初识 Hadoop
2017-08-10 11:56
183 查看
暑假的前一个月,把大二下学期开始入门的 Java 捡起来,断断续续地勉强学完了基础知识,至少要求的要点在博客中都有体现。不过,真的只是入了个门,实际上并没有打多少 Java 的代码,还不能实际运用起来。大概 Java 就先这样,忘记了也有博客笔记可以查看。接下来大概还有一个月,打算主要做导师布置的看书任务。导师算是很良心了,还给我们布置任务去做,本来导师们也有自己的事情要忙,有的联系之后让学长带带,有的没联系的大概是毕设的时候才会见到吧。大二下学期开学导师分配结果一出来,我就很激动的开始联系,和其他人一起见过之后,就我们布置了任务(至今都还没做完。。。)。一开始是很兴奋,先开始自学 Java,一边也有在看要求的书。然后,不知怎么的就跑偏了,Java 的笔记博客写着写着就没空写了还是怎样具体记不清,暑假捡起来的时上一篇是4月底写的。还有要求我们看的两本书啊,那个《数据挖掘:实用机器学习工具与技术》真的是从入门到放弃,后面的算法的原理是看不懂就跳过,然后就根本停不下来了好么,安慰自己只要会用就好了吧,我是不想再去啃它了。哦对,还要去做做群里的两个实验,写实验报告,玩玩Weka。还有另外一本《Hadoop权威指南》,只要我们看前两章,最近捡回来,打算先看完,到今天已经看完了一章,或说打完了一章?因为感觉只要前两章嘛,而且买了也不一定会去看啊,所以我找的电子版,感觉写博客记录(摘抄)比较有效果,插入截图也很方便,也顺便练练打字哈。第二章貌似又开始讲算法,感到害怕。还有一本暑假要求我们看的《数据算法:Hadoop/Spark大数据处理技巧》,居然又是算法哦,我的天,而且我还没找到中文版的,暑假每天少得可怜的自律(虽然闲的无聊,但想学习的激情也没有很多),希望看得下去。还有一个想法是关于刷题的,总觉得作为一个程序员,刷题绝对是有好处的。不过考虑到可行性的问题,期望的目标是每周去hihoCoder的题库做一题吧,它主要是教你各种的算法啊啥的,一题做下来也是很花时间的,希望能逐渐坚持成一个习惯。这剩下的一个月,还打算学点 Python,主要是入门吧,总感觉会用到,原来是总想玩玩爬虫,感觉很厉害。大概就是去实验楼学吧,因为看到一个“Python 图片转字符画”的小项目,感觉很厉害,学完入门知识可以玩。这样泛而不精好像不大好,但是我也不知道该精些什么,总比烦恼自己要做什么却什么都不做好吧。最后,下面是《Hadoop权威指南》第一章的摘抄,分了好几天来做,打字和效率真是捉急。
现在,我们已经有了大量的数据,必须想方设法好好地存储和分析这些数据。我们不仅需要管理好自己的数据,更需要从其他数据中获取有价值的信息。
对多个硬盘中的数据进行读写数据,主要需要解决两个问题:一是硬件故障问题,二是分析任务很有可能涉及到多个硬盘,比如说从一个硬盘读取的数据可能需要与另外99个硬盘中读取的数据结合使用。
避免数据丢失最常见的方法是复制(replication):系统保存数据的副本(replica),冗余硬盘阵列(RAID)就是这个原理。另外,Hadoop的文件系统(HDFS,Hadoop Distributed FileSystem)也是一类解决方法,详见后文描述。针对第二个问题,各种分布式系统允许结合不同来源的数据进行分析,但保证群殴正确性是一个非常大的挑战。 MapReduce 提出一个编程模型,该模型抽象出这些硬盘读写问题并将其转换为对一个数据集(由键值对组成)的计算。这样的计算由 map 和 reduce 两部分组成而且只有这两部分提供对外的接口。与 HDFS 类似, MapReduce 自身也有很高的可靠性。
简而言之,Hadoop 为我们提供了一个可靠的共享存储和分析系统。HDFS 实现数据的存储,MapReduce 实现数据的分析和处理。虽然 Hadoop 还有其他的功能,但 HDFS 和 MapReduce 是它的核心价值。
关系型数据库管理系统
