基于特定语料库的TF-IDF关键词提取实现
2017-08-08 17:17
706 查看
本文旨在对特定的语料库生成各词的逆文档频率。然后根据TF-IDF算法进行关键词提取。
转载请注明出处:Gaussic(自然语言处理) 。
GitHub代码:https://github.com/gaussic/tf-idf-keyword
去除其中的一些英文和数字,只保留中文:
基于python生成器的实现,以下代码可以实现高效地读取文本并分词:
计算逆文档频率并存储
逆文档频率(IDF)计算公式
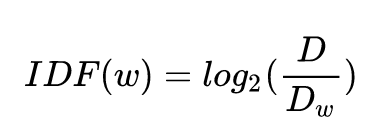
其中,D表示总文档数,Dw表示词w出现在多少篇文档中。
可见,处理1000篇文档用时大约3秒,80万篇大约用时40分钟。
使用TF-IDF抽取关键词:
TF-IDF计算公式:
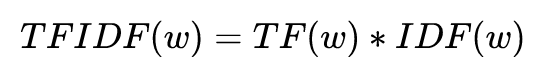
使用:
示例输出:
转载请注明出处:Gaussic(自然语言处理) 。
GitHub代码:https://github.com/gaussic/tf-idf-keyword
分词
对于中文文本的关键词提取,需要先进行分词操作,本文采用全模式的结巴分词器进行分词。使用全模式的一个优势是可以对原始数据进行增益。如果不需要可以将cut_all修改为默认False。去除其中的一些英文和数字,只保留中文:
import jieba
import re
def segment(sentence, cut_all=True):
sentence = re.sub('[a-zA-Z0-9]', '', sentence.replace('\n', '')) # 过滤
return jieba.cut(sentence, cut_all=cut_all) # 分词语料库逆文档频率统计
高效文件读取
读取指定目录下的所有文本文件,使用结巴分词器进行分词。本文的IDF提取基于THUCNews(清华新闻语料库)的大约80万篇文本。基于python生成器的实现,以下代码可以实现高效地读取文本并分词:
class MyDocuments(object): # memory efficient data streaming def __init__(self, dirname): self.dirname = dirname if not os.path.isdir(dirname): print(dirname, '- not a directory!') sys.exit() def __iter__(self): for dirfile in os.walk(self.dirname): for fname in dirfile[2]: text = open(os.path.join(dirfile[0], fname), 'r', encoding='utf-8').read() yield segment(text)
词的逆文档频数统计
统计每一个词出现在多少篇文档中:documents = MyDocuments(inputdir)
# 排除中文标点符号
ignored = {'', ' ', '', '。', ':', ',', ')', '(', '!', '?', '”', '“'}
id_freq = {} # 频数
i = 0 # 总文档数
for doc in documents:
doc = (x for x in doc if x not in ignored)
for x in doc:
id_freq[x] = id_freq.get(x, 0) + 1
if i % 1000 == 0: # 每隔1000篇输出状态
print('Documents processed: ', i, ', time: ',
datetime.datetime.now())
i += 1计算逆文档频率并存储
with open(outputfile, 'w', encoding='utf-8') as f: for key, value in id_freq.items(): f.write(key + ' ' + str(math.log(i / value, 2)) + '\n')
逆文档频率(IDF)计算公式
其中,D表示总文档数,Dw表示词w出现在多少篇文档中。
运行示例:
Building prefix dict from the default dictionary ... Loading model from cache /var/folders/65/1sj9q72d15gg80vt9c70v9d80000gn/T/jieba.cache Loading model cost 0.943 seconds. Prefix dict has been built succesfully. Documents processed: 0 , time: 2017-08-08 17:11:15.906739 Documents processed: 1000 , time: 2017-08-08 17:11:18.857246 Documents processed: 2000 , time: 2017-08-08 17:11:21.762615 Documents processed: 3000 , time: 2017-08-08 17:11:24.534753 Documents processed: 4000 , time: 2017-08-08 17:11:27.235600 Documents processed: 5000 , time: 2017-08-08 17:11:29.974688 Documents processed: 6000 , time: 2017-08-08 17:11:32.818768 Documents processed: 7000 , time: 2017-08-08 17:11:35.797916 Documents processed: 8000 , time: 2017-08-08 17:11:39.232018
可见,处理1000篇文档用时大约3秒,80万篇大约用时40分钟。
TF-IDF关键词提取
借鉴了结巴分词的处理思路,使用IDFLoader载入IDF文件:class IDFLoader(object):
def __init__(self, idf_path):
self.idf_path = idf_path
self.idf_freq = {} # idf
self.mean_idf = 0.0 # 均值
self.load_idf()
def load_idf(self): # 从文件中载入idf
cnt = 0
with open(self.idf_path, 'r', encoding='utf-8') as f:
for line in f:
try:
word, freq = line.strip().split(' ')
cnt += 1
except Exception as e:
pass
self.idf_freq[word] = float(freq)
print('Vocabularies loaded: %d' % cnt)
self.mean_idf = sum(self.idf_freq.values()) / cnt使用TF-IDF抽取关键词:
TF-IDF计算公式:
class TFIDF(object):
def __init__(self, idf_path):
self.idf_loader = IDFLoader(idf_path)
self.idf_freq = self.idf_loader.idf_freq
self.mean_idf = self.idf_loader.mean_idf
def extract_keywords(self, sentence, topK=20): # 提取关键词
# 分词
seg_list = segment(sentence)
freq = {}
for w in seg_list:
freq[w] = freq.get(w, 0.0) + 1.0 # 统计词频
if '' in freq:
del freq['']
total = sum(freq.values()) # 总词数
for k in freq: # 计算 TF-IDF
freq[k] *= self.idf_freq.get(k, self.mean_idf) / total
tags = sorted(freq, key=freq.__getitem__, reverse=True) # 排序
if topK: # 返回topK
return tags[:topK]
else:
return tags使用:
# idffile为idf文件路径, document为待处理文本路径 tdidf = TFIDF(idffile) sentence = open(document, 'r', encoding='utf-8').read() tags = tdidf.extract_keywords(sentence, topK)
示例输出:
交通 翼 路况 中国电信 电信 国电 服务 天 武汉 信息 市民 出行 便民 武汉热线 通路 交通广播 实时 看 分公司 手机

相关文章推荐
- 针对新闻标签提取的tf-idf优化算法1.0版本——基于jieba分词实现
- 利用TF-IDF 提取文章关键词
- TF-IDF关键词提取方法的学习
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF:自动提取关键词
- tf-idf使用-提取文章关键词-搜索文章
- TF-IDF提取关键词并用余弦算法计算相似度
- TF-IDF 提取文本关键词
- 自然语言处理--TF-IDF(关键词提取)
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF自动提取关键词
- TF-IDF算法自动提取关键词
- 【阮一峰】TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF提取关键词
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- TF-IDF与余弦相似性的应用:自动提取关键词
- TF-IDF与余弦相似性的应用(一):自动提取关键词