CNTK API文档翻译(16)——增强学习基础
2017-08-14 22:37
387 查看
增强学习(RL,Reinforcement learnin)是一个由行为心理学衍生出来的机器学习领域,主要是有关软件代理如何在一个特定的环境中尽可能的获得得分。在机器学习中,为了让增强学习算法利用动态编程技术,这种环境通常被指定为马尔可夫决策过程。
在有些机器学习情况中,我们不能够直接获得数据的标签,所以我们不能够使用监督学习技术。如果我们能够与学习过程进行交互,从而偶尔告诉我们一些反馈意见,无论我们之前的表现是否良好,我们都可以使用增强学习来改善我们的行为。
与监督学习不同,在增强学习中,没有正确标记的输入输出对,局部最优解也不会明确正确。这种学习方式模仿很多在线学习范例,其中涉及探索(未训练)和开发(已训练)之间的平衡。多臂赌博机问题是增强学习算法中关于探索与开发问题的已经被深入研究过的一个类别。参见下图参考:
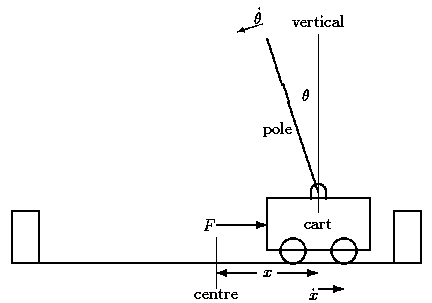
用增强学习的专业术语来说,目标是找到一个策略a,在一定的环境中(本例中是杆最初是平衡的)达到得分r最大化。所以做了一系列的实验:s→r,s′(箭头中间应该表上a,但是部分markdown不支持)。然后就可以一直学习如何选择动作a,在给定的状态s下来使我们模拟的得分r最大化:
Q(s,a)=r0+γr1+γ2r2+…=r0+γmaxaQ∗(s′,a)
其中γ∈[0,1)是一个折扣因素,用来控制我们如何评估越来越大的得分值,这也被叫做贝尔曼方程(Bellman Equation)。
在本教程中我哦们将展示如何构建状态空间模型,如何使用收到的得分来指出什么操作将获得最高的得分。
我们在这里展现两种常用方法:
深度Q型网络(Deep Q-Networks,DQN): DQN在2015年因为被成功用于训练如何玩雅达利游戏而得名。我们训练神经网络来学习Q的值(所以叫Q型网络)。从这些Q的函数值中我们选择出最好的。
基于策略的梯度: 这种方法直接在神经网络里面评估策略(操作集)。所以就是通过随机选择一些操作小集合来训练一个可以让得分最大化的有序操作集。在本教程中,我们使用梯度下降来训练操作集进而训练策略。
在本教程中,我们专注于如何使用CNTK来实现增强学习。我们选用浅的神经网络。读者可以使用其他教程中学习的深度网络来替换我们的模型。
最后,本教程还处于早期版本,以后还会更新(我应该是不会翻译了的)。
如果之前没有安装OpenAI gym ,我们使用下面的代码安装。
快速模式:isFast变量设置成True。这是我们的默认模式,在这个模式下我们会训练更少的次数,也会使用更少的数据,这个模式保证功能的正确性,但训练的结果还远远达不到可用的要求。
慢速模式:我们建议学习者在学习的时候试试将isFast变量设置成False,这会让学习者更加了解本教程的内容。
在每个单位时间内,代理
获取一个观测值(x,x˙,θ,θ˙),分别代表小车的位置、小车的速度、杆与垂直方向的夹角,杆的角速度。
执行一个向左或者向右的动作
获得
获得1分
一个新的状态(x′,x˙′,θ′,θ˙′)
当出现如下状况,游戏结束:
杆与竖直方向的夹角超过15度或者
小车离中间超过2.4个单位距离
如果出现如下状况,我们认为完成任务:
代理在最后的50次游戏中获得平均高于200分的成绩
在快速模式下,任务还是比较容易完成的
DQN:
训练出Q函数,将观测值(s,a)和得分映射起来
使用之前存储的值来重现(之前的Q值和相对应的(s,a)与得分的相关性)
使用第二个神经网络来进行固定训练(不属于本教程讨论的内容)
我们先从一个使用Keras(另一个机器学习框架)的脚本(https://github.com/jaara/AI-blog/blob/master/CartPole-basic.py)开始,然后逐步改用CNTK。
我们使用一个简单的两层全连接神经网络来做一个简单的示意,更高级的神经网络可以由此替换。
CNTK 概念:注释的代码意在说明CNTK API和Keras的相似性。
在下面的代码中,我们通过检查在CNTK内部定义的环境变量来选择正确的设备(GPU或者CPU)来运行代码,如果不检查的话,会使用CNTK的默认策略来使用最好的设备(如果GPU可用的话就使用GPU,否则使用CPU)
以下代码中,STATE_COUNT = 4(与(x,x˙,θ,θ˙)对应),ACTION_COUNT = 2(与左右操作对应)。
注意:在下面的代码的注释部分中我们说明了在Keras中如何实现,这与CNTK中非常类似,虽然CNTK中可以让代码更简洁,其他的注释是对代码的一个简单说明,方便学习。
另外,你可能已经注意到,CNTK的模型不需要有一个明确的生成过程,他会在使用数据训练时自动实现。
CNTK在使用取样包时能更有效的使用可用内存,所以学习速率表示的是每个样本的学习速率,而不是每个取样包的学习速率。
Memory类用来存储不同的状态、动作和得分。
代理使用Brain类和Memory类来复线之前的动作,以此选取更好的动作集合,得到最高的分数。

现在我们准备好了使用DQN训练我们的代理。注意这将使用大概2到10分钟的时间,只要当最后50次平均得分超过200分训练就会停止。如果你设置高于200分,你可以得到很好的结果。
更新策略使好的实验概率更大
我们的参数直接参与策略的建模,在DQN中是参与值函数的建模
问题:一般来说,我们不知道哪个动作有利于我们持续游戏,哪个动作会导致游戏失败。我们的简单想法:游戏开始时的动作是好的,游戏结束时的动作可能不好,因为他导致游戏失败。

