里云数加MaxCompute的企业大数据仓库架构建设思路
- 【阿里在线技术峰会】李金波:企业大数据平台仓库架构建设思路
- 企业数据平台仓库架构建设思路
- 【阿里在线技术峰会】李金波:企业大数据平台仓库架构建设思路
- 【阿里在线技术峰会】李金波:企业大数据平台仓库架构建设思路
- 【阿里在线技术峰会】李金波:企业大数据平台仓库架构建设思路
- 7月21日 企业大数据平台仓库架构建设思路直播视频
- 7月21日 企业大数据平台仓库架构建设思路直播视频
- 【阿里在线技术峰会】李金波:企业大数据平台仓库架构建设思路
- 【数据架构解读】基于阿里云数加StreamCompute和MaxCompute构建的访问日志统计分析
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
- 【数据架构解读】基于阿里云数加StreamCompute和MaxCompute构建的访问日志统计分析
- 【数据架构解读】基于阿里云数加StreamCompute和MaxCompute构建的访问日志统计分析
- 基于WEB方式的企业CRM数据仓库设计
- 阿里云MaxCompute被Forrester评为全球云端数据仓库领导者
- 阿里云MaxCompute被Forrester评为全球云端数据仓库领导者
- 企业大数据平台下数仓建设思路