主题模型TopicModel:LDA的缺陷和改进
2017-08-14 00:00
417 查看
http://blog.csdn.net/pipisorry/article/details/45307369
LDA的缺陷和改进
1. 短文本与LDA
ICML论文有理论分析,文档太短确实不利于训练LDA,但平均长度是10这个数量级应该是可以的,如peacock基于query 训练模型。
有一些经验技巧加工数据,譬如把同一session 的查询拼接,同一个人的twitter 拼接等。也可以用w2v那样的小窗口训练过lda。
短文本上效果不好的原因是document-level word co-occurrences 很稀疏。
解决这个问题的方式:
1. 是如word2vec一样,利用local context-level word co-occurrences。 也就是说,把每个词当成一个文档以及把它周围出现过的词当做这个文档的内容。这样的话就不会受文档长度的限制了。
2. 短文本语义更集中明确,LDA是适合处理的,也可以做一些文本扩展的工作,有query log的话,1. query session,2. clickstream。无query log的话,1. 短文本当做query,通过搜索引擎(或语料库)获取Top相关性网页,2. 用语料库中短文本周边词集,3. 知识库中近义词,上下位词等。
3. KBTM
[http://weibo.com/1991303247/CltoOaSTN?type=repost#_rnd1433930168895]
皮皮blog
2. LDA limitations: what’s next?
Although LDA is a great algorithm for topic-modelling, it still has some limitations, mainly due to the fact that it’s has become popular and available to the mass recently.
One major limitation is perhaps given by its underlying unigram text model: LDA doesn’t consider themutual position of the words in the document. Documents like “Man, I love this can” and “I can love this man” are probably modelled the same way. It’s also true that for longer documents, mismatching topics is harder. To overcome this limitation, at the cost of almost square the complexity, you can use 2-grams (or N-grams)along with 1-gram.
Another weakness of LDA is in the topics composition: they’re overlapping. In fact, you can find thesame word in multiple topics(the example above, of the word “can”, is obvious). The generated topics, therefore, are not independent andorthogonal(正交的) like in a PCA-decomposed basis, for example. This implies that you must pay lots of attention while dealing with them (e.g. don’t usecosine similarity).
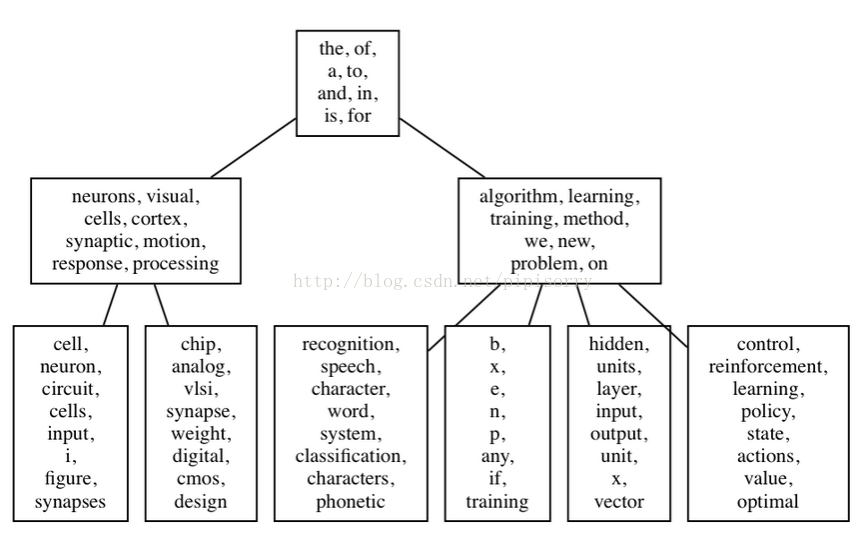
For a more structured approach - especially if the topic composition is very misleading - you might consider thehierarchical variation of LDA, named H-LDA, (or simply Hierarchical LDA). In H-LDA, topics are joined together in a hierarchy by using a Nested Chinese Restaurant Process (NCRP). This model is more complex than LDA, and the description is beyond the goal of this blog entry, but if you like to have an idea of the possible output, here it is. Don’t forget that we’re still in theprobabilistic world: each node of the H-DLA tree is a topic distribution.
