一步一步搞定Python3.6编码问题
2017-08-18 12:25
120 查看
Python中的编码问题很蛋疼,我们遇到这类问题有时候会使用下面几个步骤处理该问题:
1:这么低级问题,别问同事了太丢人,赶紧百度;
2:卧槽,出了一堆广告,骂个娘,赶紧找相关解决问题方式;
3:尼玛,终于搞定,原来这么简单,赶紧搞定其它工作,晚上回头在查原因;
4:傻B单位每天加班,到家都11点了,赶紧洗洗睡了;等会,先来局王者农药......
5:编码问题早就忘了;
6:过了几天又出现编码错误,

,从第1步开始重新来过。
今天我们就花一局王者农药时间搞定Python3.6的编码问题。
搞清楚编码格式:
1)编码格式:utf-8, gbk, gb2312, unicode...
计算机和编码关系:计算机如何显示打印文字:中文,英文等。计算机不能识别字符,那么它如何显示?
计算机可以读取数据,于是我们前辈就弄一个字模,通过01标识把这个字符给他画出来,然后使用一个二进制码和这个字模对应起来,这样,计算机就能根据这个二进制码把这个字符显示出来了。
计算机 -> 编码 -> 字模点阵 ->显示,打印等。
2)为什么那么多编码格式?
计算机是美国人发明的,他们只需要使用英文字符和常用符号,于是ascii(256)就足够了;
后来计算机普及了,中国人想让处理汉字,日本人想让他处理日文,阿拉伯人想让他处理阿拉伯语,于是就有了各种编码格式;比如gb2312,;但是gb2312表示一个字符需要2个字节,这样表示一个英文字符有点浪费,于是大牛们整出了utf-8,utf-16等可变长编码格式。
出现了太多的编码格式,让人蛋疼,于是大牛们同意规范,又整出了unicode编码格式,支持所有的语言。
到这里,可能明白编码格式了。
3)编写一个txt文件,内容为:"中国",他存储的是“中国”这个汉字么,还是??
1: 借助工具看一哈:
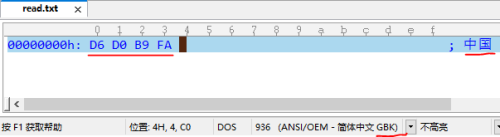
文件内容:中国
文件存储内容:二进制数字:D6D0 B9FA
文件编码格式:gbk
2:修改下软件编码格式:utf-8
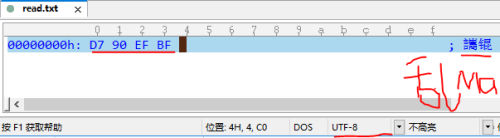
乱码有么有。
为什么乱码?因为文字存储编码格式为gbk,我们指定软件编码格式utf-8,然后问题出现了:
软件去utf-8的编码表里找不到D6D0 B9FA对应的字模,或者找错了,所以会乱码。
Python中编码格式问题
1:Python内置存储格式为unicode
2:字符流和字节流问题:
1)字符流:程序内部使用,不能直接保存文件;str类型;
2)字节流:保存文件,网络传输;byte类型;
3:Python中的编码格式转换
python3.6版本中,s为unicode,是字符串类型,没有decode方法,所以做解码失败;
u8是s使用utf-8编码后的数据,没有encode方法;
u8可以使用decode方法解码成unicode,如果解码格式为其它,我们可以看看结果:
原因:u8的编码格式是utf-8,我们使用gbk去解码,造成该错误。
编码格式之间转换:(gb2312,utf-8...)->unicode ->(gb2312,utf-8...);
unicode是中间的桥梁。
4:文件打开问题(环境:window下):
将一个文本文件存储为utf-8编码,
1)文件存储形式字节,读取的时候是字节,编码格式为Utf-8
2)读取文件时候,read方法会做一个解码操作,但是他是什么形式解码呢?查看帮助文档:
5:文件存储问题:
一个栗子:
好了到这里,编码基本就到这里,如果还有不清楚的可以参考俺的视频课程:
http://edu.51cto.com/course/8983.html,第二章内容。
1:这么低级问题,别问同事了太丢人,赶紧百度;
2:卧槽,出了一堆广告,骂个娘,赶紧找相关解决问题方式;
3:尼玛,终于搞定,原来这么简单,赶紧搞定其它工作,晚上回头在查原因;
4:傻B单位每天加班,到家都11点了,赶紧洗洗睡了;等会,先来局王者农药......
5:编码问题早就忘了;
6:过了几天又出现编码错误,
,从第1步开始重新来过。
今天我们就花一局王者农药时间搞定Python3.6的编码问题。
搞清楚编码格式:
1)编码格式:utf-8, gbk, gb2312, unicode...
计算机和编码关系:计算机如何显示打印文字:中文,英文等。计算机不能识别字符,那么它如何显示?
计算机可以读取数据,于是我们前辈就弄一个字模,通过01标识把这个字符给他画出来,然后使用一个二进制码和这个字模对应起来,这样,计算机就能根据这个二进制码把这个字符显示出来了。
计算机 -> 编码 -> 字模点阵 ->显示,打印等。
2)为什么那么多编码格式?