计算机硬盘的另一个发展趋势:寻址时间的提升远远不敌与传输速率的提升。寻址是将磁头移动到特定硬盘位置进行读写操作的过程。它是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽。所以不能用数据库来对大量硬盘上的大规模数据进行批量分析。RDBMS 和 MapReduce 的比较如下表:
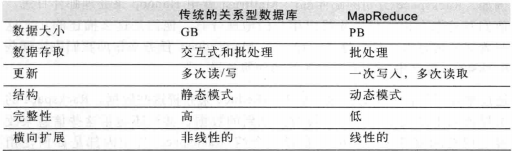
RDBMS 和 MapReduce 之间的另一个区别在于它们所操作的数据集的结构化程度。结构化数据是具有既定格式的实体化数据,这是 RDBMS 包括的内容。半结构化数据比较松散,虽然可能有格式,但经常被忽略,所以它只能作为对数据结构的一般性指导。MapReduce 对非结构化或半结构化数据非常有效,因为它是在处理数据时才对数据进行解释。换句话说,MapReduce 输入的键和值并不是数据固有的属性,而是由分析数据的人来选的。
关系型数据往往是规范的,以保持其数据的完整性且不含冗余。Web 服务器日志是典型的非规范化数据记录(例如,每次都需要记录客户端主机全名,同一客户端的全名可能多次出现),这也是 MapReduce 非常适用于分析各种日志文件的原因之一。
MapReduce 是一种线性的可伸缩编程模型。程序员要写两个函数,分别为 map 函数和 reduce 函数,每个函数定义从一个键值对集合到另一个键值对集合的映射。这些函数不必关注数据集及其所用集群的大小,可以原封不动地应用于小规模数据集或大规模的数据集。更重要的是,如果输入的数据量是原来的两倍,那么运行时间也需要两倍。但如果集群是原来的两倍,作业的运行速度却仍然与原来一样快。SQL 查询一般不具备该特性。
但是,在不久的将来,RDBMS 和 MapReduce 系统之间的差异很可能变得模糊。RDBMS 都开始吸收 MapReduce 的一些思路(如 AsterData 的数据库和 GreenPlum 的数据库),另一方面,基于 MapReduce 的高级查询语言(如 Pig 和 Hive)使传统数据库的程序员更容易接受 MapReduce 系统。
网格计算
高性能计算(High Performance Computing,HPC)和网格计算(Grid Computing)组织多年来一直在研究大规模数据处理,主要使用类似于消息传递接口(Message Passing Interface,MPI)的API。从广义上讲,高性能计算采用的方法是将作业分散到集群的各台机器上,这些机器访问存储区域网络(SAN)所组成的共享文件系统。这比较适用于计算密集型的作业,但如果结点需要访问的数据量更庞大(高达几百 GB,MapReduce 开始施展它的魔法),很多计算结点就会因为网络带宽的瓶颈问题不得不闲下来等数据。
MapReduce 尽量在计算结点上存储数据,以实现数据的本地快速访问。数据本地化(data locality)特性是 MapReduce 的核心特征,并因袭而获得良好的性能。意识到网络带宽是数据中心环境最珍贵的资源(到处复制数据很容易耗尽网络带宽)之后,MapReduce 通过显式网络拓扑结构来保留网络带宽。注意,这种排列方式并没有降低 MapReduce 对计算密集型数据进行分析的能力。
虽然 MPI 赋予程序员很大的控制权,但需要程序员显式控制数据流机制,编程的难度也增加了。而 MapReduce 则在更高层次上执行任务,即程序员仅从键值对函数的角度考虑任务的执行,而且数据流是隐含的。
在大规模分布式计算环境下,协调各个进程的执行是一个很大的挑战。最困难的是合理处理系统的部分失效问题——在不知道一个远程进程是否挂了的情况下——同时采用还需要继续完成整个计算。采用无共享框架的 MapReduce 能够实现失败检测,各个任务之间是彼此独立的。从程序员的角度来看,任务的执行顺序无关紧要。
MapReduce 听起来似乎是一个相当严格的编程模型,它限定用户使用有特定关联的键值对,mapper 和 reducer 彼此间的协调非常有限(每个 mapper 将键值对传给 reducer)。它的灵感来自于传统的函数式编程、分布式计算和数据库社区。但确实能用这个编程模型做一些有用或实际的事情,有很多算法都可以用 MapReduce 来表达。虽然它不能解决所有的问题,但它真的是一个很通用的数据处理工具。
