慕课网《Python遇见数据采集》学习过程笔记【1】(这个视频不适合我,终断)
2017-08-10 06:32
246 查看
一.
二.windows如何安装beautifulsoup4?
打开命令行输入:
pip install beautifulsoup4
pip3 install beautifulsoup4
检查是否安装成功
在命令行中输入python进入python编程环境
再输入from bs4 import BeautifulSoup 看是否报错,如果没有那么安装成功
三.urllib的用法
1urllib可以轻松模拟用户使用浏览器访问网页
2导入urllib库的request模块
from urllib import request
3.请求url
resp=request.urlopen("http://www.baidu.com")
4.使用响应对象输出数据
print(resp.read().decode("utf-8"))
5.模拟真实浏览器
有些浏览器通过判断User-Agent头来判断是否使用爬虫
req=request.Request(url)
req.add_header(key,value) #key就是"User-Agent" value就是按F12查看network User-Agent对应的值
resp=request.urlopen(req)
print(resp.read().decode("utf-8"))
6.如何使用urllib发送一个post请求?
导入urllib库下面的parse 即 from urllib import parse
使用urllencode生成post数据
postData=parse.urllencode([
(key1,val1),
(key2,val2),
(keyn,valn)
])
使用postData对象发送post请求
request.urlopen(req,data=postData.encode("utf-8")) #req是Request类的对象
得到请求状态:resp.status
得到服务器的类型:resp.reason
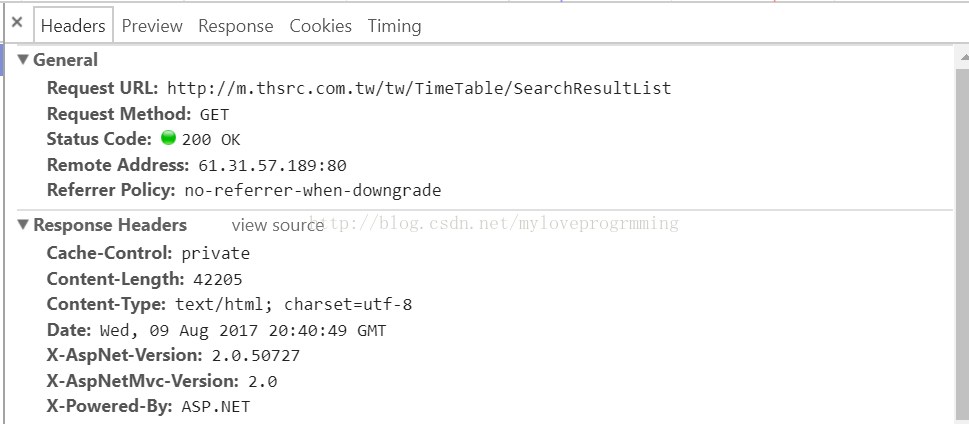
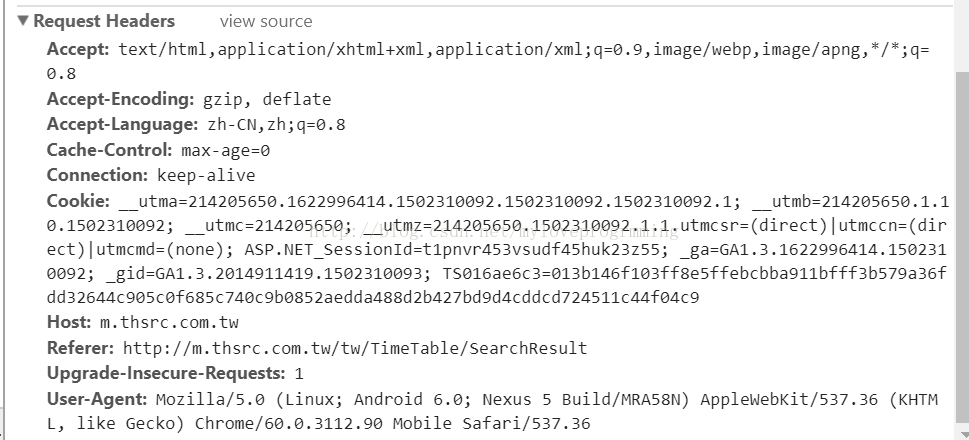
7.通过网站http://m.thsrc.com.tw/tw/TimeTable/SearchResult 学习发送post 请求
打开网站按F12 点击到doc位置(因为如果选择ALL的话网页的所有东西都会加载出来),选择站点,选择查询
得到
8.一个网站检查哪里查看是否为用户访问
第一User-Agent
第二
第三
二.windows如何安装beautifulsoup4?
