java-3-多线程-初步了解-3-并发
2017-08-22 15:54
405 查看
1.ThreadPoolExecutor
2.ScheduledThreadPoolExecutor
3.ForkJoinPool
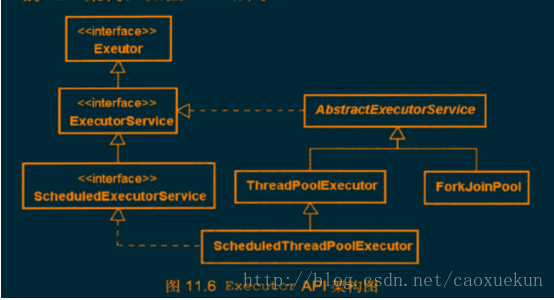
创建线程池
Executors类,提供了一系列工厂方法用于创先线程池,返回的线程池都实现了ExecutorService接口。
public static ExecutorService newFixedThreadPool(int nThreads)
创建固定数目线程的线程池。
public static ExecutorService newCachedThreadPool()
创建一个可缓存的线程池,调用execute 将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
public static ExecutorService newSingleThreadExecutor()
创建一个单线程化的Executor。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
1.ThreadPoolExecutor
2.ScheduledThreadPoolExecutor
3.ForkJoinPool
ForkJoin是Java7提供的原生多线程并行处理框架,其基本思想是将大人物分割成小任务,最后将小任务聚合起来得到结果。它非常类似于HADOOP提供的MapReduce框架,只是MapReduce的任务可以针对集群内的所有计算节点,可以充分利用集群的能力完成计算任务。ForkJoin更加类似于单机版的MapReduce。
2.ScheduledThreadPoolExecutor
3.ForkJoinPool
创建线程池
Executors类,提供了一系列工厂方法用于创先线程池,返回的线程池都实现了ExecutorService接口。
public static ExecutorService newFixedThreadPool(int nThreads)
创建固定数目线程的线程池。
public static ExecutorService newCachedThreadPool()
创建一个可缓存的线程池,调用execute 将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
public static ExecutorService newSingleThreadExecutor()
创建一个单线程化的Executor。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
1.ThreadPoolExecutor
package com.Thread; import java.util.Collection; import java.util.List; import java.util.concurrent.Executor; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.ScheduledThreadPoolExecutor; import java.util.concurrent.ThreadPoolExecutor; /** * @author caoxuekun * @date 2017年8月22日 下午2:54:50 * @version V1.0 * @Description: http://www.jianshu.com/p/ade771d2c9c0 * step1.调用ThreadPoolExecutor的execute提交线程,首先检查CorePool,如果CorePool内的线程小于CorePoolSize,新创建线程执行任务。 * step2.如果当前CorePool内的线程大于等于CorePoolSize,那么将线程加入到BlockingQueue。 * step3.如果不能加入BlockingQueue,在小于MaxPoolSize的情况下创建线程执行任务。 * step4.如果线程数大于等于MaxPoolSize,那么执行拒绝策略。 */ public class ThreadPoolExecutorTest { public static void main(String[] args){ //创建线程池 ThreadPoolExecutor executor = (ThreadPoolExecutor)Executors.newCachedThreadPool(); for (int i = 0; i < 5; i++){ executor.execute(new Task()); } //按过去执行已提交任务的顺序发起一个有序的关闭,但是不接受新任务。 executor.shutdown(); //isTerminated 如果关闭后所有线程都完成,则返回true while(!executor.isTerminated()){ //getPoolSize返回当前线程池中的线程数 getCompletedTaskCount返回线程已完成的近似数 System.out.printf("Pool size:%d,Active count:%d,Completed Task:%d \n",executor.getPoolSize(),executor.getActiveCount(),executor.getCompletedTaskCount()); } // ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) Executors.newSingleThreadExecutor(); // ForkJoinPool executor = (ForkJoinPool) Executors.newFixedThreadPool(10); } } class Task implements Runnable{ public void run() { System.out.println(Thread.currentThread().getName() + " is called"); try { Thread.sleep(100); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
2.ScheduledThreadPoolExecutor
package com.Thread;
import java.util.Date;
import java.util.concurrent.Callable;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* @author caoxuekun
* @date 2017年8月22日 下午3:05:45
* @version V1.0