志愿计算
SETI全称为Search for EXtra-Terrestrial Intelligence(搜索外星智能),项目名称为“SETI@home”。在搞项目中,志愿者把自己计算机 CPU 的空闲时间贡献出来分析无线天文望远镜的数据,借此寻找外星智慧生命信号。
志愿计算项目将问题分成很多块,每一块称为一个工作单元(work unit),发到世界各地的计算机上进行分析。为了防止欺骗,每个工作单元要发送到3台不同的机器上执行,而且收到的结果中至少有两个相同才会被接受。
“SETI@home”问题是 CPU 高度密集的,比较适合在全球成千上万台计算机上运行,因为计算所花的时间远远超过工作单元数据的传输时间。也就是说,志愿者贡献的是 CPU 周期,而不是网络带宽。
MapReduce 有三大设计目标:(1)位只需要短短几分钟或几个小时就可以完成的作业提供服务;(2)运行与同一个内部有告诉网络连接的数据中心内;(3)数据中心内的计算机都是可靠的、定制的硬件。相比之下,“SETI@home”则是在接入互联网的不可信的计算机上长时间运行,这些计算机的网络带宽不同,对数据本地化也没有要求。
Hadoop 不是缩写,它是一个生造出来的词,Hadoop 之父 Doug Cutting 这样解释 Hadoop 的来历:“这个名字是我的小孩给他得毛绒象玩具取的。我的命名标准是好拼读,含义宽泛,不会被用于其他地方。小孩子是这方面的高手。Googol 就是小孩子起的名字。” Hadoop 的子项目及后续模块所使用的名称也往往与其功能不相关,通常也以大象或其他动物为主题取名(例如 Pig)。
Nutch 项目开始于 2002 年,一个可以运行的网页爬取工具和搜索引擎系统很快面世。但开发者认为这一框架的灵活性不够,不足以解决数十亿网页的搜索问题。一篇发表于 2003 年的论文为此提供了帮助,文中描述的是谷歌的产品架构——“谷歌分布式文件系统”,简称 GFS 。GFS 或类似的架构,可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。特别关键的是,GFS 能够节省系统管理(如管理存储节点)所花的大量时间。在 2004 年,他们开始着手做开源版本的实现,即 Nutch 分布式文件系统(NDFS)。
2004 年,谷歌发表论文向世界介绍他们的 MapReduce 系统。2005 年初, Nutch 的开发人员在 Nutch 上显示了一个 MapReduce 系统,到年中,Nutcu 的所有主要算法均完成移植,用 MapReduce 和 NDFS 来运行。
Nutch 的 NDFS 和 MapReduce 实现不止适用于搜索领域。在 2006 年 2 月,开发人员将 NDFS 和 MapReduce 移出 Nutch 形成 Lucene 的一个子项目,命名为 Hadoop。大约在同一时间,Doug Cutting 加入雅虎,雅虎为此组织了专门的团队和资源,将 Hadoop 发展成能够处理 Web 数据的系统。2008 年 1 月,Hadoop 已成为 Apache 的顶级项目,证明了它的成功、多样化和生命力。到目前为止,处雅虎之外,还有很多公司在用 Hadoop。
随着 Hadoop 生态系统的成长,新出现的项目越来越多,其中不乏一些非 Apache 主管的项目,这些项目对 Hadoop 是很好的补充或提供一些更高层的抽象。
简单提一下一些 Hadoop 项目:
MapReduce :分布式数据处理模型和执行环境,运行于大型商用机集群
HDFS:分布式文件系统,运行于大型商用机集群
Pig:数据流语言和运行环境,用以探究非常庞大的数据集。Pig 运行在 MapReduce和 HDFS 集群上。
Hive:一种分布式的、按列存储的数据仓库。Hive 管理 HDFS 中存储的数据,并提供基于 SQL 的查询语言(由运行时引擎翻译成 MapReduce 作业)用以查询数据。
数据!数据!
