揭秘Keras推荐系统如何建立模型、获取用户爱好
2017-08-08 14:45
519 查看
你是否有过这样的经历?当你在亚马逊商城浏览一些书籍,或者购买过一些书籍后,你的偏好就会被系统学到,系统会基于一些假设为你推荐相关书目。为什么系统会知道,在这背后又藏着哪些秘密呢?
荐系统可以从百万甚至上亿的内容或商品中把有用的东西高效地显示给用户,这样可以为用户节省很多自行查询的时间,也可以提示用户可能忽略的内容或商品,使用户更有黏性,更愿意花时间待在网站上,从而使商家赚取更多的利润,即使流量本身也会使商家从广告中受益。
那么推荐系统背后的魔术是什么呢?其实任何推荐系统本质上都是在做排序。
你可能注意到了,排序的前提是对喜好的预测。那么喜好的数据从哪里来呢?这里有几个渠道,比如你和产品有过互动,看过亚马逊商城的一些书,或者买过一些书,那么你的偏好就会被系统学到,系统会基于一些假设给你建立画像和构建模型。你和产品的互动越多,数据点就越多,画像就越全面。除此之外,如果你有跨平台的行为,那么各个平台的数据汇总,也可以综合学到你的偏好。比如谷歌搜索、地图和应用商城等都有你和谷歌产品的互动信息,这些平台的数据可以通用,应用的场景有很大的想象力。平台还可以利用第三方数据,比如订阅一些手机运营商的数据,用来多维度刻画用户
那推荐系统又是如何建立模型、知道用户爱好的?作者提供了两种重要的算法:矩阵分解模型和深度模型,快来一起探个究竟吧!
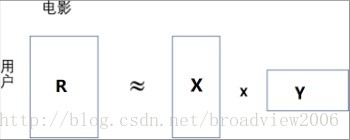
这两种情形都可以用矩阵分解来解决。假设数据库里m 个用户和 n 部电影,那么用户电影矩阵的大小就是 m×n。每个单元 (i,j) 用R ij 表示用户是否看了该电影,即0 或 1。我们把用户和电影用类似 Word2Vec 的方法分别进行向量表示,把每个用户 i 表示成 d 维向量 X i ,把每部电影 j 表示成 d 维向量 Y j 。我们要寻找 X i 和 Y j ,使得 X i ×Y j和用户电影矩阵 R ij 尽可能接近,如图所示。这样对于没出现过的用户电影对,通过 X i ×Y j 的表达式可以预测任意用户对电影的评分值。
用数学表达式可以这么写:
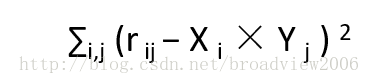
注意:这里d 是一个远小于m; n 的数。从机器学习的角度来说,模型是为了抓住数据的主要特征,去掉噪声。越复杂、越灵活的模型带来的噪声越多,降低维度则可以有效地避免过度拟合现象的出现。
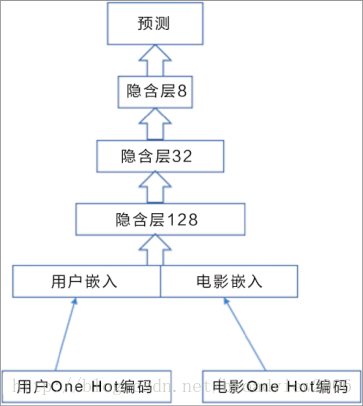
这个模型非常灵活。因为如果有除用户、电影之外的数据,比如用户年龄、地区、电影属性、演员等外在变量,则统统可以加入模型中,用嵌入的思想把它们串在一起,作为输入层,然后在上面搭建各种神经网络模型,最后一层可以用评分等作为输出层,这样的模型可以适用于很多场景。深度模型的的架构如下图所示。
首先,做用户和电影的嵌入层。
第三个小神经网络,在第一、二个网络的基础上把用户和电影向量结合在一起。
然后加入Dropout 和relu 这个非线性变换项,构造多层深度模型。
因为是预测连续变量评分,最后一层直接上线性变化。当然,读者可以尝试分类问
题,用Softmax 去模拟每个评分类别的概率。
将输出层和最后的评分数进行对比,后向传播去更新网络参数。
接下来要给模型输入训练数据。
首先,收集用户索引数据和电影索引数据。
构造训练数据。
然后,用小批量更新权重。
模型训练完以后,预测未给的评分。
最后,对训练集进行误差评估。
训练数据的误差在0.8226 左右,大概一个评分等级不到的误差。
你可能会问,为什么这个误差和之前矩阵分解的浅层模型误差的差距比较大?作者的理解是,这里的Dropout 正则项起了很大的作用。虽然我们建了深层网络,但是由于有了Dropout 这个正则项,必然会造成训练数据的信息丢失(这种丢失会让我们在测试数据时受益)。就好比加了L1, L2 之类的正则项以后,估计的参数就不是无偏的了。因此,Dropout 是训练误差增加的原因,这是设计模型的必然结果。但是,需要记住的是,我们始终要对测试集上的预测做评估,训练集的误差只是看优化方向和算法是否大致有效。
本文选自《Keras快速上手:基于Python的深度学习实战》,点此链接可在博文视点官网查看此书。

想及时获得更多精彩文章,可在微信中搜索“博文视点”或者扫描下方二维码并关注。