我们归一化得分,使得分在一直0附近,gamma控制我们可以获得得分的时间。


注意:使用策略梯度方法时,由于使用了sigmoid函数,全连接层的输出值被映射到了0-1之间。
策略搜索: 策略搜索的优化可以使用自有梯度实现,也可以使用在使用θ参数化的策略空间(πθ)内计算梯度来实现。 在本教程中,我们使用传统前馈和误差在参数化空间θ内反向传播。所以我们的模型参数:θ={W1,b1,W2,b2},
欢迎扫码关注我的微信公众号获取最新文章

在有些机器学习情况中,我们不能够直接获得数据的标签,所以我们不能够使用监督学习技术。如果我们能够与学习过程进行交互,从而偶尔告诉我们一些反馈意见,无论我们之前的表现是否良好,我们都可以使用增强学习来改善我们的行为。
与监督学习不同,在增强学习中,没有正确标记的输入输出对,局部最优解也不会明确正确。这种学习方式模仿很多在线学习范例,其中涉及探索(未训练)和开发(已训练)之间的平衡。多臂赌博机问题是增强学习算法中关于探索与开发问题的已经被深入研究过的一个类别。参见下图参考:
问题
我们将使用来自OpenAI’s gym模拟器里面的CartPole环境来教小车让杆平衡。在CartPole示例中,杆通过无摩擦的接头连接到小车,小车沿着光滑的轨道移动。系统由施加于小车上+1或者-1的力来控制。杆保持竖直的每个单位时间,我们会获得1分。当杆离竖直偏移超过15度或者小车离中间超过2.4个单位距离时,游戏结束。目标
我们的目标是防止在车移动的时候杆从竖直状态偏倒。更明确的说,如果杆离竖直的偏角小于15度以及车在离中间2.4的单位距离以内,我们会得分。在本教程中,我们将训练直到训练出的一系列动(策略)作在最后的50个批次中获得的平均得分在200以上。用增强学习的专业术语来说,目标是找到一个策略a,在一定的环境中(本例中是杆最初是平衡的)达到得分r最大化。所以做了一系列的实验:s→r,s′(箭头中间应该表上a,但是部分markdown不支持)。然后就可以一直学习如何选择动作a,在给定的状态s下来使我们模拟的得分r最大化:
Q(s,a)=r0+γr1+γ2r2+…=r0+γmaxaQ∗(s′,a)
其中γ∈[0,1)是一个折扣因素,用来控制我们如何评估越来越大的得分值,这也被叫做贝尔曼方程(Bellman Equation)。
在本教程中我哦们将展示如何构建状态空间模型,如何使用收到的得分来指出什么操作将获得最高的得分。
我们在这里展现两种常用方法:
深度Q型网络(Deep Q-Networks,DQN): DQN在2015年因为被成功用于训练如何玩雅达利游戏而得名。我们训练神经网络来学习Q的值(所以叫Q型网络)。从这些Q的函数值中我们选择出最好的。
基于策略的梯度: 这种方法直接在神经网络里面评估策略(操作集)。所以就是通过随机选择一些操作小集合来训练一个可以让得分最大化的有序操作集。在本教程中,我们使用梯度下降来训练操作集进而训练策略。
在本教程中,我们专注于如何使用CNTK来实现增强学习。我们选用浅的神经网络。读者可以使用其他教程中学习的深度网络来替换我们的模型。
最后,本教程还处于早期版本,以后还会更新(我应该是不会翻译了的)。
在我们开始之前
引入需要的模块from __future__ import print_function
from __future__ import division
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import pandas as pd
import seaborn as sns
style.use('ggplot')如果之前没有安装OpenAI gym ,我们使用下面的代码安装。
try: import gym except: !pip install gym import gym
选择运行模式
我们设定了两种运行模式:快速模式:isFast变量设置成True。这是我们的默认模式,在这个模式下我们会训练更少的次数,也会使用更少的数据,这个模式保证功能的正确性,但训练的结果还远远达不到可用的要求。
慢速模式:我们建议学习者在学习的时候试试将isFast变量设置成False,这会让学习者更加了解本教程的内容。
isFast = True
CartPole介绍:数据和环境
我们将使用来自OpenAI’s gym模拟器的CartPole环境来教小车平衡杆。在每个单位时间内,代理
获取一个观测值(x,x˙,θ,θ˙),分别代表小车的位置、小车的速度、杆与垂直方向的夹角,杆的角速度。
执行一个向左或者向右的动作
获得
获得1分
一个新的状态(x′,x˙′,θ′,θ˙′)
当出现如下状况,游戏结束:
杆与竖直方向的夹角超过15度或者
小车离中间超过2.4个单位距离
如果出现如下状况,我们认为完成任务:
代理在最后的50次游戏中获得平均高于200分的成绩
在快速模式下,任务还是比较容易完成的
第一部分:DQN
在转换(s,a,r,s’)后,我们尝试让我们的值函数Q(s,a)与我们的目标r+γmaxa′Q(s′,a′)更近,其中γ是一个值在0到1之间的折扣因素。DQN:
训练出Q函数,将观测值(s,a)和得分映射起来
使用之前存储的值来重现(之前的Q值和相对应的(s,a)与得分的相关性)
使用第二个神经网络来进行固定训练(不属于本教程讨论的内容)
创建模型
l1=relu(xW1+b1)Q(s,a)=l1W2+b2我们先从一个使用Keras(另一个机器学习框架)的脚本(https://github.com/jaara/AI-blog/blob/master/CartPole-basic.py)开始,然后逐步改用CNTK。
