Python爬虫个人记录(二) 获取fishc 课件下载链接
2017-08-13 14:23
435 查看
这此教程可能会比较简洁,具体细节可参考我的第一篇教程:
Python爬虫个人记录(一)豆瓣250
即这玩意
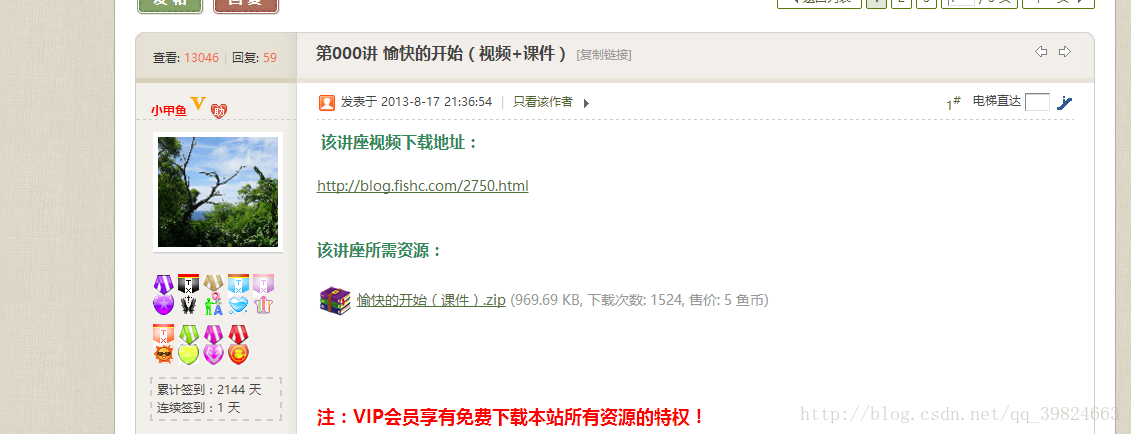
2、通过xpath()分析出一级连接
http://bbs.fishc.com/thread-36353-1-1.html
3、通过xpath()分析出二级下载链接
4、通过二级连接下载课件(失败)
返回200成功
获取需要信息的xpath(记录一有),这里只再演示一次(qq浏览器版本)
鼠标放在所需元素,右键查看元素(或检查),copy xpath
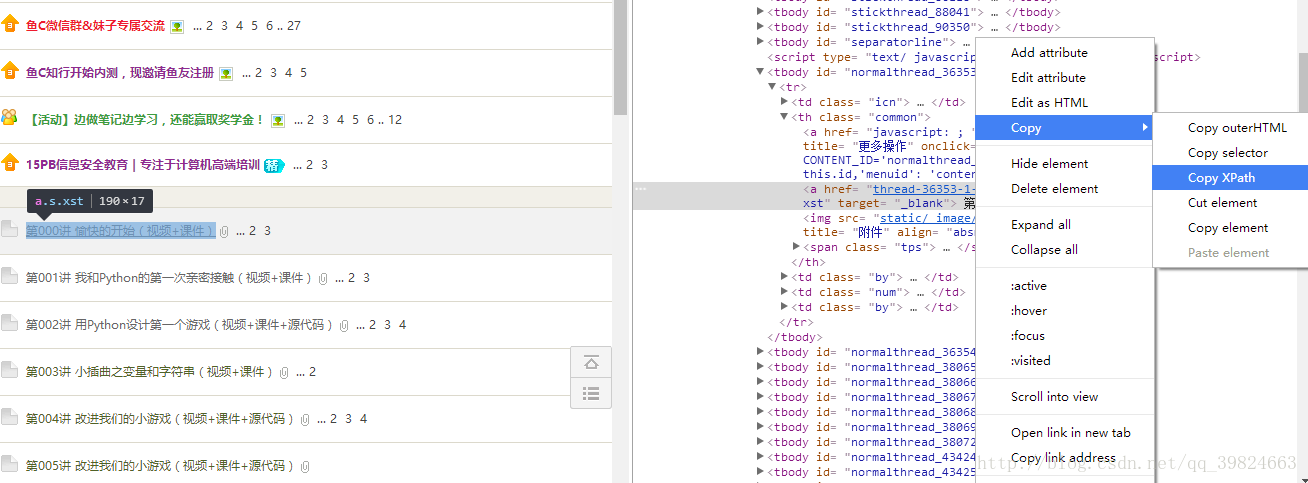
得到 //*[@id=”normalthread_36353”]/tr/th/a[2]
在shell中测试
成功
通过分析网页
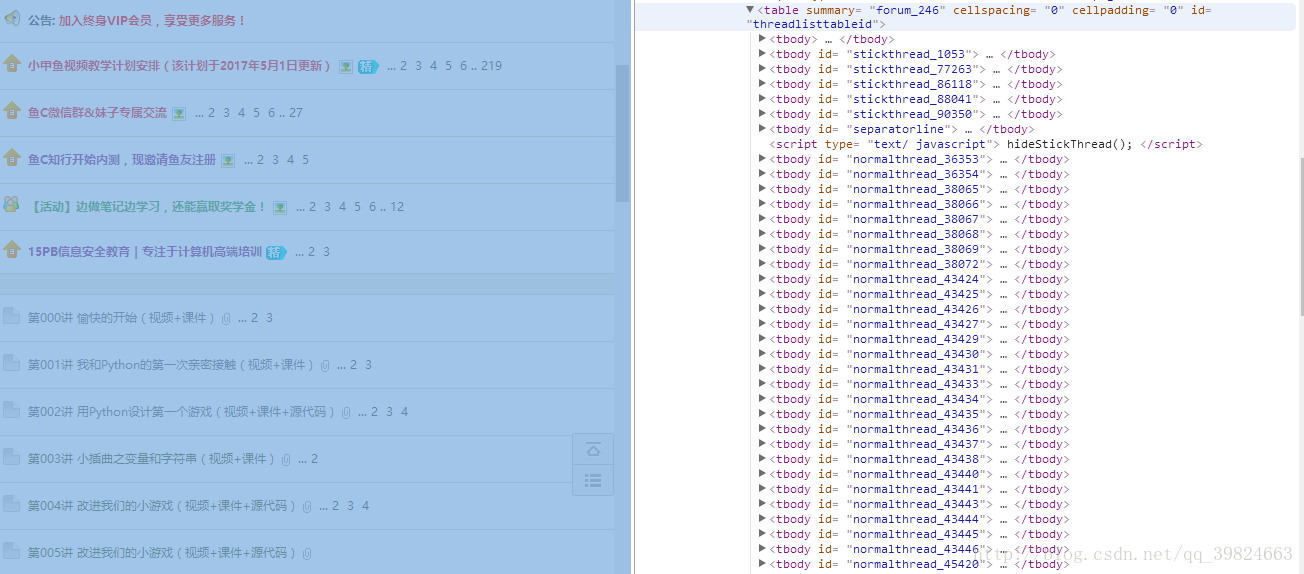
所需要的网页都带有
//*[@id=”normalthread_数字”] 这样的特征
于是修改xpath()使用模糊查询
response.xpath(‘//table/*[contains(@id,“normalthread”)]/tr/th/a[2]’).extract()
成功获取所需要元素,接下来获取相对应地址
同上不难分析出网页连接地址xpath为
“//table/*[contains(@id,’nor’)]/tr/th/a[2]/@href”
至此可以书写python代码了
1、#获取一级链接
2、#获取二级文件下载链接
2、#打开二级文件下载链接,下载文件(这是个坑,会员才能下载。。。所以失败,方法后面使用cookie看能否解决)
直接上源码了,有一些注释,可以自行参考阅读
顺便打波小广告:I love fishc.com
欢迎来鱼c论坛学习^_^零基础入门学习python
Python爬虫个人记录(一)豆瓣250
一、目的分析
获取http://bbs.fishc.com/forum-246-1.html 中小甲鱼零基础入门学习python课件以及源代码即这玩意
二、步骤分析
1、进入http://bbs.fishc.com/forum-246-1.html2、通过xpath()分析出一级连接
http://bbs.fishc.com/thread-36353-1-1.html
3、通过xpath()分析出二级下载链接
4、通过二级连接下载课件(失败)
三、scrapy shell 模拟分析
运行cmd ->scrapy shell
fetch('http://bbs.fishc.com/forum-246-1.html')返回200成功
获取需要信息的xpath(记录一有),这里只再演示一次(qq浏览器版本)
鼠标放在所需元素,右键查看元素(或检查),copy xpath
得到 //*[@id=”normalthread_36353”]/tr/th/a[2]
在shell中测试
>>> response.xpath('//*[@id="normalthread_36353"]/tr/th/a[2]/text()').extract()
['第000讲 愉快的开始(视频+课件)']
>>>成功
通过分析网页
