python小爬虫—获取学校教务处成绩
2017-08-09 21:23
267 查看
开始想自己计算一下绩点,所以第一个小爬虫就从抓取自己成绩开始
1.工具: chrome浏览器 vscode2.先来分析一下学校教务处成绩管理系统的结构,用的竟然是frame标签!!首先是一个输入学号的表单,找到表单后发现是一个post提交
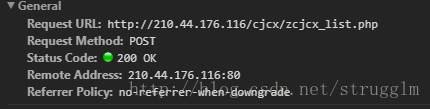
这里是提交的数据
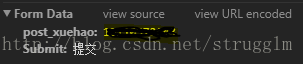
3.找到这些模拟登陆就变得很容易了,下面贴代码
import cgi
import cgitb
import json
import io
import pandas
import requests
from bs4 import BeautifulSoup
import json
form=cgi.FieldStorage()
studentId=form.getvalue('id')
def requestsData(url,headers,data):
r=requests.post(url,headers=headers,data=data)
return r
def htmlParser(r):
soup=BeautifulSoup(r.text,'lxml')
grades=soup.find_all('table')[3]
tr_list=grades.find_all('tr')
td=[tr.find_all('td') for tr in tr_list][1:]
for data in td:
a={"subject_id":data[1].text.lstrip('\xa0'),"subject_name":data[5].text.lstrip('\xa0'),"subject_xf":data[7].text.lstrip('\xa0'),"subject_grade":data[9].text.lstrip('\xa0')}
yield(a)
def fileWrite(data):
for a in data:
with open('file.txt','a',encoding='utf-8') as f:
f.write(json.dumps(a,ensure_ascii=False)+'\n')
f.close()
def main():
url='http://210.44.176.116/cjcx/zcjcx_list.php'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'
}
data={
'post_xuehao':'学号'
}
html=requestsData(url,headers,data)
fileWrite(htmlParser(html))
main()
if __name__ == '__main__':
main()

相关文章推荐
- python 爬虫实战--登陆学校教务系统获取成绩信息
- python3+BeautifulSoup+tkinter 爬虫 获取学校成绩
- python爬虫登录正方教务管理系统获取成绩数据
- [python爬虫]爬取学校教务处以及登录过程验证码的处理
- python爬虫获取强智科技教务系统学科成绩(模拟登录+成绩获取)
- 【Grades Crawler】利用python编写爬虫 爬取西电教务处成绩并本地保存
- python爬虫获取郑大教务在线成绩数据
- python爬虫(11)身边的搜索专家——获取百度搜索结果
- python 3 爬虫获取可用ip地址(小白)
- python爬虫案例——根据网址爬取中文网站,获取标题、子连接、子连接数目、连接描述、中文分词列表
- Python爬虫实例_利用百度地图API批量获取城市所有的POI点
- python爬虫——获取新浪新闻前两页新闻信息
- Python爬虫学习记录(3)——用Python获取虾米加心歌曲,并获取MP3下载地址
- python实现爬虫统计学校BBS男女比例(三)数据处理
- Python实战:Python爬虫学习教程,获取电影排行榜
- Gihub项目分享 —— Python爬虫获取高清桌面壁纸
- Python爬虫_简单获取百度贴吧图片
- python-网络爬虫初学一:获取网页源码以及发送POST和GET请求
- Python多线程爬虫获取电影下载链接