我们使用一个简单的两层全连接神经网络来做一个简单的示意,更高级的神经网络可以由此替换。
CNTK 概念:注释的代码意在说明CNTK API和Keras的相似性。
import numpy import math import os import random import cntk as C
在下面的代码中,我们通过检查在CNTK内部定义的环境变量来选择正确的设备(GPU或者CPU)来运行代码,如果不检查的话,会使用CNTK的默认策略来使用最好的设备(如果GPU可用的话就使用GPU,否则使用CPU)
# Select the right target device when this notebook is being tested: if 'TEST_DEVICE' in os.environ: if os.environ['TEST_DEVICE'] == 'cpu': C.device.try_set_default_device(C.device.cpu()) else: C.device.try_set_default_device(C.device.gpu(0))
以下代码中,STATE_COUNT = 4(与(x,x˙,θ,θ˙)对应),ACTION_COUNT = 2(与左右操作对应)。
env = gym.make('CartPole-v0')
STATE_COUNT = env.observation_space.shape[0]
ACTION_COUNT = env.action_space.n
STATE_COUNT, ACTION_COUNT注意:在下面的代码的注释部分中我们说明了在Keras中如何实现,这与CNTK中非常类似,虽然CNTK中可以让代码更简洁,其他的注释是对代码的一个简单说明,方便学习。
另外,你可能已经注意到,CNTK的模型不需要有一个明确的生成过程,他会在使用数据训练时自动实现。
CNTK在使用取样包时能更有效的使用可用内存,所以学习速率表示的是每个样本的学习速率,而不是每个取样包的学习速率。
# Targetted reward
REWARD_TARGET = 30 if isFast else 200
# Averaged over these these many episodes
BATCH_SIZE_BASELINE = 20 if isFast else 50
H = 64 # hidden layer size
class Brain:
def __init__(self):
self.params = {}
self.model, self.trainer, self.loss = self._create()
# self.model.load_weights("cartpole-basic.h5")
def _create(self):
observation = C.sequence.input_variable(STATE_COUNT, np.float32, name="s")
q_target = C.sequence.input_variable(ACTION_COUNT, np.float32, name="q")
# Following a style similar to Keras
l1 = C.layers.Dense(H, activation=C.relu)
l2 = C.layers.Dense(ACTION_COUNT)
unbound_model = C.layers.Sequential([l1, l2])
model = unbound_model(observation)
self.params = dict(W1=l1.W, b1=l1.b, W2=l2.W, b2=l2.b)
# loss='mse'
loss = C.reduce_mean(C.square(model - q_target), axis=0)
meas = C.reduce_mean(C.square(model - q_target), axis=0)
# optimizer
lr = 0.00025
lr_schedule = C.learning_rate_schedule(lr, C.UnitType.minibatch)
learner = C.sgd(model.parameters, lr_schedule, gradient_clipping_threshold_per_sample=10)
trainer = C.Trainer(model, (loss, meas), learner)
# CNTK: return trainer and loss as well
return model, trainer, loss
def train(self, x, y, epoch=1, verbose=0):
#self.model.fit(x, y, batch_size=64, nb_epoch=epoch, verbose=verbose)
arguments = dict(zip(self.loss.arguments, [x,y]))
updated, results =self.trainer.train_minibatch(arguments, outputs=[self.loss.output])
def predict(self, s):