我们生活在数据大爆炸的时代,难以估算全球电子设备中存储的数据总量。有一种更普遍的情况是,个人产生的数据正快速增长。更重要的是,计算机产生的数据可能远远超过我们个人所产生的。在网上公开发布的数据也在逐年增加。现在,我们已经有了大量的数据,必须想方设法好好地存储和分析这些数据。我们不仅需要管理好自己的数据,更需要从其他数据中获取有价值的信息。
数据的存储与分析
在硬盘存储容量多年来不断提升的同时,访问速度(硬盘数据读取速度)却没有与时俱进。一个很简单的减少读取时间的办法是同时从多个硬盘上读数据。对多个硬盘中的数据进行读写数据,主要需要解决两个问题:一是硬件故障问题,二是分析任务很有可能涉及到多个硬盘,比如说从一个硬盘读取的数据可能需要与另外99个硬盘中读取的数据结合使用。
避免数据丢失最常见的方法是复制(replication):系统保存数据的副本(replica),冗余硬盘阵列(RAID)就是这个原理。另外,Hadoop的文件系统(HDFS,Hadoop Distributed FileSystem)也是一类解决方法,详见后文描述。针对第二个问题,各种分布式系统允许结合不同来源的数据进行分析,但保证群殴正确性是一个非常大的挑战。 MapReduce 提出一个编程模型,该模型抽象出这些硬盘读写问题并将其转换为对一个数据集(由键值对组成)的计算。这样的计算由 map 和 reduce 两部分组成而且只有这两部分提供对外的接口。与 HDFS 类似, MapReduce 自身也有很高的可靠性。
简而言之,Hadoop 为我们提供了一个可靠的共享存储和分析系统。HDFS 实现数据的存储,MapReduce 实现数据的分析和处理。虽然 Hadoop 还有其他的功能,但 HDFS 和 MapReduce 是它的核心价值。
相较于其他系统的优势
MapReduce 看似采用了一种蛮力方法。每个查询需要处理整个数据集或至少一个数据集的绝大部分。但反过来想,这也正是它的能力。MapReduce 是一个批量查询处理器,能够在合理的时间范围内处理针对整个数据集的动态查询。关系型数据库管理系统
计算机硬盘的另一个发展趋势:寻址时间的提升远远不敌与传输速率的提升。寻址是将磁头移动到特定硬盘位置进行读写操作的过程。它是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽。所以不能用数据库来对大量硬盘上的大规模数据进行批量分析。RDBMS 和 MapReduce 的比较如下表:
RDBMS 和 MapReduce 之间的另一个区别在于它们所操作的数据集的结构化程度。结构化数据是具有既定格式的实体化数据,这是 RDBMS 包括的内容。半结构化数据比较松散,虽然可能有格式,但经常被忽略,所以它只能作为对数据结构的一般性指导。MapReduce 对非结构化或半结构化数据非常有效,因为它是在处理数据时才对数据进行解释。换句话说,MapReduce 输入的键和值并不是数据固有的属性,而是由分析数据的人来选的。
关系型数据往往是规范的,以保持其数据的完整性且不含冗余。Web 服务器日志是典型的非规范化数据记录(例如,每次都需要记录客户端主机全名,同一客户端的全名可能多次出现),这也是 MapReduce 非常适用于分析各种日志文件的原因之一。
MapReduce 是一种线性的可伸缩编程模型。程序员要写两个函数,分别为 map 函数和 reduce 函数,每个函数定义从一个键值对集合到另一个键值对集合的映射。这些函数不必关注数据集及其所用集群的大小,可以原封不动地应用于小规模数据集或大规模的数据集。更重要的是,如果输入的数据量是原来的两倍,那么运行时间也需要两倍。但如果集群是原来的两倍,作业的运行速度却仍然与原来一样快。SQL 查询一般不具备该特性。
但是,在不久的将来,RDBMS 和 MapReduce 系统之间的差异很可能变得模糊。RDBMS 都开始吸收 MapReduce 的一些思路(如 AsterData 的数据库和 GreenPlum 的数据库),另一方面,基于 MapReduce 的高级查询语言(如 Pig 和 Hive)使传统数据库的程序员更容易接受 MapReduce 系统。
