Hive+Druid 实现快速查询;回归分析是机器学习吗;StructuredStreaming 可用于生产环境
2017-08-06 14:08
483 查看
结合 Apache Hive 和 Druid 实现高速 OLAP 查询

Hadoop 生态中,我们使用 Hive 将 SQL 语句编译为 MapReduce 任务,对海量数据进行操作;Druid 则是一款独立的分布式列式存储系统,通常用于执行面向最终用户的即席查询和实时分析。
Druid 的高速查询主要得益于列式存储和倒排索引,其中倒排索引是和 Hive 的主要区别。数据表中的维度字段越多,查询速度也会越快。不过 Druid 也有其不适用的场景,如无法支持大数据量的 Join 操作,对标准 SQL 的实现也十分有限。
Druid 和 Hive 的结合方式是这样的:首先使用 Hive 对数据进行预处理,生成 OLAP Cube 存入 Druid;当发生查询时,使用 Calcite 优化器进行分析,使用合适的引擎(Hive 或 Druid)执行操作。如,Druid 擅长执行维度汇总、TopN、时间序列查询,而 Hive 则能胜任 Join、子查询、UDF 等操作。
原文:https://dzone.com/articles/ultra-fast-olap-analytics-with-apache-hive-and-dru
回归分析是机器学习吗?
作者认为纠结这个问题的人们其实是“将重点放在了森林而忽视了树木”。我们应该将统计分析和机器学习都用作是实现“理解数据”这一目标的工具。用哪种工具并不重要,如何用好工具、建立恰当的模型、增强对数据的认知,才是最重要的。
过去人们也曾争论过数据挖掘和机器学习的区别。作者认为数据挖掘是一种 过程 ,机器学习则是过程中使用的 工具 。因此,数据挖掘可以总结为 对海量数据进行高效的统计分析 。
机器学习由三个元素组成:数据,模型,成本函数。假设我们有 10 个数据点,使用其中的 9 个来训练模型,最后一个用来测试,这个过程人工就可以解决。那当数据越来越多,或特征值增加,或使用计算机而非人工,是否就由统计学演变成机器学习了呢?所以说,传统统计学和机器学习之间是有一个过渡的,这个过渡过程我们无法衡量,也无需衡量。
原文:http://www.kdnuggets.com/2017/06/regression-analysis-really-machine-learning.html
StructuredStreaming 可用于生产环境
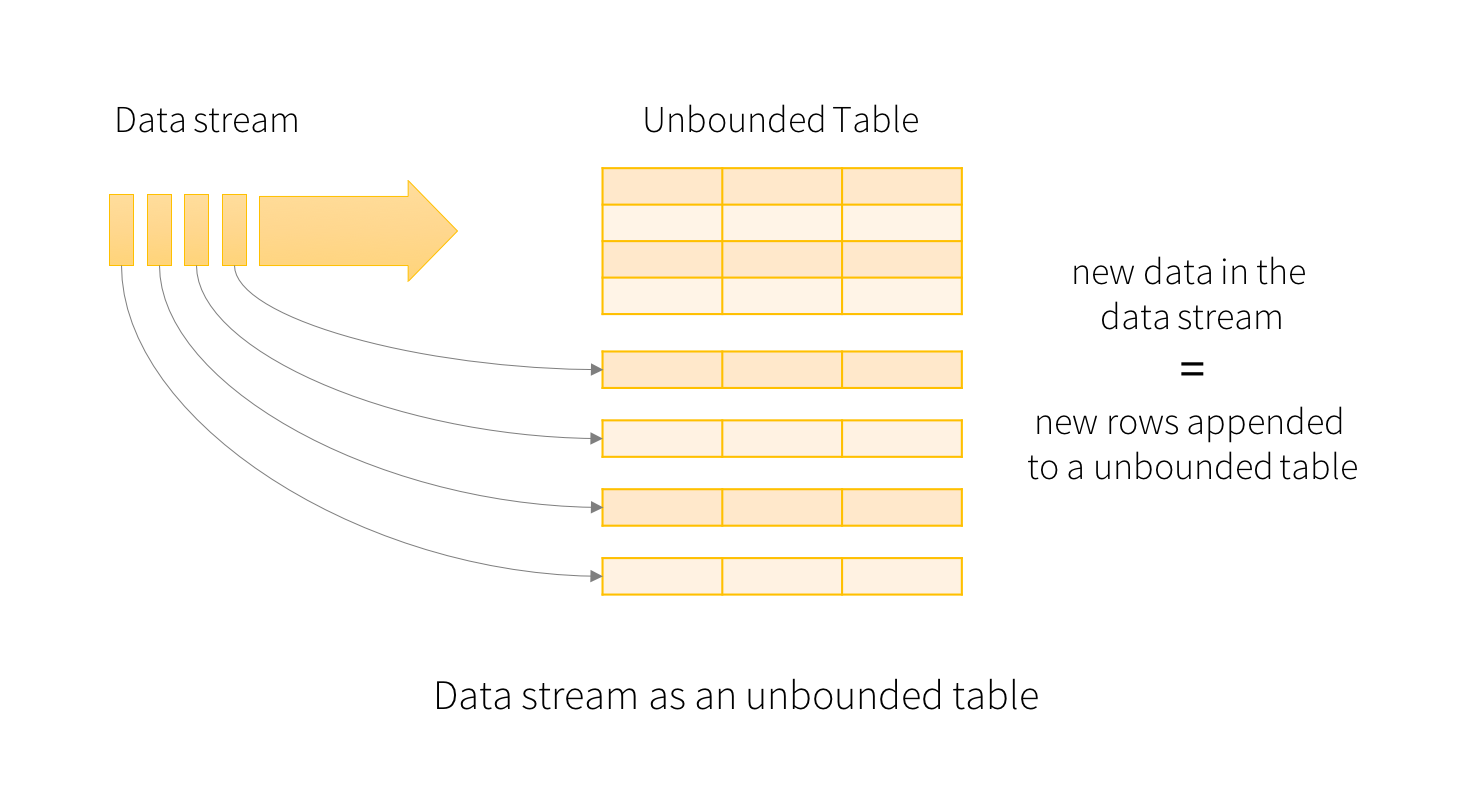
2016 年中,Spark 推出了 StructredStreaming,随着时间的推移,这一创新的实时计算框架也日臻成熟。