[http://engineering.intenthq.com/2015/02/automatic-topic-modelling-with-lda/]
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
[LDA主题模型简介]
3. big data text analysis inconsistent, inaccurate
LDA is also inaccurate enough at some tasks that the results of any topic model created with it are essentially meaningless, according toLuis Amaral.
Applied to messy, inconsistently scrubbed data from many sources in many formats – the base of data for which big data is often praised for its ability to manage – the results would be far less accurate and far less reproducible.
"Our systematic analysis clearly demonstrates that current implementations of LDA have low validity," the paper reports (full text PDFhere).
改进:TopicMapping
1. breaks words down into bases (treating "stars" and "star" as the same word), then eliminates conjunctions, pronouns and other "stop words" that modify the meaning but not the topic, using a standardized list.
2. Then the algorithm builds a model identifying words that often appear together in the same document and use the proprietary Infomap natural-language processing software to assign those clusters of words into groups identified as a "community" that define the topic. Words could appear in more than one topic area.
The new approach delivered results that were 92 percent accurate and 98 percent reproducible, though, according to the paper, it only moderately improved the likelihood that any given result would be accurate.
The best way to improve those analyses is to apply techniques common in community detection algorithms – which identify connections among specific variables and use those to help categorize or verify the classification of those that aren't clearly in one group or another.
[Test shows big data text analysis inconsistent, inaccurate]
皮皮blog
[Spark MLlib LDA 基于GraphX实现原理及源码分析]
基于GraphX实现的Gibbs Sampling LDA,定义文档与词的二部图,顶点属性为文档或词所对应的topic向量计数,边属性为Gibbs Sampler采样生成的新一轮topic。每一轮迭代采样生成topic,用mapReduceTriplets函数为文档或词累加对应topic计数。这好像是Pregel的处理方式?Pregel实现过LDA。
[基于GraphX实现的Gibbs Sampling LDA]
[Collapsed Gibbs Sampling for LDA]
[LDA中Gibbs采样算法和并行化]
from:http://blog.csdn.net/pipisorry/article/details/45307369
ref:
LDA的缺陷和改进
1. 短文本与LDA
ICML论文有理论分析,文档太短确实不利于训练LDA,但平均长度是10这个数量级应该是可以的,如peacock基于query 训练模型。
有一些经验技巧加工数据,譬如把同一session 的查询拼接,同一个人的twitter 拼接等。也可以用w2v那样的小窗口训练过lda。
短文本上效果不好的原因是document-level word co-occurrences 很稀疏。
解决这个问题的方式:
1. 是如word2vec一样,利用local context-level word co-occurrences。 也就是说,把每个词当成一个文档以及把它周围出现过的词当做这个文档的内容。这样的话就不会受文档长度的限制了。
2. 短文本语义更集中明确,LDA是适合处理的,也可以做一些文本扩展的工作,有query log的话,1. query session,2. clickstream。无query log的话,1. 短文本当做query,通过搜索引擎(或语料库)获取Top相关性网页,2. 用语料库中短文本周边词集,3. 知识库中近义词,上下位词等。
3. KBTM
[http://weibo.com/1991303247/CltoOaSTN?type=repost#_rnd1433930168895]
皮皮blog
2. LDA limitations: what’s next?
Although LDA is a great algorithm for topic-modelling, it still has some limitations, mainly due to the fact that it’s has become popular and available to the mass recently.
One major limitation is perhaps given by its underlying unigram text model: LDA doesn’t consider themutual position of the words in the document. Documents like “Man, I love this can” and “I can love this man” are probably modelled the same way. It’s also true that for longer documents, mismatching topics is harder. To overcome this limitation, at the cost of almost square the complexity, you can use 2-grams (or N-grams)along with 1-gram.