计算机是美国人发明的,他们只需要使用英文字符和常用符号,于是ascii(256)就足够了;
后来计算机普及了,中国人想让处理汉字,日本人想让他处理日文,阿拉伯人想让他处理阿拉伯语,于是就有了各种编码格式;比如gb2312,;但是gb2312表示一个字符需要2个字节,这样表示一个英文字符有点浪费,于是大牛们整出了utf-8,utf-16等可变长编码格式。
出现了太多的编码格式,让人蛋疼,于是大牛们同意规范,又整出了unicode编码格式,支持所有的语言。
到这里,可能明白编码格式了。
3)编写一个txt文件,内容为:"中国",他存储的是“中国”这个汉字么,还是??
1: 借助工具看一哈:
文件内容:中国
文件存储内容:二进制数字:D6D0 B9FA
文件编码格式:gbk
2:修改下软件编码格式:utf-8
乱码有么有。
为什么乱码?因为文字存储编码格式为gbk,我们指定软件编码格式utf-8,然后问题出现了:
软件去utf-8的编码表里找不到D6D0 B9FA对应的字模,或者找错了,所以会乱码。
Python中编码格式问题
1:Python内置存储格式为unicode
2:字符流和字节流问题:
1)字符流:程序内部使用,不能直接保存文件;str类型;
2)字节流:保存文件,网络传输;byte类型;
3:Python中的编码格式转换
#Python3.6
>>> s = '中国'
>>> s.decode('utf-8')
Traceback (most recent call last):
File "<pyshell#21>", line 1, in <module>
s.decode('utf-8')
AttributeError: 'str' object has no attribute 'decode'
>>> u8 = s.encode('utf-8')
>>> u8
b'\xe4\xb8\xad\xe5\x9b\xbd'
>>> u8.encode('utf-8')
Traceback (most recent call last):
File "<pyshell#24>", line 1, in <module>
u8.encode('utf-8')
AttributeError: 'bytes' object has no attribute 'encode'
>>> u8.decode('utf-8')
'中国'
>>>python3.6版本中,s为unicode,是字符串类型,没有decode方法,所以做解码失败;
u8是s使用utf-8编码后的数据,没有encode方法;
u8可以使用decode方法解码成unicode,如果解码格式为其它,我们可以看看结果:
>>> u8.decode('gbk')
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
u8.decode('gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence 常见解码错误:UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2:原因:u8的编码格式是utf-8,我们使用gbk去解码,造成该错误。
编码格式之间转换:(gb2312,utf-8...)->unicode ->(gb2312,utf-8...);
unicode是中间的桥梁。
4:文件打开问题(环境:window下):
将一个文本文件存储为utf-8编码,
>>> f = open('readme.txt')
>>> f.read()
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xbd in position 8: incomplete multibyte sequence 将文件打开,读取的时候为什么会有问题;1)文件存储形式字节,读取的时候是字节,编码格式为Utf-8
2)读取文件时候,read方法会做一个解码操作,但是他是什么形式解码呢?查看帮助文档:
>>> help(open) Help on built-in function open in module io: open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) Open file and return a stream. Raise IOError upon failure. ..... >>> f <_io.TextIOWrapper name='readme.txt' mode='r' encoding='cp936'>这里可以看到,f的编码格式"cp936",这个和gbk是一样的编码格式,到这里知道为啥会出错了吧,文件存储字节是utf-8编码,解码使用gbk方式,所以会出错,在open的时候指定编码格式utf-8再来一次试试:
>>> f = open('readme.txt', encoding='utf-8')
>>> line = f.readline()
>>> line
'\ufeff中国'
>>> print (line)
中国 读取成功,"\ufeff"是window下utf-8文件编码格式头。到这里我们就基本搞清楚常见的编码问题了。5:文件存储问题:
一个栗子:
>>> f = open('test.txt', 'w')
>>> f.write('中国')
>>> f.close() 传的参数为字符流,但实际存储为字节流,>>> f = open('test.txt', 'rb')
>>> f.read()
b'\xd6\xd0\xb9\xfa'自己搞搞:使用utf-8方式打开test.txt, 然后读取出现什么问题?好了到这里,编码基本就到这里,如果还有不清楚的可以参考俺的视频课程:
http://edu.51cto.com/course/8983.html,第二章内容。

相关文章推荐
- python3.6 读取csv时编码问题
- 搞定Python编码问题
- python 各种问题处理更新 何不一次性搞定全部编码知识
- python 编码编码相关问题
- python2 读取文件TXT编码问题
- rood-Python 3读取.CSV文件遇到的编码问题
- python2.7的编码问题与解决方法
- module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6问题解决
- python 3.6安装mysql以及不常见问题
- python中文字符串数组编码的问题
- python 2 编码问题
- Python3 学习第四弹:编码问题(转载)
- Python中的编码问题
- Python 2.7 + SQLite3 编码问题
- python 编码问题 u'汉字'
- python常见编码问题解决方法
- python读取文件中的第一行出现编码问题
- 数据库乱码问题 & Python 编码问题(Unicode 的 encode、decode 相互转换 )
- python与sqlite处理中文字符时出现的编码错误问题解决
- 关于python编码问题无法读取GBK文件