荐系统可以从百万甚至上亿的内容或商品中把有用的东西高效地显示给用户,这样可以为用户节省很多自行查询的时间,也可以提示用户可能忽略的内容或商品,使用户更有黏性,更愿意花时间待在网站上,从而使商家赚取更多的利润,即使流量本身也会使商家从广告中受益。
那么推荐系统背后的魔术是什么呢?其实任何推荐系统本质上都是在做排序。
你可能注意到了,排序的前提是对喜好的预测。那么喜好的数据从哪里来呢?这里有几个渠道,比如你和产品有过互动,看过亚马逊商城的一些书,或者买过一些书,那么你的偏好就会被系统学到,系统会基于一些假设给你建立画像和构建模型。你和产品的互动越多,数据点就越多,画像就越全面。除此之外,如果你有跨平台的行为,那么各个平台的数据汇总,也可以综合学到你的偏好。比如谷歌搜索、地图和应用商城等都有你和谷歌产品的互动信息,这些平台的数据可以通用,应用的场景有很大的想象力。平台还可以利用第三方数据,比如订阅一些手机运营商的数据,用来多维度刻画用户
那推荐系统又是如何建立模型、知道用户爱好的?作者提供了两种重要的算法:矩阵分解模型和深度模型,快来一起探个究竟吧!
1.矩阵分解模型
矩阵分解可以认为是一种信息压缩。这里有两种理解。第一种理解,用户和内容不是孤立的,用户喜好有相似性,内容也有相似性。压缩是把用户和内容数量化,压缩成 k 维的向量。把用户向量维度进行压缩,使得向量维度变小,本身就是信息压缩的一种形式;向量之间还可以进行各种计算,比如余弦(Cosine)相似性,就可以数量化向量之间的距离、相似度等。第二种理解,从深度学习的角度,用户表示输入层(User Representation)通常用 One Hot编码,这没问题,但是通过第一层全连接神经网络就可以到达隐藏层,就是所谓的嵌入层(Embedding Layer),也就是我们之前提到的向量压缩过程。紧接着这个隐藏层,再通过一层全连接网络就是最终输入层,通常用来和实际标注数据进行比较,寻找差距,用来更新网络权重。从这个意义上讲,完全可以把整个数据放进神经系统的框架中,通过浅层学习把权重求出来,就是我们要的向量集合了。经过这么分析,矩阵分解在推荐系统中是如何应用的就显而易见了。这两种情形都可以用矩阵分解来解决。假设数据库里m 个用户和 n 部电影,那么用户电影矩阵的大小就是 m×n。每个单元 (i,j) 用R ij 表示用户是否看了该电影,即0 或 1。我们把用户和电影用类似 Word2Vec 的方法分别进行向量表示,把每个用户 i 表示成 d 维向量 X i ,把每部电影 j 表示成 d 维向量 Y j 。我们要寻找 X i 和 Y j ,使得 X i ×Y j和用户电影矩阵 R ij 尽可能接近,如图所示。这样对于没出现过的用户电影对,通过 X i ×Y j 的表达式可以预测任意用户对电影的评分值。
用数学表达式可以这么写:
注意:这里d 是一个远小于m; n 的数。从机器学习的角度来说,模型是为了抓住数据的主要特征,去掉噪声。越复杂、越灵活的模型带来的噪声越多,降低维度则可以有效地避免过度拟合现象的出现。
2.深度神经网络模型
下面展示进阶版的深度模型。我们将建立多层深度学习模型,并且加入 Dropout技术。这个模型非常灵活。因为如果有除用户、电影之外的数据,比如用户年龄、地区、电影属性、演员等外在变量,则统统可以加入模型中,用嵌入的思想把它们串在一起,作为输入层,然后在上面搭建各种神经网络模型,最后一层可以用评分等作为输出层,这样的模型可以适用于很多场景。深度模型的的架构如下图所示。
首先,做用户和电影的嵌入层。
1 k = 128 2 model1 = Sequential() 3 model1.add(Embedding(n_users + 1, k, input_length = 1)) 4 model1.add(Reshape((k,))) 5 model2 = Sequential() 6 model2.add(Embedding(n_movies + 1, k, input_length = 1)) 7 model2.add(Reshape((k,)))
第三个小神经网络,在第一、二个网络的基础上把用户和电影向量结合在一起。
1 model = Sequential() 2 model.add(Merge([model1, model2], mode = 'concat'))
然后加入Dropout 和relu 这个非线性变换项,构造多层深度模型。