所需要的网页都带有
//*[@id=”normalthread_数字”] 这样的特征
于是修改xpath()使用模糊查询
response.xpath(‘//table/*[contains(@id,“normalthread”)]/tr/th/a[2]’).extract()
>>> response.xpath('//*[@id="normalthread_36353"]/tr/th/a[2]/text()').extract()
['第000讲 愉快的开始(视频+课件)']
>>> response.xpath('//table/*[contains(@id,"normalthread")]/tr/th/a[2]/text()').extract()
['第000讲 愉快的开始(视频+课件)', '第001讲 我和Python的第一次亲密接触(视频+课件)', '第002讲 用Python设计第一个游戏(视频+课件+源代码)', '第003讲 小插曲之变量和字符串(视频+课件)', '第004讲 改进我们的小游戏(视频+课件+源代码)', '第005讲 改进我们的小游戏(视频+课件+源代码)', '第006讲 Pyhon之常用操作符(视频+课件)', '第007讲 了不起的分支和循环01(视频+课件)', '第008讲 了不起的分支和循环02(视频+课件+源代码)', '第009讲 了不起的分支和循环03(视频+课件+源代码)', '第010 讲 列表:一个打了激素的数组(视频+课件)', '第011讲 列表:一个打了激素的数组2(视频+课件)', '第012讲 列表:一个打了激素的数组3(视频+课件)', '第013讲 元组:戴上了枷锁的列表(视频+课件)', '第014讲 字符串:各种奇葩的内置方法(视频+课件)', '第015讲 字符串:格式化(视频+课件)', '第016讲 序列!序列!(视频+课件)', '第017讲 函数:Python的乐高积木(视频+课件+源代码)', '第018讲 函数:灵活即强大(视频+课件)', '第019讲 函数:我的地盘听我的(视频+课件+源代码)', '第020讲 函数: 内嵌函数和闭包(视频+课件)', '第021讲 函数:lambda表达式(视频+课件)', '第022讲 函数:递归是神马(视频+课件+源代码)', '第023讲 递归:这帮坑爹的小兔崽子(视频+课件+源代码)', '第024讲 递归:汉诺塔(视频+课件+源代码)', '第025讲 字典:当索引不好用时(视频+课件)', '第026讲 字典:当索引不好用时2(视频+课件)', '第027讲 集合:在我的世界里,你就是唯一(视频+课件)', '第028讲 文件:因为懂你,所以永恒(视频+课件)', '第029讲 文件:一个任务(视频+课件+源代码)', '第030讲 文件系统 :介绍一个高大上的东西(视频)', '第031讲 永久存储:腌制一缸美味的泡菜(视频+课件+源代码)']
>>>成功获取所需要元素,接下来获取相对应地址
同上不难分析出网页连接地址xpath为
“//table/*[contains(@id,’nor’)]/tr/th/a[2]/@href”
>>> response.xpath("//table/*[contains(@id,'nor')]/tr/th/a[2]/@href").extract()