网格计算
高性能计算(High Performance Computing,HPC)和网格计算(Grid Computing)组织多年来一直在研究大规模数据处理,主要使用类似于消息传递接口(Message Passing Interface,MPI)的API。从广义上讲,高性能计算采用的方法是将作业分散到集群的各台机器上,这些机器访问存储区域网络(SAN)所组成的共享文件系统。这比较适用于计算密集型的作业,但如果结点需要访问的数据量更庞大(高达几百 GB,MapReduce 开始施展它的魔法),很多计算结点就会因为网络带宽的瓶颈问题不得不闲下来等数据。
MapReduce 尽量在计算结点上存储数据,以实现数据的本地快速访问。数据本地化(data locality)特性是 MapReduce 的核心特征,并因袭而获得良好的性能。意识到网络带宽是数据中心环境最珍贵的资源(到处复制数据很容易耗尽网络带宽)之后,MapReduce 通过显式网络拓扑结构来保留网络带宽。注意,这种排列方式并没有降低 MapReduce 对计算密集型数据进行分析的能力。
虽然 MPI 赋予程序员很大的控制权,但需要程序员显式控制数据流机制,编程的难度也增加了。而 MapReduce 则在更高层次上执行任务,即程序员仅从键值对函数的角度考虑任务的执行,而且数据流是隐含的。
在大规模分布式计算环境下,协调各个进程的执行是一个很大的挑战。最困难的是合理处理系统的部分失效问题——在不知道一个远程进程是否挂了的情况下——同时采用还需要继续完成整个计算。采用无共享框架的 MapReduce 能够实现失败检测,各个任务之间是彼此独立的。从程序员的角度来看,任务的执行顺序无关紧要。
MapReduce 听起来似乎是一个相当严格的编程模型,它限定用户使用有特定关联的键值对,mapper 和 reducer 彼此间的协调非常有限(每个 mapper 将键值对传给 reducer)。它的灵感来自于传统的函数式编程、分布式计算和数据库社区。但确实能用这个编程模型做一些有用或实际的事情,有很多算法都可以用 MapReduce 来表达。虽然它不能解决所有的问题,但它真的是一个很通用的数据处理工具。
志愿计算
SETI全称为Search for EXtra-Terrestrial Intelligence(搜索外星智能),项目名称为“SETI@home”。在搞项目中,志愿者把自己计算机 CPU 的空闲时间贡献出来分析无线天文望远镜的数据,借此寻找外星智慧生命信号。
志愿计算项目将问题分成很多块,每一块称为一个工作单元(work unit),发到世界各地的计算机上进行分析。为了防止欺骗,每个工作单元要发送到3台不同的机器上执行,而且收到的结果中至少有两个相同才会被接受。
“SETI@home”问题是 CPU 高度密集的,比较适合在全球成千上万台计算机上运行,因为计算所花的时间远远超过工作单元数据的传输时间。也就是说,志愿者贡献的是 CPU 周期,而不是网络带宽。
MapReduce 有三大设计目标:(1)位只需要短短几分钟或几个小时就可以完成的作业提供服务;(2)运行与同一个内部有告诉网络连接的数据中心内;(3)数据中心内的计算机都是可靠的、定制的硬件。相比之下,“SETI@home”则是在接入互联网的不可信的计算机上长时间运行,这些计算机的网络带宽不同,对数据本地化也没有要求。
Hadoop发展简史
Hadoop 是 Apache Lucene 创始人 Doug Cutting 创建的,Lucene 是一个应用广泛的文本搜索系统库。Hadoop 起源于开源的网络搜索引擎 Apache Nutch,它本身也是 Lucene 项目的一部分。Hadoop 不是缩写,它是一个生造出来的词,Hadoop 之父 Doug Cutting 这样解释 Hadoop 的来历:“这个名字是我的小孩给他得毛绒象玩具取的。我的命名标准是好拼读,含义宽泛,不会被用于其他地方。小孩子是这方面的高手。Googol 就是小孩子起的名字。” Hadoop 的子项目及后续模块所使用的名称也往往与其功能不相关,通常也以大象或其他动物为主题取名(例如 Pig)。