return self.model.eval([s])Memory类用来存储不同的状态、动作和得分。
class Memory: # stored as ( s, a, r, s_ ) samples = [] def __init__(self, capacity): self.capacity = capacity def add(self, sample): self.samples.append(sample) if len(self.samples) > self.capacity: self.samples.pop(0) def sample(self, n): n = min(n, len(self.samples)) return random.sample(self.samples, n)
代理使用Brain类和Memory类来复线之前的动作,以此选取更好的动作集合,得到最高的分数。
MEMORY_CAPACITY = 100000 BATCH_SIZE = 64 # discount factor GAMMA = 0.99 MAX_EPSILON = 1 # stay a bit curious even when getting old MIN_EPSILON = 0.01 # speed of decay LAMBDA = 0.0001 class Agent: steps = 0 epsilon = MAX_EPSILON def __init__(self): self.brain = Brain() self.memory = Memory(MEMORY_CAPACITY) def act(self, s): if random.random() < self.epsilon: return random.randint(0, ACTION_COUNT-1) else: return numpy.argmax(self.brain.predict(s)) # in (s, a, r, s_) format def observe(self, sample): self.memory.add(sample) # slowly decrease Epsilon based on our eperience self.steps += 1 self.epsilon = MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * math.exp(-LAMBDA * self.steps) def replay(self): batch = self.memory.sample(BATCH_SIZE) batchLen = len(batch) no_state = numpy.zeros(STATE_COUNT) # CNTK: explicitly setting to float32 states = numpy.array([ o[0] for o in batch ], dtype=np.float32) states_ = numpy.array([(no_state if o[3] is None else o[3]) for o in batch ], dtype=np.float32) p = agent.brain.predict(states) p_ = agent.brain.predict(states_) # CNTK: explicitly setting to float32 x = numpy.zeros((batchLen, STATE_COUNT)).astype(np.float32) y = numpy.zeros((batchLen, ACTION_COUNT)).astype(np.float32) for i in range(batchLen): s, a, r, s_ = batch[i] # CNTK: [0] because of sequence dimension t = p[0][i] if s_ is None: t[a] = r else: t[a] = r + GAMMA * numpy.amax(p_[0][i]) x[i] = s y[i] = t self.brain.train(x, y)
脑外科
对每一次训练,我们都希望看到我们初始化的操作集是会进行广泛探索的,通过一次次的迭代,系统确定了一个操作集的范文,让系统运行更长时间,获得更高的分数。下面的代码通过ϵ-greedy算法实现了这些。def plot_weights(weights, figsize=(7,5)):
'''Heat map of weights to see which neurons play which role'''
sns.set(style="white")
f, ax = plt.subplots(len(weights), figsize=figsize)
cmap = sns.diverging_palette(220, 10, as_cmap=True)
for i, data in enumerate(weights):
axi = ax if len(weights)==1 else ax[i]
if isinstance(data, tuple):
w, title = data
axi.set_title(title)
else:
w = data