1 model.add(Dropout(0.2)) 2 model.add(Dense(k, activation = 'relu')) 3 model.add(Dropout(0.5)) 4 model.add(Dense(int(k/4), activation = 'relu')) 5 model.add(Dropout(0.5)) 6 model.add(Dense(int(k/16), activation = 'relu')) 7 model.add(Dropout(0.5))
因为是预测连续变量评分,最后一层直接上线性变化。当然,读者可以尝试分类问
题,用Softmax 去模拟每个评分类别的概率。
model.add(Dense(1, activation = 'linear'))
将输出层和最后的评分数进行对比,后向传播去更新网络参数。
model.compile(loss = 'mse', optimizer = "adam")
接下来要给模型输入训练数据。
首先,收集用户索引数据和电影索引数据。
1 users = ratings['user_id'].values 2 movies = ratings['movie_id'].values
5 推荐系统
收集评分数据。label = ratings['rating'].values
构造训练数据。
1 X_train = [users, movies] 2 y_train = label
然后,用小批量更新权重。
model.fit(X_train, y_train, batch_size = 100, epochs = 50)
模型训练完以后,预测未给的评分。
1 i,j = 10,99 2 pred = model.predict([np.array([users[i]]), np.array([movies[j]])])
最后,对训练集进行误差评估。
1 sum = 0 2 for i in range(ratings.shape[0]): 3 sum += (ratings['rating'][i] - model.predict([np.array([ratings['user_id' ][i]]), np.array([ratings['movie_id'][i]])])) ** 2 4 mse = math.sqrt(sum/ratings.shape[0]) 5 print(mse)
训练数据的误差在0.8226 左右,大概一个评分等级不到的误差。
你可能会问,为什么这个误差和之前矩阵分解的浅层模型误差的差距比较大?作者的理解是,这里的Dropout 正则项起了很大的作用。虽然我们建了深层网络,但是由于有了Dropout 这个正则项,必然会造成训练数据的信息丢失(这种丢失会让我们在测试数据时受益)。就好比加了L1, L2 之类的正则项以后,估计的参数就不是无偏的了。因此,Dropout 是训练误差增加的原因,这是设计模型的必然结果。但是,需要记住的是,我们始终要对测试集上的预测做评估,训练集的误差只是看优化方向和算法是否大致有效。
本文选自《Keras快速上手:基于Python的深度学习实战》,点此链接可在博文视点官网查看此书。
想及时获得更多精彩文章,可在微信中搜索“博文视点”或者扫描下方二维码并关注。

相关文章推荐
- 你的老婆是怎么算出来的?揭秘佳缘用户推荐系统
- 如何获取系统Home(Launcher)应用判断用户是否处于home界面
- 推荐系统(三) —— 利用用户行为数据 —— 隐语义模型
- 【UWP开发】如何通过UWP获取系统用户Gamertag或者UserName等用户信息
- 多用户linux下安装tensorflow、keras环境;如何在系统自带python和Anaconda间切换
- 如何用C语言获取系统的用户登录名?
- Spark推荐系统中用户-物品模型
- 数据挖掘:用户推荐系统技术深度揭秘
- 如何在Windows窗体中调用系统调色板对话框,并获取用户所选择的颜色?
- 数据挖掘:用户推荐系统技术深度揭秘
- [转]如何从无到有建立推荐系统
- 虚拟机中linux系统下如何建立ftp用户以及破解ftp用户!!
- 【UWP开发】如何通过UWP获取系统用户Gamertag或者UserName等用户信息
- [DevOps] 如何建立新的Linux系统服务(或以其他用户执行)
- 如何构建亿级用户电商平台的推荐系统?
- 如何从无到有建立推荐系统
- 不使用三方包时,如何在社交系统ThinkSNS中建立优雅的用户权限管理【研发日记13】
- 用户兴趣模型分类以及推荐系统技术调研
- 用户兴趣模型分类以及推荐系统技术调研
- iOS开发swift如何调用系统相册和相机获取图片设置用户头像