SparkContext初始化图解与源码解析
2017-08-15 17:15
429 查看
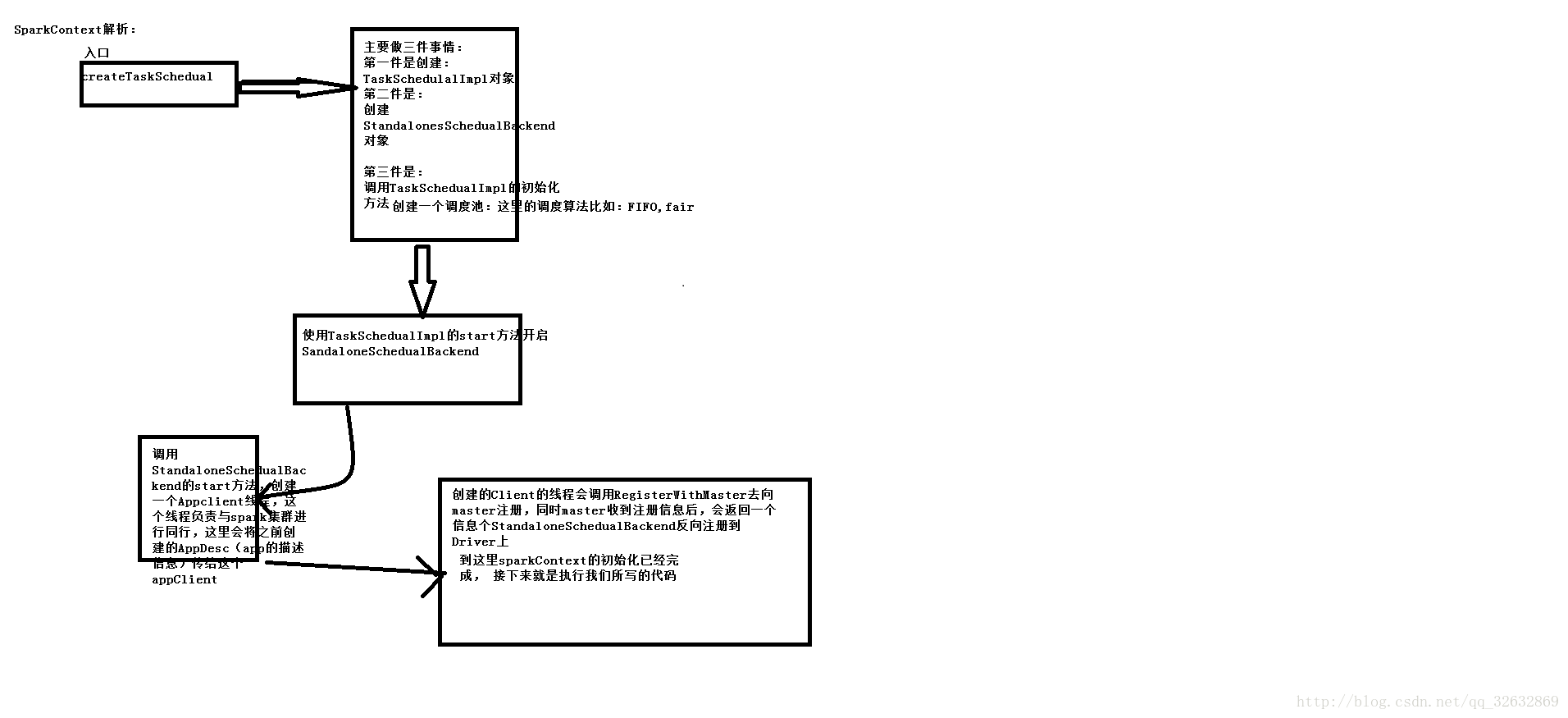
上图说明:客户端提交作业是首第一步总是初始化SparkContext这个类,sparkcontext初始化的入口是一个叫做createTaskImpl这个方法,在这个方法中我们主要是做了三件事,第一件事就是new一个TaskSchedualImpl这个对象,第二件事是:new 一个StandanloneSchedualBackend这个对象,第三件事就是通过初始化创建的TaskSchedualImpl这个对象去调用init方法,在这个init方法中,我们首先创建一个线程的调度池,这里的算法主要是FIFO和fair这两种算法,然后通过TaskSchedualImpl这个类调用start方法开启StandaloneSchedualBackend这个类中的start方法,在StandaloneSchedualBackend这个类中我们会得到application任务的相关信息,将相关信息通过ApplicationDescription这个类封装起来,然后通过这些信息创建StandaloneAppClient对象,创建的StandaloneAppClient调用start方法去开启appClient,在这个StandaloneAppClient类中我们回去调用tryRegisterAllMasters或者registerWithMaster去创建一个线程去将application注册到master之上,注册成功后,master会响应信息反向注册,然后将响应信息返回,这时会将application得到状态改变成Running
SparkContext源码解析:
//standalone方式运行
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)进入initialize方法
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
// 优先策略 FIFO FAIR,NONE
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported spark.scheduler.mode: $schedulingMode")
}
}
schedulableBuilder.buildPools() //创建了一个调度池
}
def newTaskId(): Long = nextTaskId.getAndIncrement()
override def start() { //开启StandaloneSchedualBackend,这个对象是负责创建与spark的master集群通信,并注册和反向注册的
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}//StandaloneSchedualBackend对象中的开启线程
override def start() {
super.start()
launcherBackend.connect()
// The endpoint for executors to talk to us
val driverUrl = RpcEndpointAddress(
sc.conf.get("spark.driver.host"),
sc.conf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
//准备环境,为了taskSchedual的注册
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
// If we're using dynamic allocation, set our initial executor limit to 0 for now.
// ExecutorAllocationManager will send the real initial limit to the Master later.
val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
// 封装了application的信息