实时计算的复杂性在于三个方面:数据来源多样,且存在脏数据、乱序等情况;执行逻辑复杂,需要处理事件时间,结合机器学习等;运行平台也多种多样,需要应对各种系统失效。
StructuredStreaming 构建在 Spark SQL 之上,提供了统一的 API,同时做到高效、可扩、容错。它的理念是 实时计算无需考虑数据是否实时 ,将实时数据流当做一张没有边界的数据表来看待。
传统 ETL 的流程是先将数据导出成文件,再将文件导入到表中使用,这个过程通常以小时计。而实时 ETL 则可以直接从数据源进入到表,过程以秒计。对于更为复杂的实时计算,StructuredStreaming 也提供了相应方案,包括事件时间计算、有状态的聚合算子、水位线等。
原文:https://spark-summit.org/east-2017/events/making-structured-streaming-ready-for-production-updates-and-future-directions/

相关文章推荐
- 8 个用于生产环境的 SQL 查询优化调整
- 发件队列查询perl(用于生产环境)
- 8 个用于生产环境的 SQL 查询优化调整
- Facebook的实时流处理技术——Scuba是Facebook的一个非常快速、分布式的内存数据库,用于实时分析和查询
- 机器学习:以二元决策树为基学习器实现随机森林算法的回归分析
- Spark-1.3.1与Hive整合实现查询分析
- 结合Git实现Mysql差异备份,可用于生产环境
- Spark-1.3.1与Hive整合实现查询分析
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
- 结合Git实现Mysql差异备份,可用于生产环境 推荐
- 想找一个可以用于实际生产环境的Common Lisp实现,您有推荐吗?
- 环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
- Spark-1.3.1与Hive整合实现查询分析
- Spark-1.3.1与Hive整合实现查询分析
- Spark-1.3.1与Hive整合实现查询分析
- WinCE中,环境变量的添加,删除和查询以及BSP的快速编译
- JSP环境基于Session的在线用户统计深入分析,监听器Listener实现用户在线统计
- 数据查询列表展示与分析图形展示的XML定制实现
- bit位快速查询asm实现(find_next_zero_bit)
- 设置环境变量实现使用“运行“快速打开QQ等程序