Another weakness of LDA is in the topics composition: they’re overlapping. In fact, you can find thesame word in multiple topics(the example above, of the word “can”, is obvious). The generated topics, therefore, are not independent andorthogonal(正交的) like in a PCA-decomposed basis, for example. This implies that you must pay lots of attention while dealing with them (e.g. don’t usecosine similarity).
For a more structured approach - especially if the topic composition is very misleading - you might consider thehierarchical variation of LDA, named H-LDA, (or simply Hierarchical LDA). In H-LDA, topics are joined together in a hierarchy by using a Nested Chinese Restaurant Process (NCRP). This model is more complex than LDA, and the description is beyond the goal of this blog entry, but if you like to have an idea of the possible output, here it is. Don’t forget that we’re still in theprobabilistic world: each node of the H-DLA tree is a topic distribution.
[http://engineering.intenthq.com/2015/02/automatic-topic-modelling-with-lda/]
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
[LDA主题模型简介]
3. big data text analysis inconsistent, inaccurate
LDA is also inaccurate enough at some tasks that the results of any topic model created with it are essentially meaningless, according toLuis Amaral.
Applied to messy, inconsistently scrubbed data from many sources in many formats – the base of data for which big data is often praised for its ability to manage – the results would be far less accurate and far less reproducible.
"Our systematic analysis clearly demonstrates that current implementations of LDA have low validity," the paper reports (full text PDFhere).
改进:TopicMapping
1. breaks words down into bases (treating "stars" and "star" as the same word), then eliminates conjunctions, pronouns and other "stop words" that modify the meaning but not the topic, using a standardized list.
2. Then the algorithm builds a model identifying words that often appear together in the same document and use the proprietary Infomap natural-language processing software to assign those clusters of words into groups identified as a "community" that define the topic. Words could appear in more than one topic area.
The new approach delivered results that were 92 percent accurate and 98 percent reproducible, though, according to the paper, it only moderately improved the likelihood that any given result would be accurate.
The best way to improve those analyses is to apply techniques common in community detection algorithms – which identify connections among specific variables and use those to help categorize or verify the classification of those that aren't clearly in one group or another.
[Test shows big data text analysis inconsistent, inaccurate]
皮皮blog
LDA并行计算
Spark MLlib LDA 基于GraphX实现原理,以文档到词作为边,以词频作为边数据,把语料库构造成图,把对语料库中每篇文档的每个词操作转化为在图中每条边上的操作,而对边RDD处理是GraphX中最常见的的处理方法。[Spark MLlib LDA 基于GraphX实现原理及源码分析]
基于GraphX实现的Gibbs Sampling LDA,定义文档与词的二部图,顶点属性为文档或词所对应的topic向量计数,边属性为Gibbs Sampler采样生成的新一轮topic。每一轮迭代采样生成topic,用mapReduceTriplets函数为文档或词累加对应topic计数。这好像是Pregel的处理方式?Pregel实现过LDA。
[基于GraphX实现的Gibbs Sampling LDA]
[Collapsed Gibbs Sampling for LDA]
[LDA中Gibbs采样算法和并行化]
from:http://blog.csdn.net/pipisorry/article/details/45307369
ref:

相关文章推荐
- TopicModel主题模型 - LDA的缺陷和改进
- TopicModel主题模型 - LDA的python实现及参数选择
- TopicModel主题模型 - LDA详解
- 主题模型TopicModel:通过gensim实现LDA
- 主题模型TopicModel:通过gensim实现LDA
- 主题模型TopicModel:LDA编程实现
- LDA主题模型
- 主题模型-LDA浅析
- LDA(Latent Dirichlet Allocation)主题模型
- 主题模型 LDA 源码分享
- LDA主题模型
- Spark:聚类算法之LDA主题模型算法
- 用 LDA 做主题模型:当 MLlib 邂逅 GraphX
- LDA 主题模型解析
- 主题模型-LDA浅析
- LDA主题模型代码实现流程
- LDA与主题模型
- 深入浅出讲解LDA主题模型(一)
- LDA(主题模型算法)
- LDA主题模型-方差推断