* @Description:学习了使用ThreadPoolExecutor类来实现自动创建和运行线程。但是那些线程都是一提交就会运行,我们有时候希望不要一提交就运行,
* 而是延迟一段时间或者周期性的运行某个任务,这样我们该怎么办呢,下面就介绍这个类ScheduledThreadPoolExecutor
*/
public class ScheduledThreadPoolExecutorTest implements Runnable {
private String name;
public ScheduledThreadPoolExecutorTest(String name) {
super();
this.name = name;
}
//任务
@Override
public void run() {
System.out.printf("%s: Starting at : %s\n",name,new Date());
}
/**
* 如果implements Runnable,那么默认的任务就是run对应的函数
* 如果implements Callable<String>那么默认的任务就是call对应的函数
*/
// @Override
// public String call() throws Exception {
// System.out.printf("%s: Starting at : %s\n",name,new Date());
// return "hello world";
// }
public static void main(String[] args) {
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(1);
System.out.printf("Main: Starting at: %s\n",new Date());
for(int i = 0; i < 5; i++) {
ScheduledThreadPoolExecutorTest task = new ScheduledThreadPoolExecutorTest("Task " + i);
//创建并执行在给定延迟后启用的一次性操作。schedule(要执行的功能,从现在开始延迟执行的时间,延迟时间参数的单位)
executor.schedule(task, i,TimeUnit.SECONDS);
}
// 在以前已提交任务的执行中发起一个有序的关闭,但是不接受新任务。
executor.shutdown();
try {
//请求关闭、发生超时或者当前线程中断,无论哪一个首先发生之后,都将导致阻塞,直到所有任务完成执行。
//awaitTermination(最长等待时间,等待时间参数的单位)
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.printf("Main: Ends at: %s\n",new Date());
}
}3.ForkJoinPool
ForkJoin是Java7提供的原生多线程并行处理框架,其基本思想是将大人物分割成小任务,最后将小任务聚合起来得到结果。它非常类似于HADOOP提供的MapReduce框架,只是MapReduce的任务可以针对集群内的所有计算节点,可以充分利用集群的能力完成计算任务。ForkJoin更加类似于单机版的MapReduce。
package com.Thread;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class ForkJoinPoolTest extends RecursiveTask<Integer>
{
private static final long serialVersionUID = -3611254198265061729L;
public static final int threshold = 2;
private int start;
private int end;
public ForkJoinPoolTest(int start, int end)
{
this.start = start;
this.end = end;
}
@Override
protected Integer compute()
{
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= threshold;
if(canCompute)
{
for (int i=start; i<=end; i++)
{
sum += i;
}
}
else
{
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end)/2;
ForkJoinPoolTest leftTask = new ForkJoinPoolTest(start, middle);
ForkJoinPoolTest rightTask = new ForkJoinPoolTest(middle+1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
//等待任务执行结束合并其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args)
{
ForkJoinPool forkjoinPool = new ForkJoinPool();
//生成一个计算任务,计算1+2+3+4...+100
ForkJoinPoolTest task = new ForkJoinPoolTest(1, 100);
//执行一个任务
Future<Integer> result = forkjoinPool.submit(task);
try
{
System.out.println(result.get());
}
catch(Exception e)
{
System.out.println(e);
}
}
}

相关文章推荐
- Java多线程(一)初步了解
- Java多线程初步了解
- 对于Java中多线程互斥锁初步了解
- Java多线程并发锁和原子操作,你真的了解吗?
- JAVA学习第二十一课(多线程(一)) - (初步了解)
- java-3-多线程-初步了解-3-同步
- Java多线程与并发 - 了解“monitor”
- Java多线程并发锁和原子操作,你真的了解吗?
- JAVA学习第二十一课(多线程(一)) - (初步了解)
- Java多线程--并发和并行的区别
- java多线程和并发面试(转)
- JAVA多线程和并发基础面试问答
- JAVA 并发-多线程读写锁之模拟缓存系统(11)
- Java 7之多线程并发容器 - CopyOnWriteArrayList
- Java多线程程序设计初步(2)
- Java并发多线程面试题 Top 50
- java多线程并发访问解决方案
- java并发线程池---了解ThreadPoolExecutor就够了
- java多线程之线程并发库面试题
- JAVA:NIO初步了解