Nutch 项目开始于 2002 年,一个可以运行的网页爬取工具和搜索引擎系统很快面世。但开发者认为这一框架的灵活性不够,不足以解决数十亿网页的搜索问题。一篇发表于 2003 年的论文为此提供了帮助,文中描述的是谷歌的产品架构——“谷歌分布式文件系统”,简称 GFS 。GFS 或类似的架构,可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。特别关键的是,GFS 能够节省系统管理(如管理存储节点)所花的大量时间。在 2004 年,他们开始着手做开源版本的实现,即 Nutch 分布式文件系统(NDFS)。
2004 年,谷歌发表论文向世界介绍他们的 MapReduce 系统。2005 年初, Nutch 的开发人员在 Nutch 上显示了一个 MapReduce 系统,到年中,Nutcu 的所有主要算法均完成移植,用 MapReduce 和 NDFS 来运行。
Nutch 的 NDFS 和 MapReduce 实现不止适用于搜索领域。在 2006 年 2 月,开发人员将 NDFS 和 MapReduce 移出 Nutch 形成 Lucene 的一个子项目,命名为 Hadoop。大约在同一时间,Doug Cutting 加入雅虎,雅虎为此组织了专门的团队和资源,将 Hadoop 发展成能够处理 Web 数据的系统。2008 年 1 月,Hadoop 已成为 Apache 的顶级项目,证明了它的成功、多样化和生命力。到目前为止,处雅虎之外,还有很多公司在用 Hadoop。
Apache Hadoop 和 Hadoop生态系统
尽管 Hadoop 因 MapReduce 和 HDFS 而出名,但 Hadoop 这个名字也用于泛指一组相关的项目,这些相关的项目都使用这个基础平台进行分布式计算和海量数据处理。随着 Hadoop 生态系统的成长,新出现的项目越来越多,其中不乏一些非 Apache 主管的项目,这些项目对 Hadoop 是很好的补充或提供一些更高层的抽象。
简单提一下一些 Hadoop 项目:
MapReduce :分布式数据处理模型和执行环境,运行于大型商用机集群
HDFS:分布式文件系统,运行于大型商用机集群
Pig:数据流语言和运行环境,用以探究非常庞大的数据集。Pig 运行在 MapReduce和 HDFS 集群上。
Hive:一种分布式的、按列存储的数据仓库。Hive 管理 HDFS 中存储的数据,并提供基于 SQL 的查询语言(由运行时引擎翻译成 MapReduce 作业)用以查询数据。
Hadoop的发行版本

相关文章推荐
- 《Hadoop基础教程》之初识Hadoop
- 初识Hadoop(2)
- 《Hadoop基础教程》之初识Hadoop
- 初识Hadoop
- 初识hadoop
- Hadoop初识--Hadoop单机模式安装和环境配置
- Hadoop权威指南学习笔记_第一章_初识Hadoop
- 初识Hadoop
- hadoop初识之八:NameNode 启动过程和secondaryNameNode 作用
- 初识hadoop
- Hadoop(一)之初识大数据与Hadoop【转载】
- Hadoop学习篇 2 初识 Hadoop
- 初识Hadoop
- 初识Hadoop
- hadoop初识之一-sql on hadoop的框架
- 初识Hadoop(2)
- Hadoop之一 初识Hadoop
- hadoop初识之四:HDFS、Yarn及mapreduce 回顾,配置文件的补充及yarn日志聚集功能配置
- Hadoop初识--Hadoop单机模式安装和环境配置
- hadoop 初识