sns.heatmap(w.asarray(), cmap=cmap, square=True, center=True, #annot=True,
linewidths=.5, cbar_kws={"shrink": .25}, ax=axi)探索和开发平衡
注意初始的ϵ被设置成1,折表示开始是完全的探索,但是随着操作步骤增加,我们会减少探索,改为学着获得分数。def epsilon(steps):
return MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * np.exp(-LAMBDA * steps)
plt.plot(range(10000), [epsilon(x) for x in range(10000)], 'r')
plt.xlabel('step');plt.ylabel('$\epsilon$')现在我们准备好了使用DQN训练我们的代理。注意这将使用大概2到10分钟的时间,只要当最后50次平均得分超过200分训练就会停止。如果你设置高于200分,你可以得到很好的结果。
TOTAL_EPISODES = 2000 if isFast else 3000
def run(agent):
s = env.reset()
R = 0
while True:
# Uncomment the line below to visualize the cartpole
# env.render()
# CNTK: explicitly setting to float32
a = agent.act(s.astype(np.float32))
s_, r, done, info = env.step(a)
if done: # terminal state
s_ = None
agent.observe((s, a, r, s_))
agent.replay()
s = s_
R += r
if done:
return R
agent = Agent()
episode_number = 0
reward_sum = 0
while episode_number < TOTAL_EPISODES:
reward_sum += run(agent)
episode_number += 1
if episode_number % BATCH_SIZE_BASELINE == 0:
print('Episode: %d, Average reward for episode %f.' % (episode_number,
reward_sum / BATCH_SIZE_BASELINE))
if episode_number%200==0:
plot_weights([(agent.brain.params['W1'], 'Episode %i $W_1$'%episode_number)], figsize=(14,5))
if reward_sum / BATCH_SIZE_BASELINE > REWARD_TARGET:
print('Task solved in %d episodes' % episode_number)
plot_weights([(agent.brain.params['W1'], 'Episode %i $W_1$'%episode_number)], figsize=(14,5))
break
reward_sum = 0
agent.brain.model.save('dqn.mod')运行DQN模型
env = gym.make('CartPole-v0')
# number of episodes to run
num_episodes = 10
modelPath = 'dqn.mod'
root = C.load_model(modelPath)
for i_episode in range(num_episodes):
print(i_episode)
# reset environment for new episode
observation = env.reset()
done = False
while not done:
if not 'TEST_DEVICE' in os.environ:
env.render()
action = np.argmax(root.eval([observation.astype(np.float32)]))
observation, reward, done, info = env.step(action)第二部分:策略梯度
目标
maximize E[R|πθ]方法
收集以往的实验数据更新策略使好的实验概率更大
与DQN的不同
我们不考虑单个转换(s,a,r,s’),我们使用整局游戏来更新梯度我们的参数直接参与策略的建模,在DQN中是参与值函数的建模
得分
记住,我们依然是每单位时间的1分问题:一般来说,我们不知道哪个动作有利于我们持续游戏,哪个动作会导致游戏失败。我们的简单想法:游戏开始时的动作是好的,游戏结束时的动作可能不好,因为他导致游戏失败。
