【Python3.6爬虫学习记录】(一)爬取简单的静态网页图片
2017-08-11 17:59
856 查看
前言:之前跟着廖雪峰的教程简单的学习了最基本的python语法,还没学完,小学期又认真的学习了java,暑假闲来无事,着手学习python爬虫。开学就大二了,然而还是各种小白(文中会提到很多小白,痴问题)。
千里之行始于足下,百尺高楼起于垒土。
学习计划:跟着网上的教程敲代码,再自己写一个,了解个中奥妙,一个知识点一个知识点的突破,边学边查。
学习Python爬虫的精华摘要
爬虫代码及注释:
相关问题:
①HTML相关知识
之前还准备自学来着,偶然间就发现了谷歌的人性化
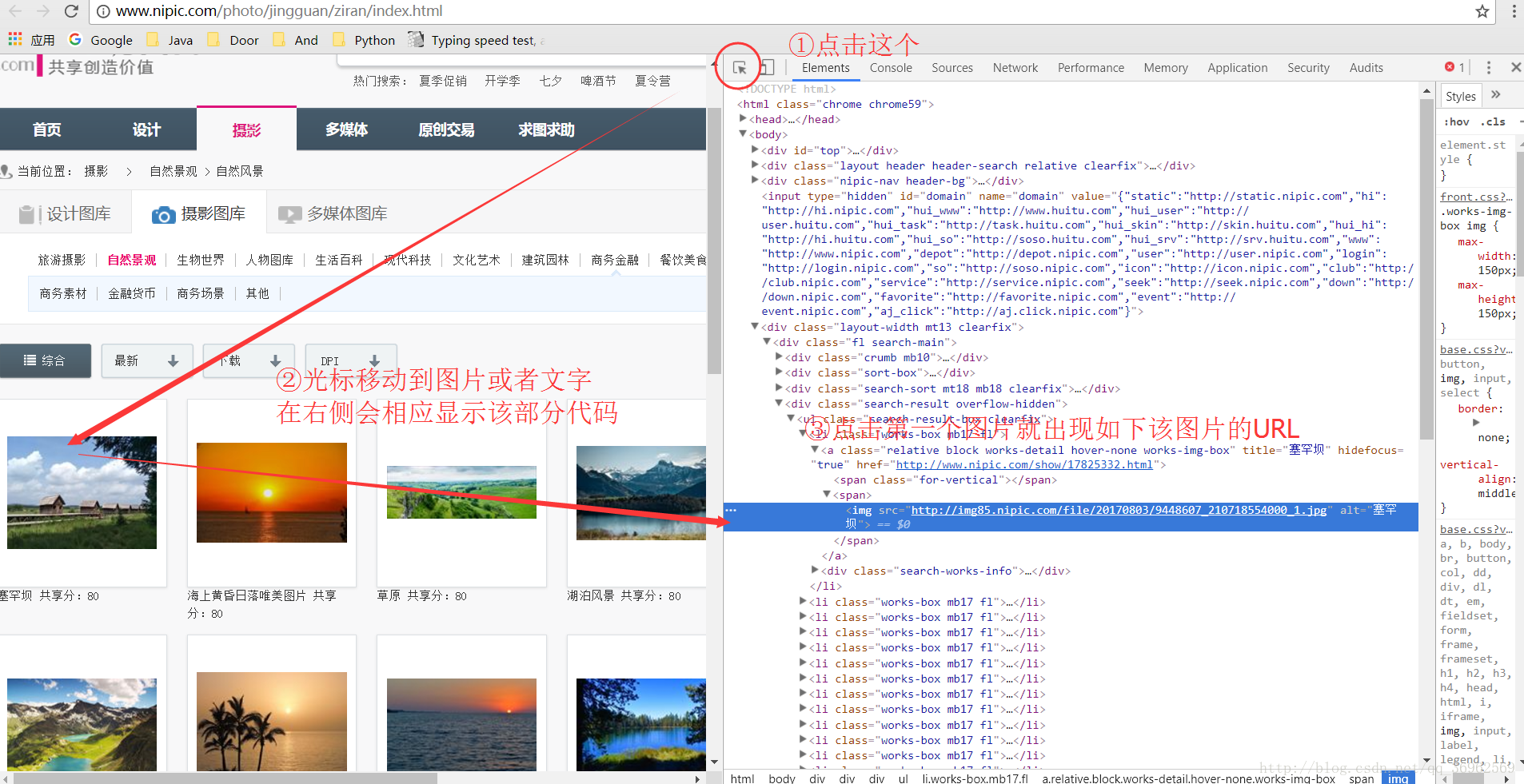
真的很好用。
②静态网页与动态网页的区别
跟着教程临摹,却不知天高地厚的准备爬取花瓣首页的图片,然后遇到了问题。各种百度,终于发现其中奥妙-文章标题。
快速判断静态与动态网页
其中提到的方法如下:
以.asp、.jsp、.php 为扩展名,或者有”?”、”=”、”%”,以及”&”、”$”、”id”等乱七八糟的字符的网页,都是动态页面
html、.htm、.shtml表示的就是静态语言页面
只是小白用来简单的判断,判断网址中有没有上述关键词即可。
③正则表达式
看的实在头疼,静态网页可以用下面简单的表达式吧
④文件读取
之前自学没有学到,这里码一下
千里之行始于足下,百尺高楼起于垒土。
学习计划:跟着网上的教程敲代码,再自己写一个,了解个中奥妙,一个知识点一个知识点的突破,边学边查。
学习Python爬虫的精华摘要
爬虫代码及注释:
#本部分内容-根据指定正则表达式(即图片的网址)匹配
# -以及图片文件保存
import requests
import re
url = 'http://www.nipic.com/photo/jingguan/ziran/index.html'
#获得网页源码
data = requests.get(url).text
#图片正则表达式
regex = r'<img src="(.*?.jpg)"'
#re是一个列表
pa = re.compile(regex) #创建一个pa模板,使其符合匹配的网址
ma = re.findall(pa,data) #findall 方法找到data中所有的符合pa的对象,添加到re中并返回
#图片的名字
i=0
#要在控制台打印提示,了解进程
print('Start downloading')
#将ma中图片网址依次提取出来
for image in ma:
i+=1
image = requests.get(image).content
print(str(i)+'.jpg is downloading')
# \ 要用转义符号 \\表示,要注意原图片的格式
with open('D:\Python Study\crawl\crawl pictures\\'+str(i)+'.jpg','wb') as f: #注意打开的是就jpg文件
f.write(image)
print('Finish downloading')相关问题:
①HTML相关知识
之前还准备自学来着,偶然间就发现了谷歌的人性化
真的很好用。
②静态网页与动态网页的区别
跟着教程临摹,却不知天高地厚的准备爬取花瓣首页的图片,然后遇到了问题。各种百度,终于发现其中奥妙-文章标题。
快速判断静态与动态网页
其中提到的方法如下:
以.asp、.jsp、.php 为扩展名,或者有”?”、”=”、”%”,以及”&”、”$”、”id”等乱七八糟的字符的网页,都是动态页面
html、.htm、.shtml表示的就是静态语言页面
只是小白用来简单的判断,判断网址中有没有上述关键词即可。
③正则表达式
看的实在头疼,静态网页可以用下面简单的表达式吧
regex = r'<img src="(.*?.jpg)"' # .jpg 必须在括号里面才能完整显示图片
④文件读取
之前自学没有学到,这里码一下
#文件读取
try:
# r 表示读取UTF编码的文本文件
# rb 表示读取二进制文件,例如图片和视频
f=open('C:/Users/lenovo/Desktop/execise.txt','r')
print(f.read())
except:
system.exit(0)
finally:
if f:
f.close()
#最后要注意关闭
# 用with更简单,不用写close
#with open('/path/to/file', 'r') as f:
# print(f.read())
#文件写入
with open('C:/Users/lenovo/Desktop/e.txt','w') as f:
f.write('python to write hello world')

相关文章推荐
- 【Python3.6爬虫学习记录】(二)使用BeautifulSoup爬取简单静态网页文章
- 【Python3.6爬虫学习记录】(三)简单的爬虫实践-豆瓣《河神》演员图片及姓名
- 【Python3.6爬虫学习记录】(五)Cookie的使用以及简单的爬取知乎
- Python爬虫学习笔记一:简单网页图片抓取
- 【Python3.6爬虫学习记录】(四)爬取百度贴吧某帖子内容及图片
- 【Python3.6爬虫学习记录】(六)urllib详细使用方法(header,代理,超时,认证,异常处理)
- Python入门简单的静态网页爬虫3.0 (爬虫的示例代码)
- Python入门简单的静态网页爬虫
- 【Python3.6爬虫学习记录】(十四)多线程爬虫模板总结
- Python爬虫实战(三):简单爬取网页图片
- 【Python3.6爬虫学习记录】(八)Selenium模拟登录新浪邮箱并发送邮件
- Python 爬虫学习 网页图片下载
- 【Python3.6爬虫学习记录】(十一)使用代理IP及用多线程测试IP可用性--刷访问量
- python3.6 urllib.request库实现简单的网络爬虫、下载图片
- Python 简单网页爬虫学习
- Python爬虫学习记录(1)——百度贴吧图片下载
- Python 学习(6)---简单的网页爬虫程序
- Python简单爬虫,爬取网页图片