打开命令行输入:
pip install beautifulsoup4
pip3 install beautifulsoup4
检查是否安装成功
在命令行中输入python进入python编程环境
再输入from bs4 import BeautifulSoup 看是否报错,如果没有那么安装成功
三.urllib的用法
1urllib可以轻松模拟用户使用浏览器访问网页
2导入urllib库的request模块
from urllib import request
3.请求url
resp=request.urlopen("http://www.baidu.com")
4.使用响应对象输出数据
print(resp.read().decode("utf-8"))
5.模拟真实浏览器
有些浏览器通过判断User-Agent头来判断是否使用爬虫
req=request.Request(url)
req.add_header(key,value) #key就是"User-Agent" value就是按F12查看network User-Agent对应的值
resp=request.urlopen(req)
print(resp.read().decode("utf-8"))
from urllib import request
req=request.Request("http://www.baidu.com/")
req.add_header("User-Agent","Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Mobile Safari/537.36")
resp=request.urlopen("http://www.baidu.com")
print(resp.read().decode("utf-8"))6.如何使用urllib发送一个post请求?
导入urllib库下面的parse 即 from urllib import parse
使用urllencode生成post数据
postData=parse.urllencode([
(key1,val1),
(key2,val2),
(keyn,valn)
])
使用postData对象发送post请求
request.urlopen(req,data=postData.encode("utf-8")) #req是Request类的对象
得到请求状态:resp.status
得到服务器的类型:resp.reason
7.通过网站http://m.thsrc.com.tw/tw/TimeTable/SearchResult 学习发送post 请求
打开网站按F12 点击到doc位置(因为如果选择ALL的话网页的所有东西都会加载出来),选择站点,选择查询
得到
8.一个网站检查哪里查看是否为用户访问
第一User-Agent
第二
第三

相关文章推荐
- 慕课网《如何用CSS进行网页布局》视频学习笔记
- Part2:Unity学习笔记十五 - Space Shooter(从视频最后一课向Done_Main.unity场景修改的过程)
- 韩顺平 javascript教学视频_学习笔记9_js函数调用过程内存分析_js函数细节
- Part2:Unity学习笔记十七 - Space Shooter(从视频最后一课向Done_Main.unity场景修改的过程)
- Part2:Unity学习笔记十四 - Space Shooter(从视频最后一课向Done_Main.unity场景修改的过程)
- Part2:Unity学习笔记十六 - Space Shooter(从视频最后一课向Done_Main.unity场景修改的过程)
- SAP BW创建信息立方体创建的基本过程——视频学习笔记
- SAP BW从SAP R3到BW的数据传输过程图释流向理解——视频学习笔记
- Part2:Unity学习笔记十二 - Space Shooter(从视频最后一课向Done_Main.unity场景修改的过程)
- AIX视频学习笔记(现场版)
- AJAX学习笔记--慕课网Ajax
- 黑马程序员——毕向东视频个人学习笔记(一)-基本常识
- JS学习笔记(慕课网)
- ALSA声卡07_分析调用过程_学习笔记
- 韩顺平_php从入门到精通_视频教程_第6讲_浮动窗口_表单及表单控件①_学习笔记_源代码图解_PPT文档整理
- shiro学习笔记——从源码角度分析shiro身份验证过程
- JAVA高级视频_IO输入与输出04 学习笔记
- 【185天】黑马程序员27天视频学习笔记【Day14-下】
- 机器学习经典 PRML 最新 Python 代码实现,附最全 PRML 笔记视频学习资料
- OPENCV2.4学习笔记——用OpenCv创建视频