def discount_rewards(r, gamma=0.999): """Take 1D float array of rewards and compute discounted reward """ discounted_r = np.zeros_like(r) running_add = 0 for t in reversed(range(0, r.size)): running_add = running_add * gamma + r[t] discounted_r[t] = running_add return discounted_r discounted_epr = discount_rewards(np.ones(10)) f, ax = plt.subplots(1, figsize=(5,2)) sns.barplot(list(range(10)), discounted_epr, color="steelblue")
我们归一化得分,使得分在一直0附近,gamma控制我们可以获得得分的时间。
discounted_epr_cent = discounted_epr - np.mean(discounted_epr) discounted_epr_norm = discounted_epr_cent/np.std(discounted_epr_cent) f, ax = plt.subplots(1, figsize=(5,2)) sns.barplot(list(range(10)), discounted_epr_norm, color="steelblue")
discounted_epr = discount_rewards(np.ones(10), gamma=0.5) discounted_epr_cent = discounted_epr - np.mean(discounted_epr) discounted_epr_norm = discounted_epr_cent/np.std(discounted_epr_cent) f, ax = plt.subplots(2, figsize=(5,3)) sns.barplot(list(range(10)), discounted_epr, color="steelblue", ax=ax[0]) sns.barplot(list(range(10)), discounted_epr_norm, color="steelblue", ax=ax[1])
创建模型
l1=relu(xW1+b1)l2=l1W2+b2π(a|s)=sigmoid(l2)注意:使用策略梯度方法时,由于使用了sigmoid函数,全连接层的输出值被映射到了0-1之间。
TOTAL_EPISODES = 2000 if isFast else 10000 # input dimensionality D = 4 # number of hidden layer neurons H = 10 observations = C.sequence.input_variable(STATE_COUNT, np.float32, name="obs") W1 = C.parameter(shape=(STATE_COUNT, H), init=C.glorot_uniform(), name="W1") b1 = C.parameter(shape=H, name="b1") layer1 = C.relu(C.times(observations, W1) + b1) W2 = C.parameter(shape=(H, ACTION_COUNT), init=C.glorot_uniform(), name="W2") b2 = C.parameter(shape=ACTION_COUNT, name="b2") score = C.times(layer1, W2) + b2 # Until here it was similar to DQN probability = C.sigmoid(score, name="prob")
策略搜索: 策略搜索的优化可以使用自有梯度实现,也可以使用在使用θ参数化的策略空间(πθ)内计算梯度来实现。 在本教程中,我们使用传统前馈和误差在参数化空间θ内反向传播。所以我们的模型参数:θ={W1,b1,W2,b2},
input_y = C.sequence.input_variable(1, np.float32, name="input_y")
advantages = C.sequence.input_variable(1, np.float32, name="advt")
loss = -C.reduce_mean(C.log(C.square(input_y - probability) + 1e-4) * advantages, axis=0, name='loss')
lr = 0.001
lr_schedule = C.learning_rate_schedule(lr, C.UnitType.sample)
sgd = C.sgd([W1, W2], lr_schedule)
gradBuffer = dict((var.name, np.zeros(shape=var.shape)) for var in loss.parameters if var.name in ['W1', 'W2', 'b1', 'b2'])
xs, hs, label, drs = [], [], [], []
running_reward = None
reward_sum = 0
episode_number = 1
observation = env.reset()
while episode_number <= TOTAL_EPISODES:
x = np.reshape(observation, [1, STATE_COUNT]).astype(np.float32)