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)、
//创建StandaloneAppclient
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start() ///开启一个appClient线程
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)//standaloneAppClient对象中
注册master
override def onStart(): Unit = {
try {
//调用registerWithMaster去向master注册
registerWithMaster(1)
} catch {
case e: Exception =>
logWarning("Failed to connect to master", e)
markDisconnected()
stop()
}
}
/**
* Register with all masters asynchronously. It will call `registerWithMaster` every
* REGISTRATION_TIMEOUT_SECONDS seconds until exceeding REGISTRATION_RETRIES times.
* Once we connect to a master successfully, all scheduling work and Futures will be cancelled.
*
* nthRetry means this is the nth attempt to register with master.
*/
private def registerWithMaster(nthRetry: Int) {
registerMasterFutures.set(tryRegisterAllMasters())
registrationRetryTimer.set(registrationRetryThread.schedule(new Runnable {
override def run(): Unit = {
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
} else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1)
}
}
}, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
}

相关文章推荐
- Spark 源码解析之SparkContext都做了些什么
- Spark 源码解析之SparkContext家族(一)
- 第23课:Spark Streaming初始化和关闭源码图解
- 第23课:Spark Streaming初始化和关闭源码图解
- Spark源码-SparkContext源码解析
- Spark 源码解析之SparkContext都做了些什么
- Spark 源码解析之SparkContext家族(一)
- spark-core_11:org.apache.spark.deploy.master.Master源码解析3--MasterWebUI(MasterRpcEndPoint,8080)初始化web
- Spark 源码解析之SparkContext都做了些什么
- Spark 源码解析之SparkContext家族(一)
- 第45讲:Scala中Context Bounds代码实战及其在Spark中的应用源码解析
- Spark 源码解析之SparkContext都做了些什么
- Spark 源码解析之SparkContext家族(一)
- Spark源码解读之SparkContext初始化
- Spark学习笔记(24)StreamingContext及JobScheduler源码图解
- Spark 源码解析之SparkContext都做了些什么
- Spark 源码解析之SparkContext家族(一)
- Scala深入浅出进阶经典 第45讲:Scala中Context Bounds代码实战及其在Spark中的应用源码解析
- Spark 源码解析之SparkContext都做了些什么
- Spark 源码解析之SparkContext家族(一)