['thread-36353-1-1.html', 'thread-36354-1-1.html', 'thread-38065-1-1.html', 'thread-38066-1-1.html', 'thread-38067-1-1.html', 'thread-38068-1-1.html', 'thread-38069-1-1.html', 'thread-38072-1-1.html', 'thread-43424-1-1.html', 'thread-43425-1-1.html', 'thread-43426-1-1.html', 'thread-43427-1-1.html', 'thread-43429-1-1.html', 'thread-43430-1-1.html', 'thread-43431-1-1.html', 'thread-43433-1-1.html', 'thread-43434-1-1.html', 'thread-43435-1-1.html', 'thread-43436-1-1.html', 'thread-43437-1-1.html', 'thread-43438-1-1.html', 'thread-43440-1-1.html', 'thread-43441-1-1.html', 'thread-43443-1-1.html', 'thread-43444-1-1.html', 'thread-43445-1-1.html', 'thread-43446-1-1.html', 'thread-45420-1-1.html', 'thread-45421-1-1.html', 'thread-45422-1-1.html', 'thread-48042-1-1.html', 'thread-48043-1-1.html']
>>>至此可以书写python代码了
四、Python代码书写(细节参考记录一)
思路:1、#获取一级链接
2、#获取二级文件下载链接
2、#打开二级文件下载链接,下载文件(这是个坑,会员才能下载。。。所以失败,方法后面使用cookie看能否解决)
import urllib.request
import os
from lxml import etree
#打开一个网页操作
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.
9e84
3226.400 QQBrowser/9.6.11681.400')
response = urllib.request.urlopen(url)
html = response.read()
return html
#保存多个文件
def save(folder, file_url):
i = 0
for each in file_url:
#print(each)
file_name = str(i)
i += 1
with open(file_name, 'w') as f:
file = url_open(each)
f.write(file)
#保存一个文件
def save1():
file_name = 'asd'
with open(file_name, 'w') as f:
f.write()
def find_data(url = '', xrule = ''):