# Run the policy network and get an action to take.
prob = probability.eval(arguments={observations: x})[0][0][0]
action = 1 if np.random.uniform() < prob else 0
# observation
xs.append(x)
# grad that encourages the action that was taken to be taken
# a "fake label"
y = 1 if action == 0 else 0
label.append(y)
# step the environment and get new measurements
observation, reward, done, info = env.step(action)
reward_sum += float(reward)
# Record reward (has to be done after we call step() to get reward for previous action)
drs.append(float(reward))
if done:
# Stack together all inputs, hidden states, action gradients, and rewards for this episode
epx = np.vstack(xs)
epl = np.vstack(label).astype(np.float32)
epr = np.vstack(drs).astype(np.float32)
# reset array memory
xs, label, drs = [], [], []
# Compute the discounted reward backwards through time.
discounted_epr = discount_rewards(epr)
# Size the rewards to be unit normal (helps control the gradient estimator variance)
discounted_epr -= np.mean(discounted_epr)
discounted_epr /= np.std(discounted_epr)
# Forward pass
arguments = {observations: epx, input_y: epl, advantages: discounted_epr}
state, outputs_map = loss.forward(arguments, outputs=loss.outputs,
keep_for_backward=loss.outputs)
# Backward psas
root_gradients = {v: np.ones_like(o) for v, o in outputs_map.items()}
vargrads_map = loss.backward(state, root_gradients, variables=set([W1, W2]))
for var, grad in vargrads_map.items():
gradBuffer[var.name] += grad
# Wait for some batches to finish to reduce noise
if episode_number % BATCH_SIZE_BASELINE == 0:
grads = {W1: gradBuffer['W1'].astype(np.float32),
W2: gradBuffer['W2'].astype(np.float32)}
updated = sgd.update(grads, BATCH_SIZE_BASELINE)
# reset the gradBuffer
gradBuffer = dict((var.name, np.zeros(shape=var.shape))
for var in loss.parameters if var.name in ['W1', 'W2', 'b1', 'b2'])
print('Episode: %d. Average reward for episode %f.' % (episode_number, reward_sum / BATCH_SIZE_BASELINE))
if reward_sum / BATCH_SIZE_BASELINE > REWARD_TARGET:
print('Task solved in: %d ' % episode_number)
break
reward_sum = 0
# reset env
observation = env.reset()
episode_number += 1
probability.save('pg.mod')欢迎扫码关注我的微信公众号获取最新文章

相关文章推荐
- CNTK API文档翻译(24)——使用深度迁移学习进行图像识别
- CNTK API文档翻译(20)——GAN处理MSIST数据基础
- CNTK API文档翻译(21)——深度卷积GAN处理MSIST数据基础
- CNTK API文档翻译(2)——逻辑回归
- CNTK API文档翻译(23)——使用CTC标准训练声学模型
- CNTK API文档翻译(17)——多对多神经网络处理文本数据(1)
- CNTK API文档翻译(15)——自然语言理解
- CNTK API文档翻译(5)——对MNIST数据使用逻辑回归
- CNTK API文档翻译(11)——使用LSTM预测时间序列数据(物联网数据)
- CNTK API文档翻译(13)——CIFAR-10数据准备
- CNTK API文档翻译(18)——多对多神经网络处理文本数据(2)
- CNTK API文档翻译(8)——使用Pandas和金融数据进行时序数据基本分析
- CNTK API文档翻译(25)——后记
- CNTK API文档翻译(7)——对MNIST数据使用卷积神经网络
- CNTK API文档翻译(4)——MNIST数据加载
- CNTK API文档翻译(9)——使用自编码器压缩MNIST数据
- CNTK API文档翻译(12)——CNTK进阶
- CNTK API文档翻译(10)——使用LSTM预测时间序列数据
- CNTK API文档翻译(22)——取样Softmax函数
- CNTK API文档翻译(14)——实验图像识别