result_data = []
html = url_open(url)
selector = etree.HTML(html)
result_data = selector.xpath(xrule)
return result_data
def test1():
#获取一级链接
list_1 = []
xrule_1 = "//table/*[contains(@id,'nor')]/tr/th/a[2]/@href"
for i in range(1,2):
url = 'http://bbs.fishc.com/forum-246-' + str(i) + '.html'
result_temp = find_data(url, xrule_1)
for each in result_temp:
list_1.append(each)
print('http://bbs.fishc.com/' + each)
#print(list_1)
#获取二级文件下载链接
list_2 = []
xrule_2 = '//*[contains(@id,"attach")]/a/@href'
for each in list_1:
url = 'http://bbs.fishc.com/' + str(each)
result_temp = find_data(url, xrule_2)
for each in result_temp:
list_2.append(each)
print('http://bbs.fishc.com/' + each)
#print(list_2)
if __name__ == '__main__':
test1()直接上源码了,有一些注释,可以自行参考阅读
五、总结
失败的尝试。。原因:还学要学习下载链接原理顺便打波小广告:I love fishc.com
欢迎来鱼c论坛学习^_^零基础入门学习python

相关文章推荐
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
- Python爬虫学习记录(3)——用Python获取虾米加心歌曲,并获取MP3下载地址
- Python多线程爬虫获取电影下载链接
- python爬虫(14)获取淘宝MM个人信息及照片(下)(windows版本)
- Python爬虫学习--获取CSDN个人的访问量
- Python爬虫实战(八):爬取电影天堂的电影下载链接
- 爬虫技术(六)-- 使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)
- python爬虫 分页获取图片并下载
- Python爬虫(4)——获取CSDN链接
- Python爬虫学习--WIN10下定时获取CSDN个人的访问量并保存到文件中2018/01/19
- C++和python如何获取百度搜索结果页面下信息对应的真实链接(百度搜索爬虫,可指定页数)
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
- python爬虫(14)获取淘宝MM个人信息及照片(中)
- Python 爬虫笔记(获取整个站点中的所有外部链接)
- Python爬虫判断url链接的是下载文件还是html文件
- python获取CSDN个人收藏的文章链接和标题,然后发送到指定邮件